
@nutrientdocs Native PDF redaction inside an AI chat completely cuts out the clunky 'download, edit, re-upload' loop.
English
Aishwarya Singh (Aish)
540 posts
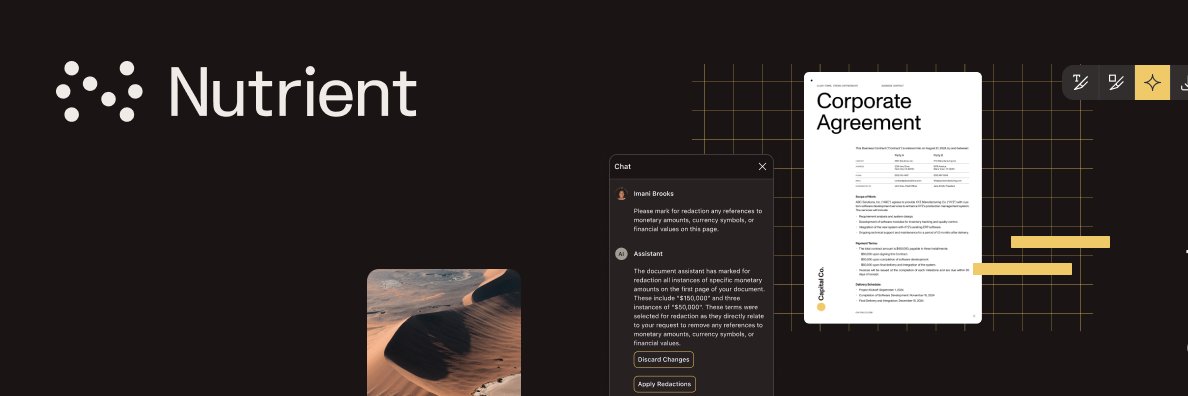

You shouldn't have to scrub a doc by hand before sending it. Gave Claude Cowork a 3-page letter with PII through it. Nutrient PDF Editor surfaced every SSN, email, phone → I confirmed → wiped. Search for the SSN now: nothing. Real redaction. Not black boxes over text. nutrient.io/claude-desktop…
Your team just finished building a Python extraction pipeline on top of Nutrient Vision API. Three months from now, a new developer inherits it. They need to know when to use the fast OCR path, how to enable table extraction with cell coordinates, and when to bring in VLM-enhanced analysis for complex layouts. This step-by-step walkthrough of the Vision API in Python and Java covers basic extraction, table parsing, equation recognition, and layout analysis with complete code. It's the reference that developer will actually want to find. twp.ai/4hqf9T

This post maps all three browser-based document viewing approaches — JavaScript SDK, hosted iframe, and server-side rendering — to the scenarios where each one actually makes sense, with a concrete tradeoff breakdown on privacy, format support, and engineering effort, plus a Nutrient Web SDK integration walkthrough. nutrient.io/blog/online-do…
This guide covers the cryptographic standards, when to use B-B, B-T, B-LT, and B-LTA signatures, and how to implement signing workflows with Nutrient SDK, API, Document Engine, and Workflow Automation. nutrient.io/blog/complete-…

Have you noticed Anthropic's shipped pdf-viewer plugin never actually shows the PDF? It's fundamentally broken and has been for a while. So we at Nutrient built one that works. nutrient.io/claude-desktop
Your document extraction pipeline has one job: Turn scanned PDFs into structured data. Instead, it's turning invoice tables into word soup and handing your AI a jigsaw puzzle with half the pieces missing. Not every document needs the same extraction engine, and running full layout analysis on a simple receipt wastes compute the same way running basic OCR on a complex multicolumn form wastes your team's sanity. This practical framework for matching OCR, intelligent content recognition, and VLM-enhanced extraction to the right document type will help you scope the integration your engineering team actually needs. From the team that built all three. twp.ai/4hqf9U
Your team is spending $40 per document fixing what OCR missed. Misread table cells, collapsed multicolumn layouts, handwriting that came back as gibberish. The industry sold you 'AI-powered extraction' and delivered a fancy spell-checker. This post explains why traditional OCR fails on complex documents and how Nutrient Vision API's intelligent content recognition works differently: analyzing document structure with local AI models, keeping your data on your infrastructure, and returning cell-level table coordinates your application can actually work with. twp.ai/4hqf9V
You shouldn't lose an afternoon to onboarding paperwork. Dropped a one-page HR form into Claude Cowork. Nutrient PDF Editor read my profile, mapped the fields, signed it. Done before the coffee cooled. Pass it any form. Move on with your day. nutrient.io/claude-desktop…
When your tech is the thing everyone wants to try out, this is what you get. Thanks once again to @SalesforceBen for a great experience at Dreamin' in Data! 1/2
