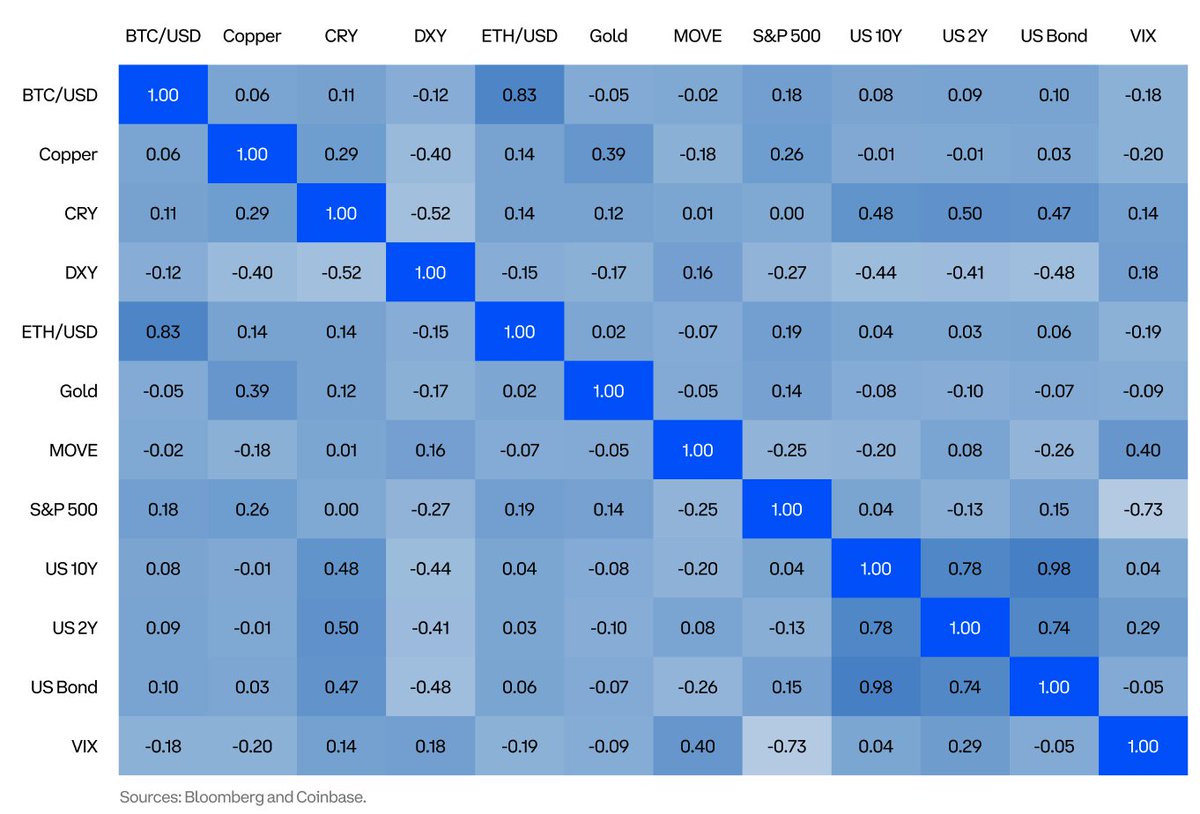
Matt Honea retweetledi

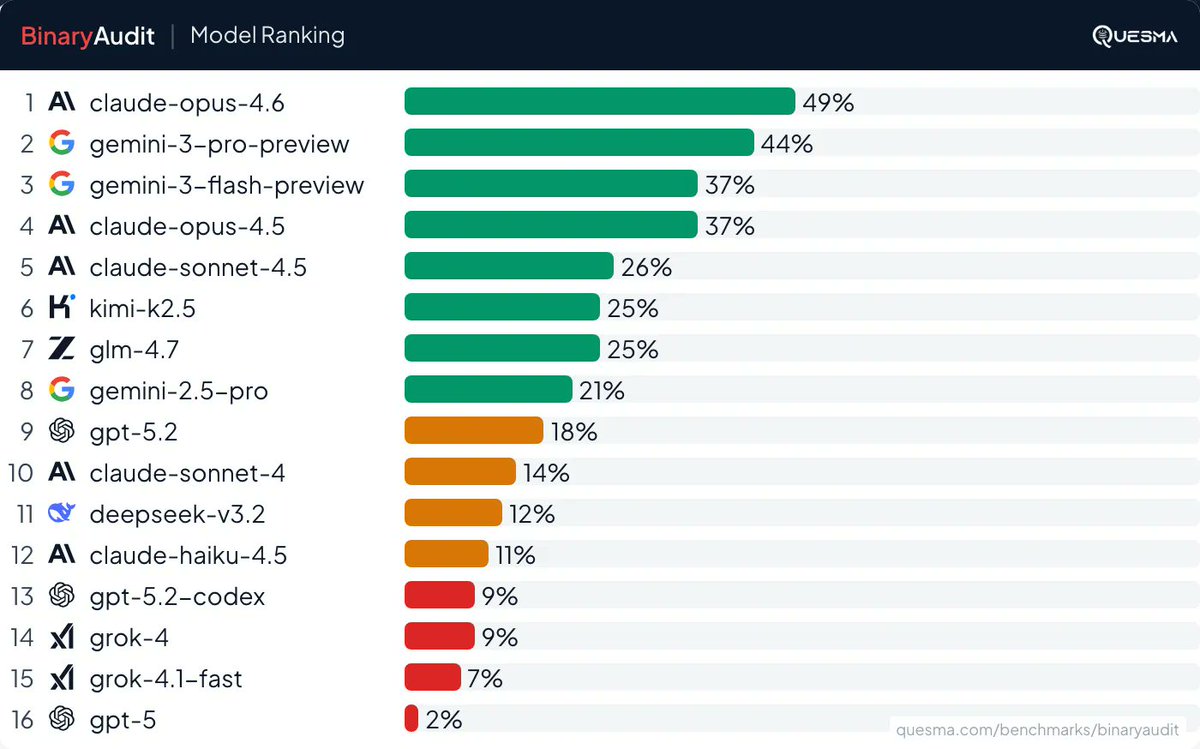
Claude can code, but can it read machine code?
We gave AI agents access to Ghidra (a decompiler by the NSA) and tasked them with finding hidden backdoors in servers - working solely from binaries, without any access to source code.
See our BinaryAudit: quesma.com/blog/introduci…
English