Yan retweetledi

For my friends who are still using UV and might be a little weary about recent compromises to PyPi packages, stick this in your pyproject.toml.
You can let all of those pip users find and report the compromises...

English
Yan
392 posts


Mamba-3 is out! 🐍 SSMs marked a major advance for the efficiency of modern LLMs. Mamba-3 takes the next step, shaping SSMs for a world where AI workloads are increasingly dominated by inference. Read about it on the Cartesia blog: blog.cartesia.ai/p/mamba-3


Asymmetric hardware scaling is here. Blackwell tensor cores are now so fast, exp2 and shared memory are the wall. FlashAttention-4 changes the algorithm & pipeline so that softmax & SMEM bandwidth no longer dictate speed. Attn reaches ~1600 TFLOPs, pretty much at matmul speed! joint work w/ Markus Hoehnerbach, Jay Shah(@ultraproduct), Timmy Liu, Vijay Thakkar (@__tensorcore__ ), Tri Dao (@tri_dao) 1/



Are we done with new RL algorithms? Turns out we might have been optimizing the wrong objective. Introducing MaxRL, a framework to bring maximum likelihood optimization to RL settings. Paper + code + project website: zanette-labs.github.io/MaxRL/ 🧵 1/n

Hey @DimitrisPapail we now have a 512 parameter model that does the job. I instructed opus 4.6 to explore along the direction of low rankness.

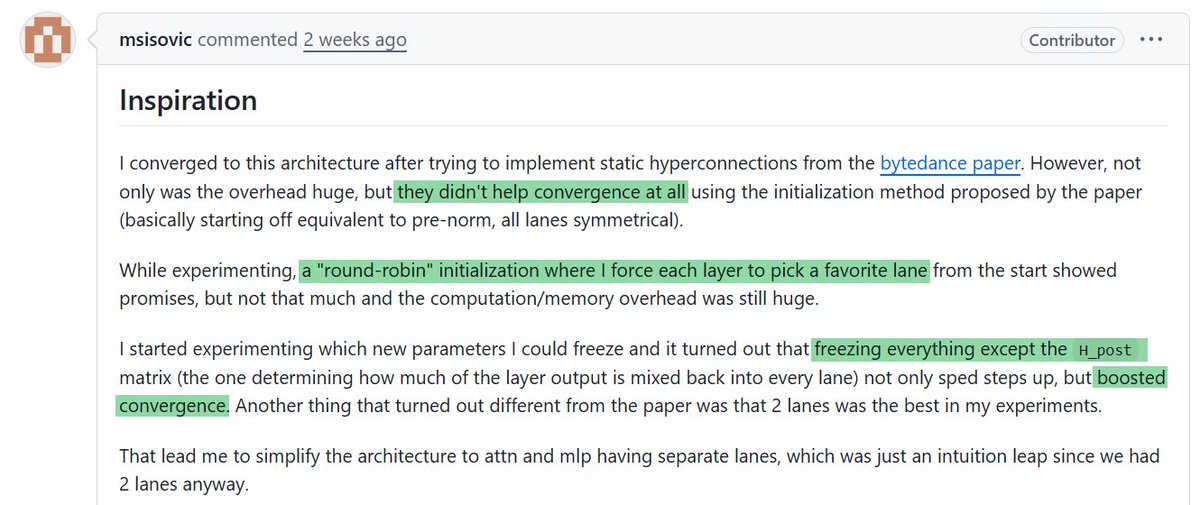
New NanoGPT Speedrun WR at 89.1 (-0.7s) from @sisovicm , with a technique called partitioned hyperconnections. The learned weights reveal that the final attn modules prefer to ignore the prediction vectors generated by the final MLPs, and instead query representations from slightly earlier layers. github.com/KellerJordan/m…




Google DeepMind just solved one of the dirtiest problems in image generation. and the fix is almost embarrassingly elegant 🤯 every diffusion model you've used (Stable Diffusion, Flux, etc.) relies on latent representations. an encoder compresses images into a compact space, and a diffusion model learns to generate in that space. the problem nobody talks about: how you train that encoder is basically vibes. the original Stable Diffusion approach slaps a KL penalty on the encoder with a manually chosen weight. too much regularization and you lose high-frequency details. too little and the latent space becomes chaotic for the diffusion model to learn from. everyone just... picks a number and hopes for the best. it's the equivalent of tuning a radio by feel while blindfolded. DeepMind's paper reframes the entire question. instead of treating the encoder and diffusion model as separate stages, they train them together. the encoder's output noise gets directly linked to the diffusion prior's minimum noise level. this one connection turns the messy KL term into a simple weighted MSE loss, and gives you something you've never had before: a tight, interpretable upper bound on how much information your latents actually carry. think of it like this. before, you were compressing an image and praying the compression ratio was "about right." now you have an actual dial that tells you exactly how many bits of information are flowing through, and you can set it precisely. the results speak for themselves. FID of 1.4 on ImageNet-512 with high reconstruction quality, using fewer training FLOPs than models trained on Stable Diffusion latents. on Kinetics-600 video, they set a new state-of-the-art FVD of 1.3. but the real contribution isn't the numbers. it's that they turned one of the most heuristic-heavy parts of the generative AI pipeline into something principled. the trade-off between "easy to learn" and "faithful reconstruction" was always there. this paper just made it visible and controllable. the uncomfortable implication for everyone building on frozen Stable Diffusion encoders: you've been optimizing everything except the foundation.


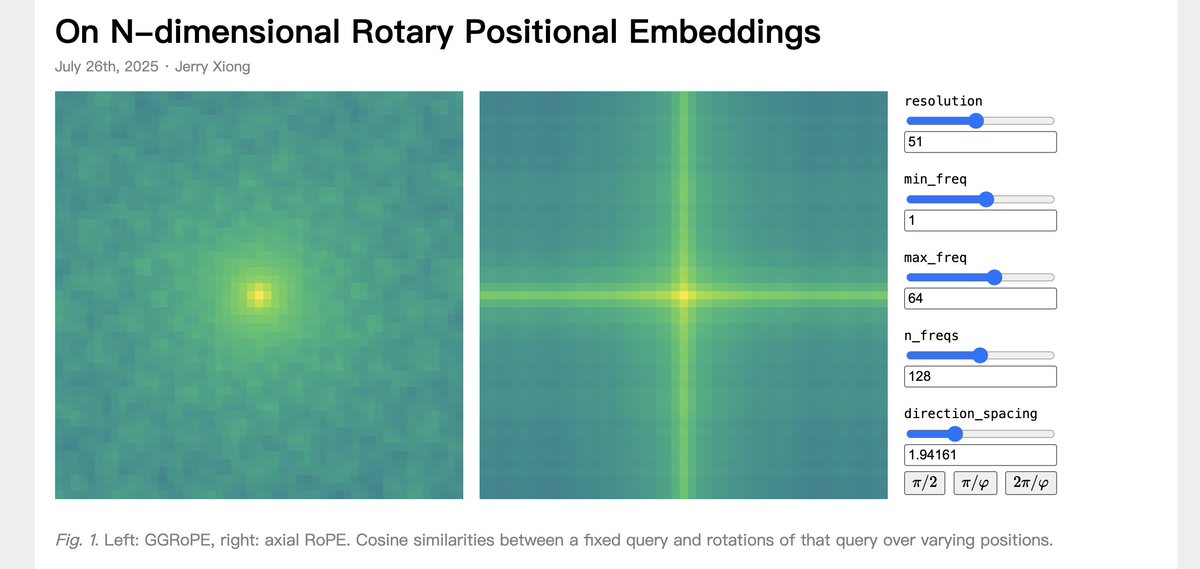
here are few (i have a huge list dumped in my notion!!): 1/ AI Explorables | PAIR (Google): pair.withgoogle.com/explorables/ other PAIR blogs: #interactive-blogposts-and-websites" target="_blank" rel="nofollow noopener">pair.withgoogle.com/research/#inte…
2/ A Visual Dive into Conditional Flow Matching | ICLR Blogposts 2025 : dl.heeere.com/conditional-fl… 3/ On N-dimensional Rotary Positional Embeddings: jerryxio.ng/posts/nd-rope/ 4/ How Does A Blind Model See The Earth?: outsidetext.substack.com/p/how-does-a-b… 5/ Tiny TPU: tinytpu.com 6/ Inside NVIDIA GPUs: Anatomy of high performance matmul kernels: aleksagordic.com/blog/matmul 7/ Making Software: makingsoftware.com 8/ Bartosz Ciechanowski: ciechanow.ski/archives/ 9/ A Decade of Residuals: History & Effects on modern ML: dhia-naouali.github.io/blogs_notes/a-…
It's a weird time. I am filled with wonder and also a profound sadness. I spent a lot of time over the weekend writing code with Claude. And it was very clear that we will never ever write code by hand again. It doesn't make any sense to do so. Something I was very good at is now free and abundant. I am happy...but disoriented. At the same time, something I spent my early career building (social networks) was being created by lobster-agents. It's all a bit silly...but if you zoom out, it's kind of indistinguishable from humans on the larger internet. So both the form and function of my early career are now produced by AI. I am happy but also sad and confused. If anything, this whole period is showing me what it is like to be human again.






