Sabitlenmiş Tweet

AFTERPARTY™️
2K posts

@afterparty
Afterparty enables digital commerce through conversations




Great conversation in DC with @SenLummis, @MarshaBlackburn, @SenatorTimScott & others on keeping innovative crypto companies in the US. They recognize how crucial crypto & AI are to our nation’s competitiveness. Excited to keep working together to drive this innovation forward 🇺🇸
ReadyAI 2.0 is here! Process raw data from ANY Huggingface dataset into structured outputs Get your data AI-ready It’s a big leap toward decentralized Scale AI. Try it now: readyai.ai/p/data_pipeline Also see our roadmap for the next 6 months 👇 ReadyAI 2.0 is here! AI-Ready Data with the Jobs Interface ReadyAI just launched our Jobs Interface Beta, a powerful frontend that enables organic queries on Subnet 33. This new interface allows end users to process raw data from any Huggingface dataset into structured outputs tailored to their needs. Try it now: readyai.ai/p/data_pipeline This milestone is a significant step toward our vision of becoming a decentralized Scale AI. ReadyAI empowers individual developers and enterprises of all sizes to make their data AI-ready, seamlessly integrating it into AI models and applications. Organic Queries: The Next Era for the ReadyAI Ecosystem We have initiated the next phase of our journey with the introduction of organic queries into the miner incentive system. This phased rollout ensures: Fair Miner Scoring: Maintaining fairness and high-quality outputs for all contributors. Structured Data Integration: All Tagging queries processed through the Jobs Interface will now be scored alongside conversation data. New Data Sources: Social media data, starting with SN13 Dataverse Reddit data, will be incorporated as an organic query source. Data tagging and structuring are pivotal steps in the AI Agent pipeline. With the increasing demand for real-time, high-quality data for retrieval-augmented generation (RAG) systems and fine-tuned models, ReadyAI is uniquely positioned to lead this transformation. Over the next couple of months, we will showcase AI Agents powered by our structured data pipeline. 6 Month Roadmap 1. Organic Queries / Jobs Interface Initial Rollout: Organic Tagging queries are live via the Jobs Interface on readyai.ai/p/data_pipeline right now and are being processed by the ReadyAI validator. Other validators may adopt this new branch, but we will be testing with ours to ensure vTrust and tag quality remains high before rolling this out more broadly. Social Media Data Expansion: After validating the initial rollout, we plan to increase the proportion of validator windows processed from social media datasets from Macrocosmos Dataverse (SN13). 2. Incentive Design 2.0 Enhanced Capabilities: We are upgrading our incentive system to support metadata tagging for arbitrary text data. This includes single-label and multi-label categorization. Competitive Positioning: These improvements will achieve product parity with Scale AI's structured data offerings, reinforcing ReadyAI's position as a high-quality, cost-effective alternative. 3. AI Agent Launches Powered by ReadyAI AI Agent Partners: We are collaborating with partners to launch AI Agents powered by ReadyAI's structured data pipeline within the next 1–2 months. These AI Agents will demonstrate the power of structured data pipelines for RAG systems and real-world applications. 4. Integrating Data Scraping with SN13 ReadyAI as the Data Frontdoor for Bittensor: We are collaborating with SN13 to incorporate data scrapping and structuring on data into our frontend. We are currently validating on SN13 and starting to provide structured data around Reddit/Twitter datasets they have created. Next up: enable users to choose data for scrapping and then data structuring. 5. Enterprise Sales New Leadership: We recently hired a Director of Sales with a proven track record of driving $15 million in software sales over the last two years. Accelerated Growth: With the Jobs Interface live and increasing demand for structured data, we are scaling our enterprise sales offerings to onboard new customers. 6. Image/Video Metadata Tagging Integration Testing: Image metadata tagging, a critical business line for Scale AI, is being tested for integration into the subnet.
The success of Virtuals/ai16z in consumer AI agents and Bittensor subnets' work on decentralized AI infrastructure are complementary. As agents scale in TVL and influence, robust training/inference infrastructure becomes even more vital. More consumer facing apps and subnets coming soon from the Bittensor eco—stay tuned! Shoutout @virtuals_io—my former team @DeFianceCapital backed them pre-rebrand and their pivot to the agent economy has been nothing short of incredible.
Ventura Labs Ep. 7 - David Fields David (@DavFields) is the Founder of ReadyAI (@ReadyAI_) and Afterparty (@afterparty) Timestamps: 0:55 - Introduction 1:36 - What is ReadyAI 4:40 - The Team Behind ReadyAI 7:58 - The Significance of Bittensor 11:15 - Impact of EVM Smart Contracts 14:50 - Importance of Structured Data 16:37 - ReadyAI Approach to AI 19:19 - Decentralization vs Centralization 23:18 - Performance Metrics 25:25 - Future Direction 28:09 - Social Media Data 32:13 - Expanding to Vision 35:34 - Roadmap 37:11 - dTAO 44:07 - Commercialization of Subnets 49:10 - How to Find Product Market Fit
Clip From: Hash Rate - Ep. 74: @ReadyAI_ Bittensor SubNet 33 - 'Decentralized Scale.AI' 🧙♂️Guest: @DavFields Full Ep: x.com/markjeffrey/st…
Hash Rate - Ep. 74: @ReadyAI_ Bittensor SubNet 33 🧙♂️Guest: @DavFields 'A Decentralized ScaleAI' on $TAO 00:00 Introduction to BitTensor and ReadyAI 02:53 David Fields' Background and Experience 06:12 Understanding Scale AI and Its Market Position 09:02 The Role of LLMs in Data Annotation 12:10 Cost Efficiency and Accuracy of ReadyAI 15:00 Disruption in the AI Data Annotation Market 17:53 The Importance of Human Feedback in AI 20:46 Why Choose BitTensor for AI Solutions? 24:05 Dynamic Tao and Its Implications 27:02 Exploring Other Subnets and Community Engagement 29:54 The Future of BitTensor and Its Ecosystem 33:13 Dynamic Tao Explained 36:04 Competition in the Decentralized AI Space Ledger: shop.ledger.com/HashRate Messari Pro (15% off code): MARKJEFFREY15 Also Available on YouTube / Apple / Amazon / Spotify
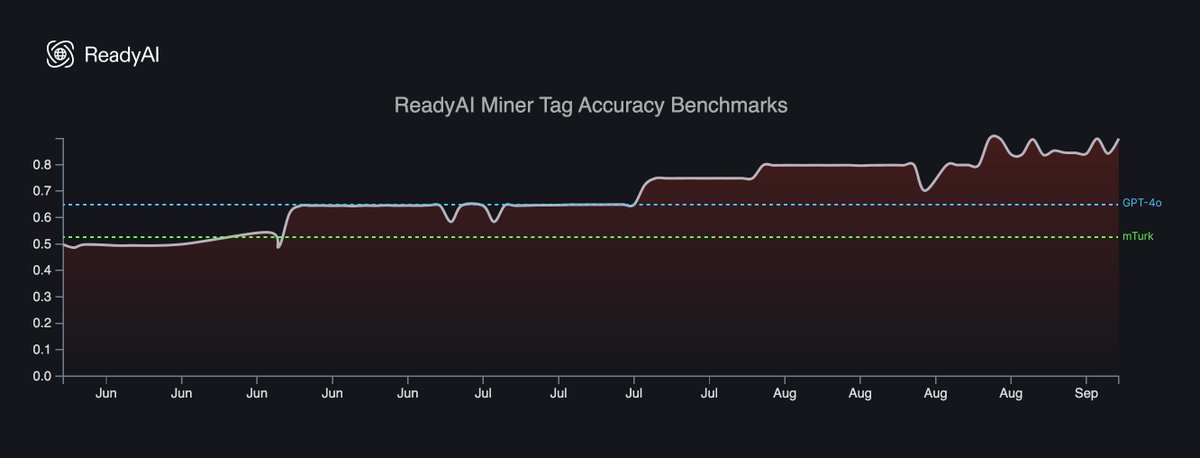
ReadyAI is delivering 71% MORE ACCURATE structured data for AI models at 600x LOWER COST than human annotation services like MTurk and ScaleAI All this in our first 100 days since launch and we are just getting started 🫡 Presentation on our roadmap at the Bittensor meetup👇 $TAO @opentensor 🤝 @ReadyAI_
Had a great time hosting the 2nd community event with @opentensor and 6 #Subnets @TensorplexLabs @getmasafi @afterparty @omron_ai and @404gen_ @openkaito in SG 🇸🇬 Hope everyone enjoy the vibe of the best community $TAO ❤️
@DavFields - Cofounder @afterparty

Join us for the 2nd @opentensor Asia Community Meetup during #Token2049 🇸🇬! There has seen many exciting developments and it is a perfect opportunity for the ecosystem to come together! $TAO lu.ma/wlm6qt2a


