
AI MasterClass
31 posts

AI MasterClass
@AIMasterClass_
8‑week AI Masterclass to build RAG systems and AI agents you can deploy.
Bangalore, India Katılım Aralık 2025
6 Takip Edilen52 Takipçiler
Marc Randolph, co-founder of Netflix, says something we deeply believe in:
"You learn more in one month of doing something than in three months of thinking about doing something."
This is exactly how we built AI Masterclass.
You build. From week one.
Neural networks from scratch. Fine-tuning LLMs. Deploying real systems.
English
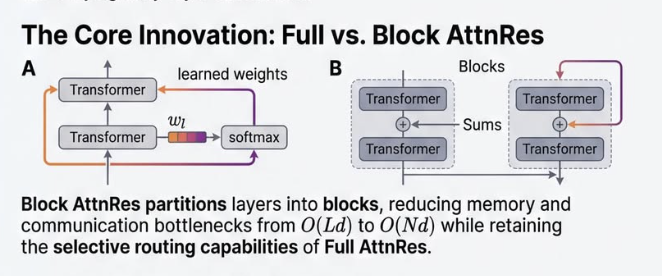
Every Transformer since "Attention is All You Need" does the same thing at every layer: 𝘩ₗ = 𝘩ₗ₋₁ + 𝑓(𝘩ₗ₋₁). Take the previous hidden state. Run it through attention or MLP. Add the result back.
Unroll that across all layers:
𝘩ₗ = embedding + layer1_output + layer2_output + ... + layerₗ₋₁_output
Every layer's output added with 𝐞𝐪𝐮𝐚𝐥 𝐰𝐞𝐢𝐠𝐡𝐭. No layer can say "I need more of layer 3, less of layer 12."
As networks get deep, this causes 𝐝𝐢𝐥𝐮𝐭𝐢𝐨𝐧 - early signals get buried under a growing sum. And there's 𝐧𝐨 𝐬𝐞𝐥𝐞𝐜𝐭𝐢𝐯𝐢𝐭𝐲 - every layer receives the same accumulated blob.
Sound familiar? Same problem RNNs had over sequence length. Everything compressed into one state, no way to selectively retrieve.
We know how that got solved: 𝘢𝘵𝘵𝘦𝘯𝘵𝘪𝘰𝘯.
The Kimi team just did exactly that - but across 𝐝𝐞𝐩𝐭𝐡.
𝐀𝐭𝐭𝐞𝐧𝐭𝐢𝐨𝐧 𝐑𝐞𝐬𝐢𝐝𝐮𝐚𝐥𝐬 replaces the fixed sum with a learned weighted sum. Each layer gets a small query vector that attends over all previous layer outputs: what do I actually need from earlier?
For scale, 𝐁𝐥𝐨𝐜𝐤 𝐀𝐭𝐭𝐧𝐑𝐞𝐬 groups layers into ~8 blocks and attends over block summaries. Inference overhead: under 2%.
Results on Kimi Linear (48B params, 1.4T tokens): → GPQA-Diamond: 36.9 → 44.4 → Math: 53.5 → 57.1 → HumanEval: 59.1 → 62.2
𝘞𝘦 𝘭𝘦𝘵 𝘭𝘢𝘺𝘦𝘳𝘴 𝘢𝘵𝘵𝘦𝘯𝘥 𝘢𝘤𝘳𝘰𝘴𝘴 𝘵𝘰𝘬𝘦𝘯𝘴. 𝘞𝘩𝘺 𝘯𝘰𝘵 𝘢𝘤𝘳𝘰𝘴𝘴 𝘥𝘦𝘱𝘵𝘩?
Fresh off the press - paper dropped 3 days ago.
📄 Link in comments.
𝘍𝘰𝘭𝘭𝘰𝘸 𝘈𝘐 𝘔𝘢𝘴𝘵𝘦𝘳𝘤𝘭𝘢𝘴𝘴 for breakdowns of research that actually matters.
English
In pursuit of greatness? 🚀
To build world-class AI, you need the right fuel. Step into the AI Masterclass and learn the deep learning skills to reach the top.
Join our 8-week online course.
𝙖𝙞𝙢𝙖𝙨𝙩𝙚𝙧𝙘𝙡𝙖𝙨𝙨.𝙞𝙣
#𝘼𝙄 #𝘿𝙚𝙚𝙥𝙇𝙚𝙖𝙧𝙣𝙞𝙣𝙜 #𝘼𝙄𝙈𝙖𝙨𝙩𝙚𝙧𝙘𝙡𝙖𝙨𝙨
English
The April AI Masterclass is our last cohort until August!
Why the long break? Our founder is heading off to the FIFA World Cup, and we're pausing operations so the whole team can recharge (and watch a lot of football)! 🏆⚽
Because of this, the cohort starting on Monday, April 6th, is your last opportunity to train with us until late summer. We only have a few slots left, and they will go fast.
Want to lock in your AI skills before we head out? Click the link in our bio to grab your spot!

English
Seats are filling. If this post made you think of that one AI project — stop scrolling and take action now:
aimasterclass.in/ai-ready-course
English
𝗧𝗵𝗶𝘀 𝘄𝗮𝘀𝗻'𝘁 𝘀𝘂𝗽𝗽𝗼𝘀𝗲𝗱 𝘁𝗼 𝘄𝗼𝗿𝗸.
A hands-on AI course where you don't just watch, you build.
Your own project.
Your own problem.
With someone personally making sure you don't quit.
Sounds idealistic, right?
That's exactly what @Arjunjain thought. After decades in AI, he kept seeing the same pattern — brilliant people consuming content, never shipping anything.
So he didn't just talk about it.
He 𝗯𝘂𝗶𝗹𝘁 the solution.
𝗧𝗵𝗲 𝘀𝗲𝗰𝗿𝗲𝘁 𝗶𝘀𝗻'𝘁 𝘁𝗵𝗲 𝗰𝗼𝗻𝘁𝗲𝗻𝘁.
Content is everywhere.
It's the accountability.
→ A personal TA who won't let you disappear
→ Weekly office hours with Dr. Arjun Jain himself
→ A global cohort — so you're never building alone
By week 8, you'll have a shareable link.
Proof you didn't just learn AI — you 𝗯𝘂𝗶𝗹𝘁 with it.
What's that one AI project you've been putting off?
English
Rahul retweeted this at 3AM.
Still hasn't shipped anything.
The next cohort won't wait for him.
aimasterclass.in/ai-ready-course
English
It's 3AM. Rahul just got his fourth AI certificate. He feels unstoppable.
Certificate downloaded.
He uploads to LinkedIn before he sleeps.
Wakes up to 54 likes.
Three "Congrats!" comments.
Monday morning his manager drops a Slack message.
"Can you build a quick AI tool for the client deck?"
Rahul opens his laptop. Pulls up his notes.
Rewatches two lectures. Sits there for hours.
Ships nothing.
@Arjunjain has seen this pattern for decades.
MaxPlank. IIT Bombay. IISc. Bosch.
Aramco. Apple. Mercedes.
30+ papers. 8,000+ citations.
So, he built the @AIMasterClass_
Every week — one assignment.
Don't finish it, you don't move forward.
No skipping. No shortcuts. No exceptions.
It doesn't end with a certificate.
It ends with a deployed product in your portfolio.
The gap between knowing AI and shipping AI is not information.
It's execution.
Rahul is already googling another AI tutorial to binge watch.
You don't have to.
Link in comments.
English
AI MasterClass retweetledi

When you want to heal, but your anxiety is currently your company’s employee of the month. 🙃 Anyone else feel personally attacked by this?
#HustleCulture #MentalHealth

English
For 30 years, the smartest engineers tried to teach computers to recognize the world around them.
𝐓𝐡𝐞𝐲 𝐟𝐚𝐢𝐥𝐞𝐝. 𝐖𝐡𝐲?
For 30 years (1970s–90s), engineers wrote thousands of lines of code, trying to bottle human intuition into if-else statements.
That didn't work out.
The real world is too messy.
1. A handwritten "2" by a child looks nothing like one written by a doctor.
2. A cat in the shadows looks nothing like a cat in sunlight.
So they admitted defeat.
And that defeat changed everything.
Engineers stopped trying to describe a "2."
Instead, they collected 1,000 handwritten samples and averaged them.
Then, something remarkable happened.
Out of the noise, a crisp "2" emerged.
Mathematically, the sample mean converges to the expected value.
- The noise (variance) cancels itself out because it is random.
- The signal (the shape of the digit “2”) reinforces itself because it is structured.
- When a new image arrives, the model measures how close it is to the mean using L2 or cosine distance.
This is the Data Driven Paradigm.
Instead of writing the algorithm, you feed data — and the data helps build the algorithm for you. Hand-coded logic breaks down fast when the input space is multi-dimensional and messy.
Simple algorithms with massive data often beat clever algorithms with little data.
Most people jump straight into implementation. The confusion that follows isn't a skill gap — it's a missing foundation.
The real question was never "how." It was always "why."
At the AI Masterclass we start from First Principles.
Link in comments.
#AI #MachineLearning #FastCodeAI #AIEducation #LearnAI #ArjunJain ]#AIMasterClass
English
The "why" is where we start.
Everything else follows.
Join us👇
aimasterclass.in/ai-ready-course
English
The difference between users and leaders?
Users experiment.
A few build real systems.
But Leaders turn AI into leverage.
Meet @Arjunjain
→ PhD, Max Planck Institute
→ Ex-Apple
→ Worked with @ylecun (Godfather of Deep Learning)
→ Co-founded a company, acquired by Mercedes Benz
Arjun Jain’s @AIMasterClass_ bridges the gap between curiosity and capability — from prompting to production.
No hype.
No fluff.
Just engineering.
Built for real systems.
Built for scale.
Built for serious builders.
Cohort 4 starts April 5.
Limited seats.
Link in the first comment 👇
English
The future won’t wait.
Upgrade yourself today.
Secure your spot soon!
aimasterclass.in/ai-ready-course
English
AI MasterClass retweetledi
𝗪𝗵𝘆 𝗔𝗜 𝗶𝘀 𝗮 𝗖𝗼𝗱𝗶𝗻𝗴 𝗚𝗲𝗻𝗶𝘂𝘀 𝗯𝘂𝘁 𝗮 𝗠𝗲𝗱𝗶𝗼𝗰𝗿𝗲 𝗪𝗿𝗶𝘁𝗲𝗿
Ask an LLM to build a complex web scraper, and it gives you flawless Python. Ask it to write a heartfelt email, and it sounds like a corporate HR manual. Why is AI accelerating so rapidly at math and coding, but constantly stumbling over the nuances of English?
It all comes down to a fundamental difference in how we teach models what "good" actually means.
𝗧𝗵𝗲 𝗣𝗼𝘀𝘁-𝗧𝗿𝗮𝗶𝗻𝗶𝗻𝗴 𝗣𝗵𝗮𝘀𝗲: 𝗧𝗲𝗮𝗰𝗵𝗶𝗻𝗴 𝗔𝗜 𝘁𝗼 𝗕𝗲𝗵𝗮𝘃𝗲
Initially, LLMs are just trained to predict the next word. To turn them into helpful assistants, they go through a post-training phase called Reinforcement Learning from Human Feedback (RLHF). This is where we reward the AI for good answers and penalize it for bad ones so it learns how to act.
𝗧𝗵𝗲 𝗣𝗿𝗼𝗯𝗹𝗲𝗺 𝘄𝗶𝘁𝗵 𝗘𝗻𝗴𝗹𝗶𝘀𝗵: 𝗜𝘁’𝘀 𝗦𝘂𝗯𝗷𝗲𝗰𝘁𝗶𝘃𝗲
When we train an AI to write a polite message or a compelling essay, how do we grade it? Language is messy and highly subjective. We can't have humans grade millions of responses, so we train a "Reward Model"—literally another AI trained on pairs of human preferences—to act as the judge. At the end of the day, evaluating English relies on an AI trying its best to guess human subjectivity.
𝗧𝗵𝗲 𝗠𝗮𝗴𝗶𝗰 𝗼𝗳 𝗠𝗮𝘁𝗵 𝗮𝗻𝗱 𝗖𝗼𝗱𝗲: 𝗧𝗵𝗲𝘆 𝗮𝗿𝗲 𝗩𝗲𝗿𝗶𝗳𝗶𝗮𝗯𝗹𝗲
Code and math, on the other hand, exist in a beautifully structured world. You don’t need a subjective AI judge; you just use hard, absolute rules. Did the code compile? Did it pass the unit tests? Is the math logically sound?
Take a simple equation: 3x + 5 = 10.
Pure logic dictates 3x = 5, so x = 5/3. If the AI outputs exactly that, it gets a reward. If it outputs anything else, it gets penalized. There are no points for a "creative attempt" or a "friendly tone." It is absolutely right or absolutely wrong.
𝗧𝗵𝗲 𝗦𝘂𝗽𝗲𝗿𝗽𝗼𝘄𝗲𝗿: 𝗧𝗵𝗲 𝗜𝗻𝗳𝗶𝗻𝗶𝘁𝗲 𝗗𝗮𝘁𝗮 𝗟𝗼𝗼𝗽
This verifiability changes the game entirely. Because the AI doesn't have to wait for a slow, fuzzy Reward Model to grade its work, it unlocks infinite self-training. An LLM can generate millions of math problems or Python scripts, automatically verify the answers against a compiler or calculator, and update its own neural network in a massive, instantaneous loop.
When the feedback is objective, perfectly accurate, and fully automated, AI improves at lightning speed.
English