Sarah retweetledi

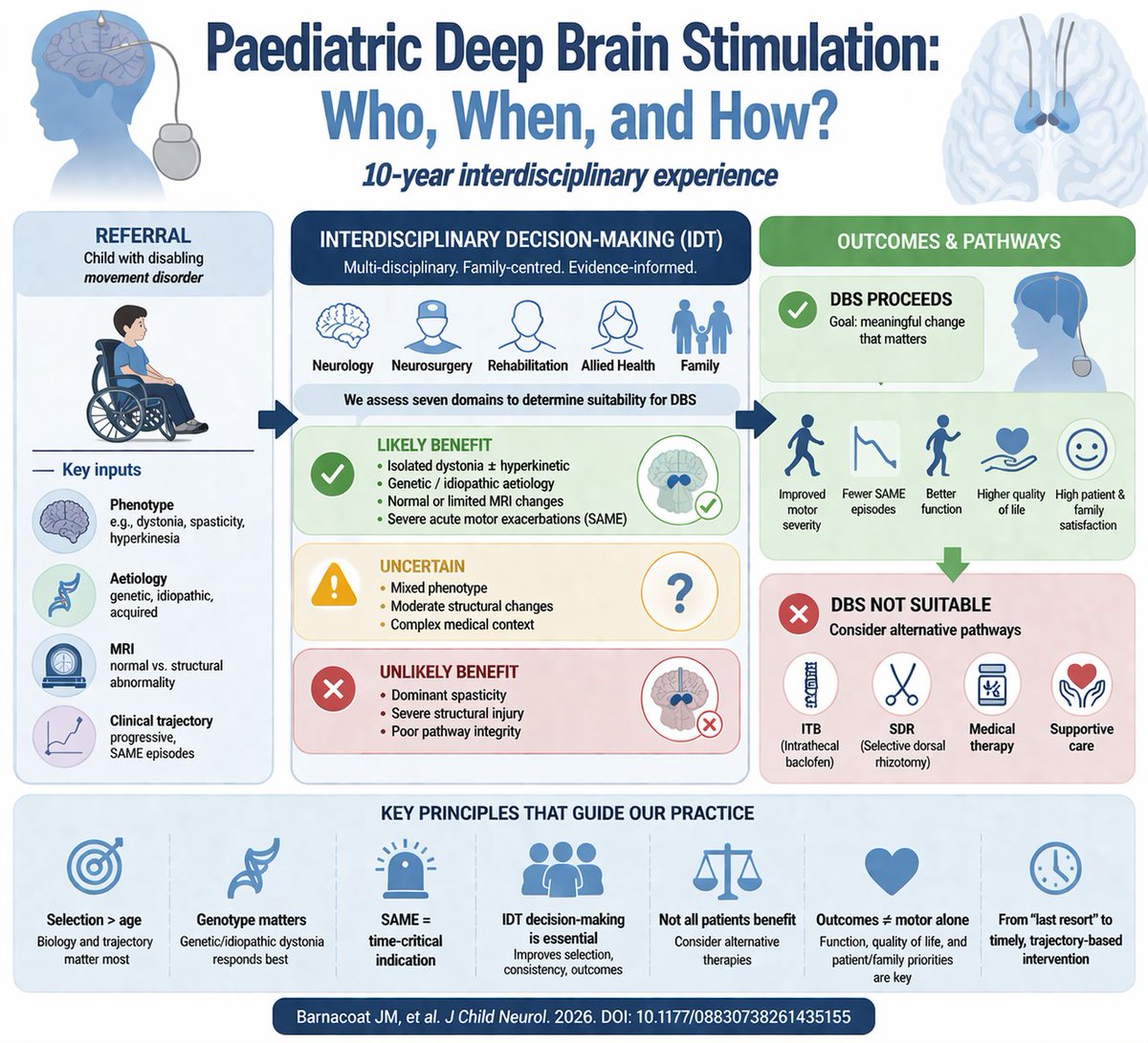
doi.org/10.1177/088307… Decision making in paediatric DBS (Graphic generated with AI assistance)
English
Sarah
275 posts


@98saratonin
Bioinformatics - Centre for Transplant and Renal Research @WestmeadInst


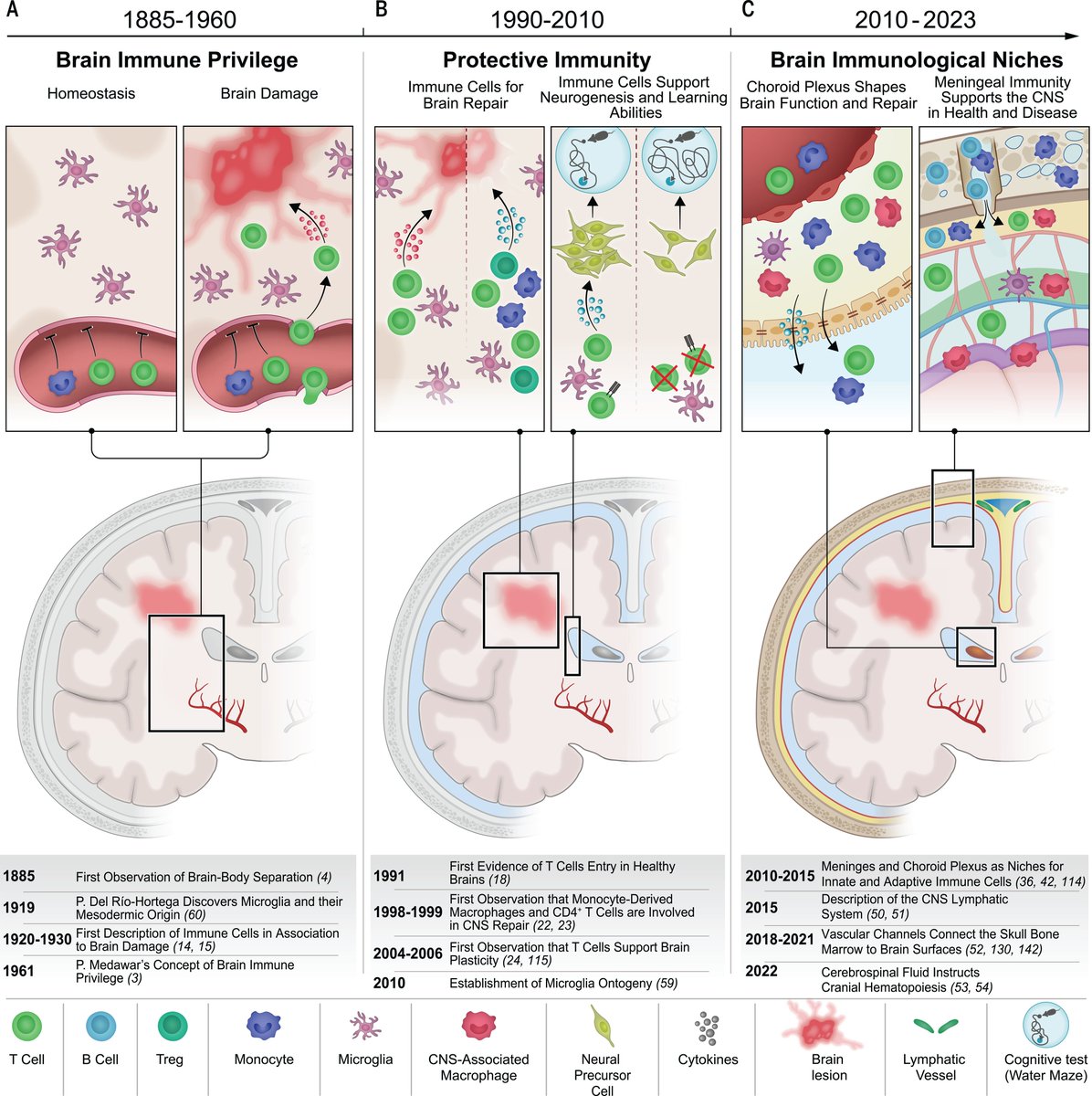
Have you ever wondered what cell types are colocalized or separated? If these relationships change across scales? Or if we could use them to compare samples? Check out CRAWDAD, our package for analyzing cell-type spatial relationships across length scales! nature.com/articles/s4146…


















🎉Congrats to the team in @RussellCDale's Clinical Clinical Neuroimmunology Group, part of the Kids Neuroscience Centre at Kids Research🧬 Their work has changed Hugo's life for the better!