Trelis Research@TrelisResearch
Top Text-to-Speech (TTS) Models in 2026
--
There are a ton of text to speech models out there and it's hard to know what to choose.
I created some tricky text samples for 10 different models (some proprietary, some open source) to synthesize.
And then I compare them for accuracy and for realism.
Proprietary models are ahead here for sure, although on realism, most models today are excellent.
Timestamps:
0:00 Introduction to TTS evaluation with four-row dataset and three metrics
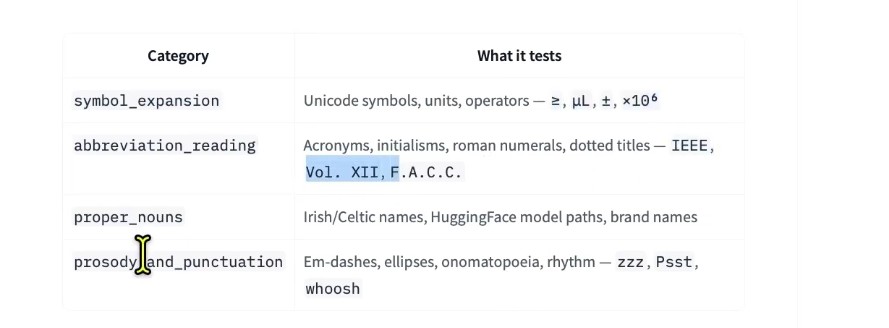
1:08 Tricky TTS dataset: symbols, abbreviations, nouns, and prosody challenges
2:13 Prosody examples: snoring sounds, hissing, and paralinguistic elements
4:17 Roundtrip CER methodology: TTS output transcribed back with ASR
6:12 Two evaluation metrics: roundtrip CER and mean opinion score (MOS)
7:12 Results: proprietary models (Gemini, GPT-4o, ElevenLabs) achieve 4.2-4.3 MOS
10:40 Gemini demo: handles symbols and prosody but produces unexpected Irish accent
13:39 GPT-4o mini paralinguistics test: snoring example and symbol errors
15:41 ElevenLabs struggles with technical content and Irish pronunciation
17:11 Kokoro performs well but mispronounces "WV" with incorrect pauses
19:28 Orpheus model tested on unfamiliar words, Irish, and technical citations
21:30 Piper TTS quality issues: airy and choppy delivery, CPU vs GPU tradeoffs
23:12 Voxtral autoregressive model stops early with premature end token
25:15 Chatterbox produces garbled output with high CER (0.86) but realistic sound
26:15 Recommendations: Kokoro best open-source option, normalization needed for technical text
27:04 Dataset and evaluation tools available on Trelis platform