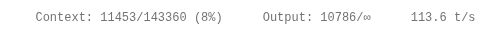Sabitlenmiş Tweet

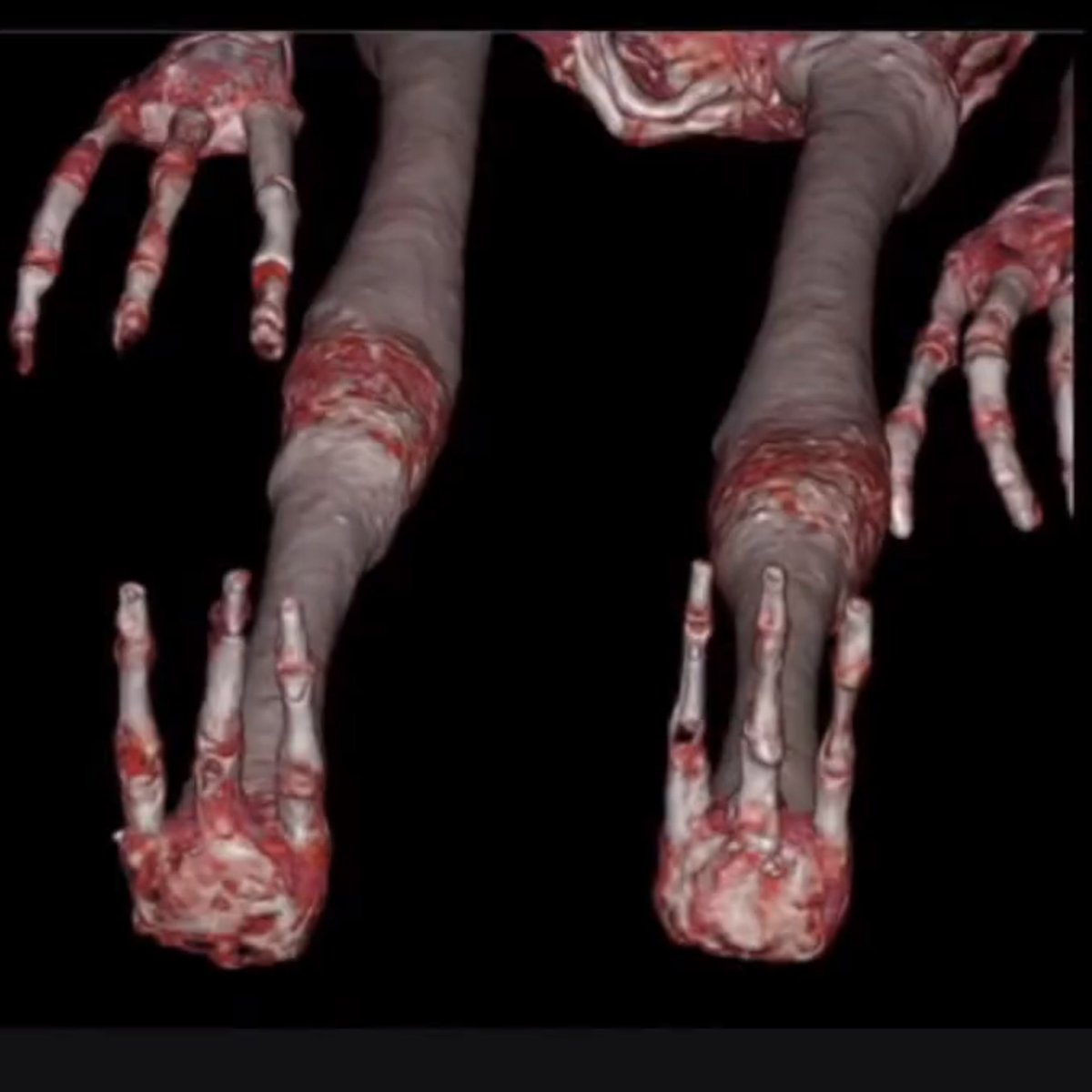
CT imaging results of the alien / E.T. mummies from Mexico / Peru
#UAP #ufotwitter #Aliens [vid talk @QuanticaScience ]



English
kfant
11.3K posts






🚨 The Pentagon says “Immaculate Constellation” doesn’t exist, so it refused to search for emails mentioning it. And that's a huge problem. Here's the story: theblackvault.com/documentarchiv…











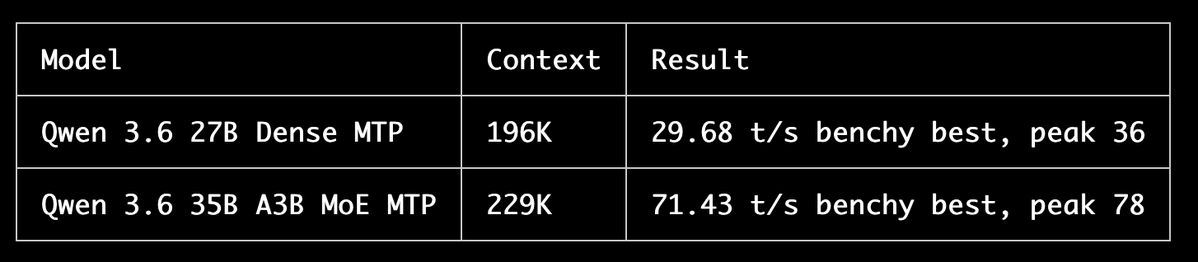


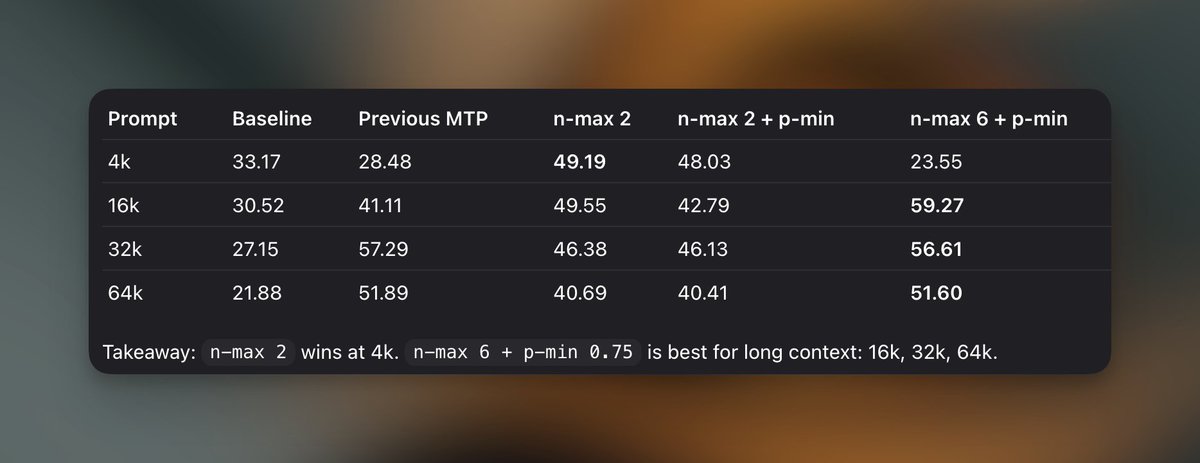
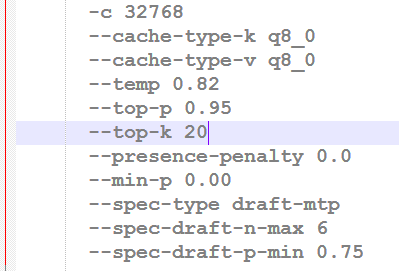
Tested Qwen3.6 27B GGUF vs the new MTP GGUF in llama.cpp on a single RTX 3090. TL;DR: MTP lost at 4k, but won hard at longer context: 16k: 1.35x faster 32k: 2.11x faster 64k: 2.37x faster Tradeoff: slower prefill, and current llama.cpp MTP is cc1/p1 only (for now).