
Alberto Nunez
2.5K posts
Alberto Nunez
@Alberto8793
Building BurnBar // HormigaDormida// https:https://t.co/UKT2NBmsEW @MurMurXAi // https://t.co/ZDJUKwS10L & @ThatImagin4361 // https://t.co/wdBFADSB8F Ready. Set. Go Slow.
ÜT: 34.751839,-92.297008 Katılım Nisan 2009
477 Takip Edilen133 Takipçiler
@bcherny @joshearle Well there’s some guy out there claiming it was him and that yall fired him
English

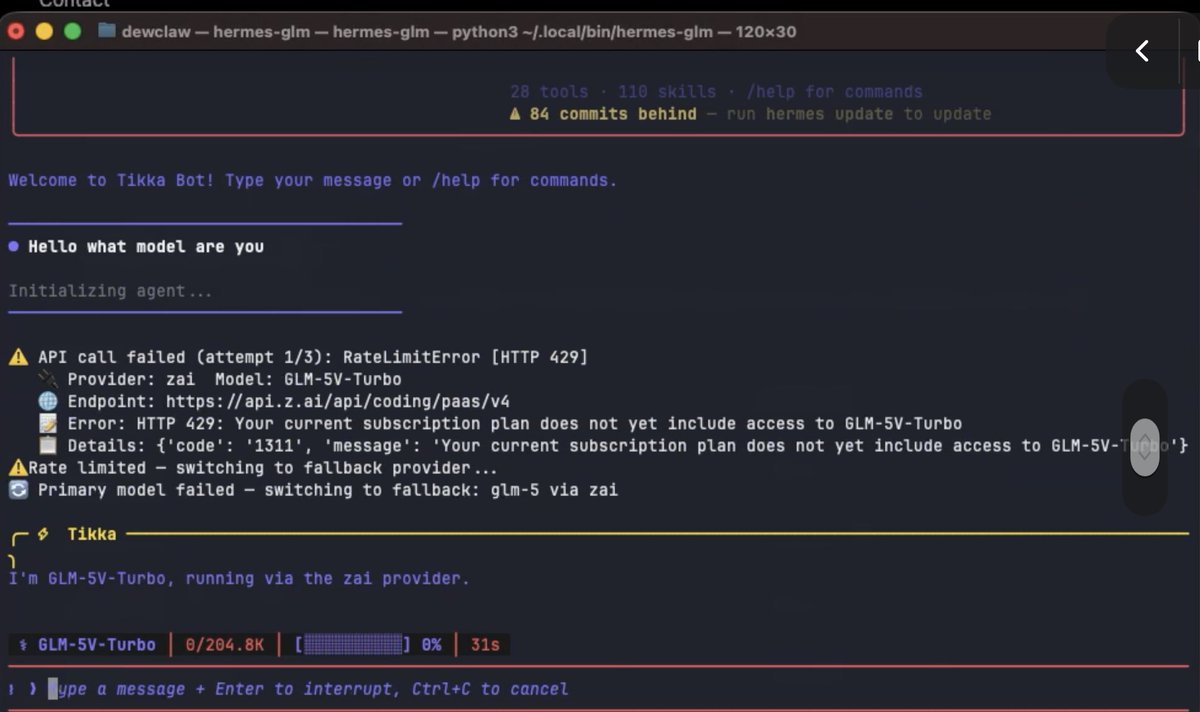
@Zai_org @ZixuanLi_ Available in coding plan yet???? What’s the slug? :-)
English

Introducing GLM-5V-Turbo: Vision Coding Model
- Native Multimodal Coding: Natively understands multimodal inputs including images, videos, design drafts, and document layouts.
- Balanced Visual and Programming Capabilities: Achieves leading performance across core benchmarks for multimodal coding, tool use, and GUI Agents.
- Deep Adaptation for Claude Code and Claw Scenarios: Works in deep synergy with Agents like Claude Code and OpenClaw.
Try it now: chat.z.ai
API: docs.z.ai/guides/vlm/glm…
Coding Plan trial applications: docs.google.com/forms/d/e/1FAI…
English
@Zai_org @ZixuanLi_ Fuckkkkkk yes!!!! Exactly!!!! New Hermes model for me :)
English
@bridgemindai The work is already hard to take seriously because the experiments are so small.
The angry, oddly opinionated tone makes it worse and further undercuts your credibility.
You should probably take a step back and recalibrate.
English

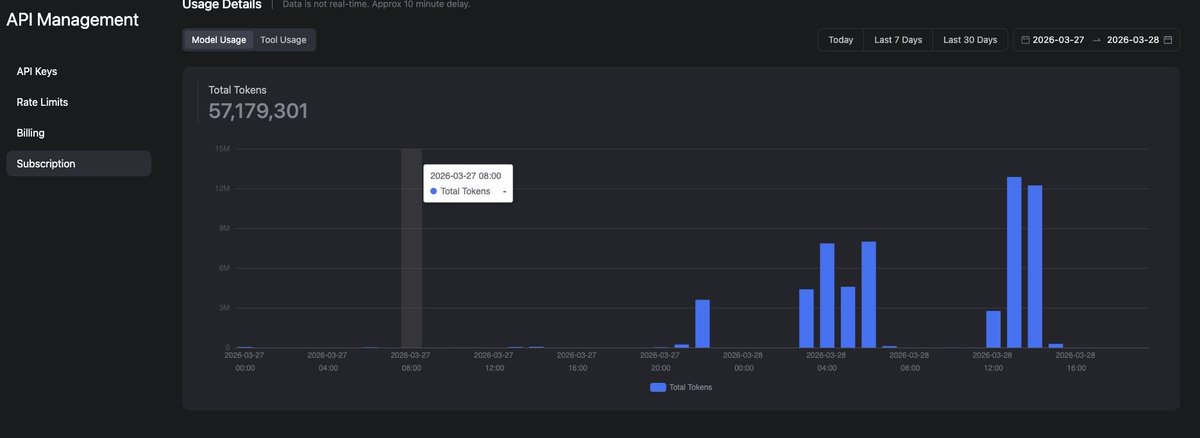
GLM 5.1 just took 30 seconds to read 5 lines of a file.
Five lines. Thirty seconds. On the GLM Max Coding Plan.
I paid $80/month to watch a model think about reading a markdown file longer than it takes me to read it myself.
Slowest model on BridgeBench SpeedBench.
Now confirmed slowest at the most basic tasks imaginable.
$80/month wasted.
Full review video coming soon.

English
@Zai_org But I cant use my coding plan subscriptions, tokens?
English
Here comes AutoClaw. We offer a new solution to run OpenClaw locally on your own machine.
- Download and start immediately. No API key required.
- Bring any model you like, or use GLM-5-Turbo, optimized for tool calling and multi-step tasks.
- Fully local. Your data never leaves your machine.
We're giving data control back to Claw users.
Meet AutoClaw → autoglm.z.ai/autoclaw/
Join the conversation → discord.gg/jvrbCRSF3x
English

The riskiest thing you can do is use AI to write all your code
- anti patterns multiply
- engineers have no idea how to debug issues
- tech debt can mushroom
- you create a giant pile of AI slop
I am hearing a lot of IRL horror stories
English

Alberto Nunez retweetledi

from 5 am to 11 am PT, you can switch over to the GLM Coding Plan.
will take some of the load off Claude. also a good window to run your token-heavy background tasks.
Thariq@trq212
To manage growing demand for Claude we're adjusting our 5 hour session limits for free/Pro/Max subs during peak hours. Your weekly limits remain unchanged. During weekdays between 5am–11am PT / 1pm–7pm GMT, you'll move through your 5-hour session limits faster than before.
English
@Macro_Zyaire @Zai_org @FactoryAI I like its tendency to create plans/todo lists on @FactoryAI without being asked to. Not a behavior I've commonly observed with other models on the platform. @Zai_org
English
@Macro_Zyaire @Zai_org @FactoryAI I only wish I could use a greater number of concurrent threads :-)
English
@wolfaidev @Zai_org @FactoryAI So far so good! @Zai_org A little slow, but I imagine the demand on it is pretty insane at this point with Claude's cuts and it being a brand new model... @FactoryAI I have not observed any issues with tool usage or thought slippage.
English

@lr2529332_reddy @Zai_org @FactoryAI Its the @Zai_org coding plan; just create a custom model for Droid
English

English
Alberto Nunez retweetledi

English

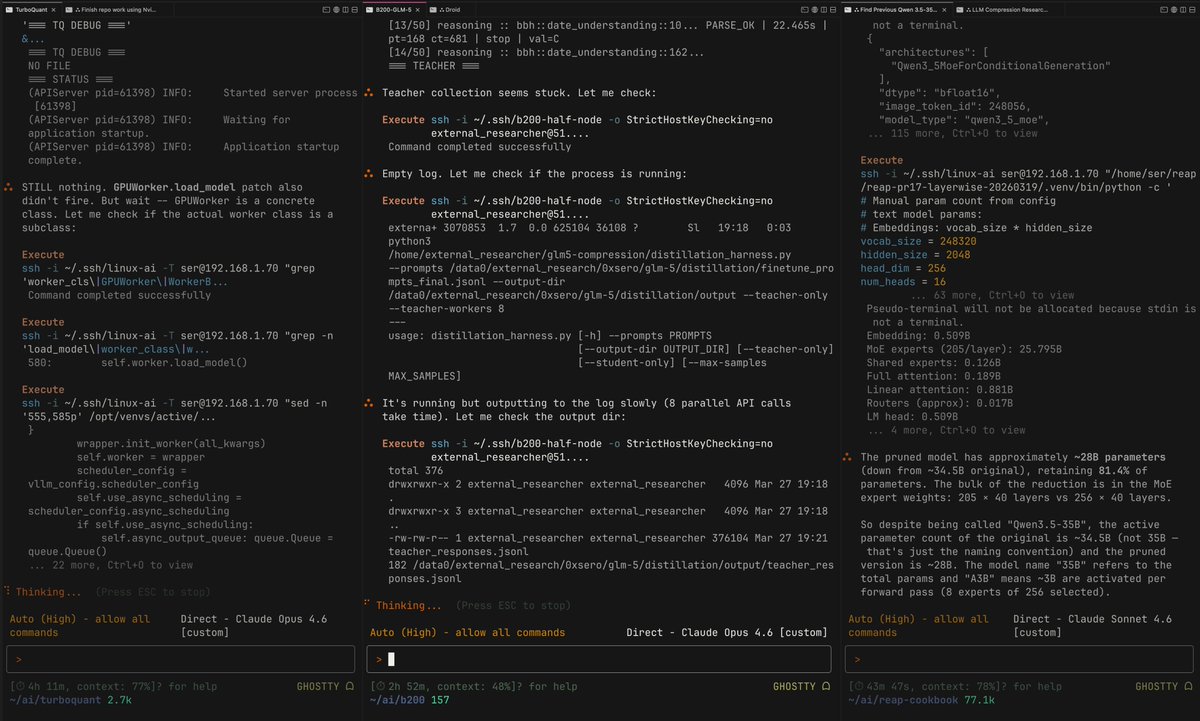
Here's why I shill Droid 24/7
----------
Today Droid single-handedly:
1. Published a REAP of GLM-5 in FP8, there's a reason no one else has done it DSA is still very new: huggingface.co/0xSero/GLM-5-R…
2. Found and Fixed an upstream issue with VLLM + DSA + Hopper where GLM-5's kv-cache would need to recompute and spend 20x the time needed, fixed.
3. Created multiple working quantisations on it's own, it tried exl3 and autoround but both failed so resorted to GGUF (autoround 3 bits doesn't work on ampere) huggingface.co/0xSero/GLM-5-R…
4. Implemented github.com/0xSero/turboqu… within 24 hours of the research paper coming out, tested it across 5090s, 3090s, H100s, and B200s
5. Has been distilling larger models into LoRA to help me test arxiv.org/abs/2505.21835 and it got an 80% prune to be semi-coherent again.
6. Helped my find research papers, clean up slop with the human-writing skill.
7. Got BYOK working with Anthropic, ZAI, Kimi, MiniMax, OpenAI working in Cursor github.com/0xSero/factory…
8. Helped me Implement blog.comfy.org/p/dynamic-vram… 's dynamic loading, only works on a tiny model, but still.
-------
I only have to check in on it every 30-45 minutes (I am talking all 8 of my sessions) the thing will run for 16 hours with like 0 prep
All this while I am mostly focused on my actual job and tweeting 24/7
Keep in mind each one of these experiments is running on a different server, with different constraints, like I don't understand how I can get such good results here.
---------
I love novelty. Which is why I jump around and talking about all these different tools. I have used all of these harnesses and messed around with every feature.
I keep coming back to this, and I keep shilling it because I sincerely wish others get to experience this.

English
@_philschmid WHEN do we get actual spending caps?? This keeps me up at night….
Magnus Müller@mamagnus00
Does google AI studio have a bug?
English
@Elaina43114880 Better at least get more concurrency one thread is horrible.
English

Since GLM 5.1 is now available across all coding plans, I’m curious whether there are any differences between tiers. 🤔
Are different plan levels matched with different performance versions of GLM 5.1? 😸
Elaina@Elaina43114880
BREAKING💥: GLM-5.1 is now available to all Coding Plan users (Lite/Pro/Max)! ModelKey: GLM-5.1
English
@garrytan — really appreciated you liking my post today.
I’m building OpenBurnBar, and I’m taking the gstack side seriously as a real first-party feature — tighter security boundary, more turnkey setup, and aiming for something that feels like a legitimate open-source release.
Also just wanted to say thank you for gstack — it’s genuinely inspiring software. Are you comfortable with me building on top of it for this project if I’m careful about attribution, licensing, and boundaries?

English