Jack Zhang@jcz42
We made Muon run up to 2x faster for free!
Introducing Gram Newton-Schulz: a mathematically equivalent but computationally faster Newton-Schulz algorithm for polar decomposition.
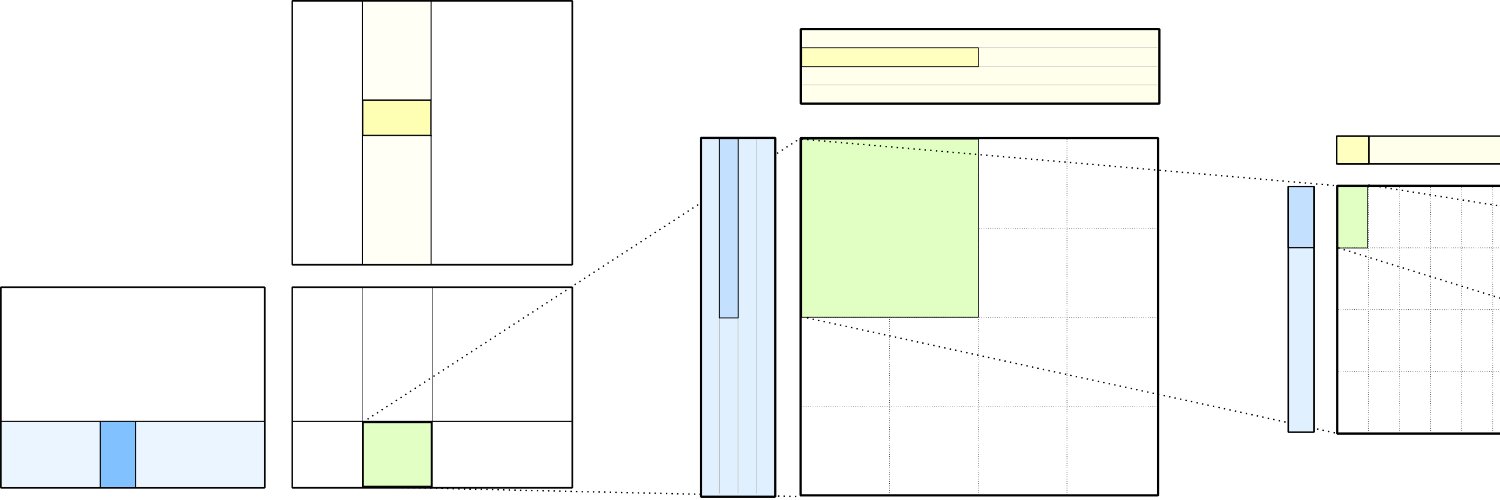
Gram Newton-Schulz rewrites Newton-Schulz such that instead of iterating on the expensive rectangular X matrix, we iterate on the small, square, symmetric XX^T Gram matrix to reduce FLOPs. This allows us to make more use of fast symmetric GEMM kernels on Hopper and Blackwell, halving the FLOPs of each of those GEMMs.
Gram Newton-Schulz is a drop-in replacement of Newton-Schulz for your Muon use case: we see validation perplexity preserved within 0.01, and share our (long!) journey stabilizing this algorithm and ensuring that training quality is preserved above all else.
This was a super fun project with @noahamsel, @berlinchen, and @tri_dao that spanned theory, numerical analysis, and ML systems! Blog and codebase linked below 🧵