Sabitlenmiş Tweet

muP works great for Mamba !
Zero-shot transfered the learning rate from a 172k model to a 105 model.
Now part of mamba.py 👇🧵

English
Alexandre TL
621 posts
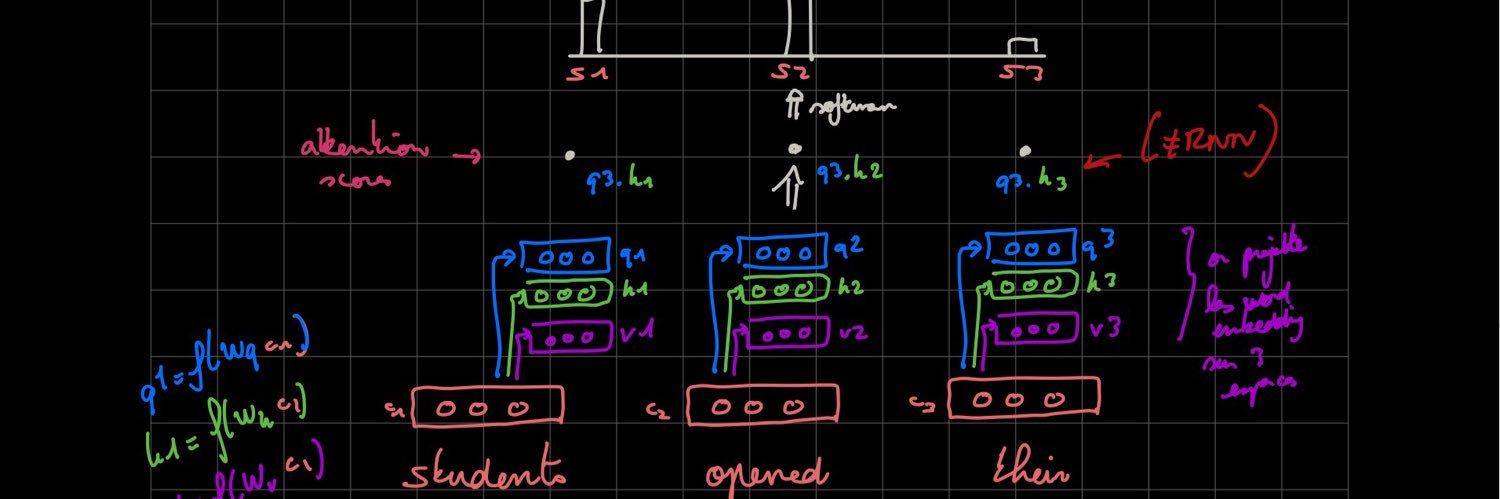
@AlexandreTL2
Intern at @DragonLLM in Paris. (Pre|post)-training LLMs














U-Net 😭


I've added two optimizers to the public benchmark: (1) Shampoo (with its original 1/4 power). (2) Spectral descent, which is equivalent to both Muon(mu=0) and Shampoo(b1=b2=0). Result: Shampoo falls halfway between Muon & Adam; Spectral descent is ~2x slower. Thread below 1/6











