@aarvyml Quantization is the moment you realize.
Most of your VRAM was storing precision nobody asked for.
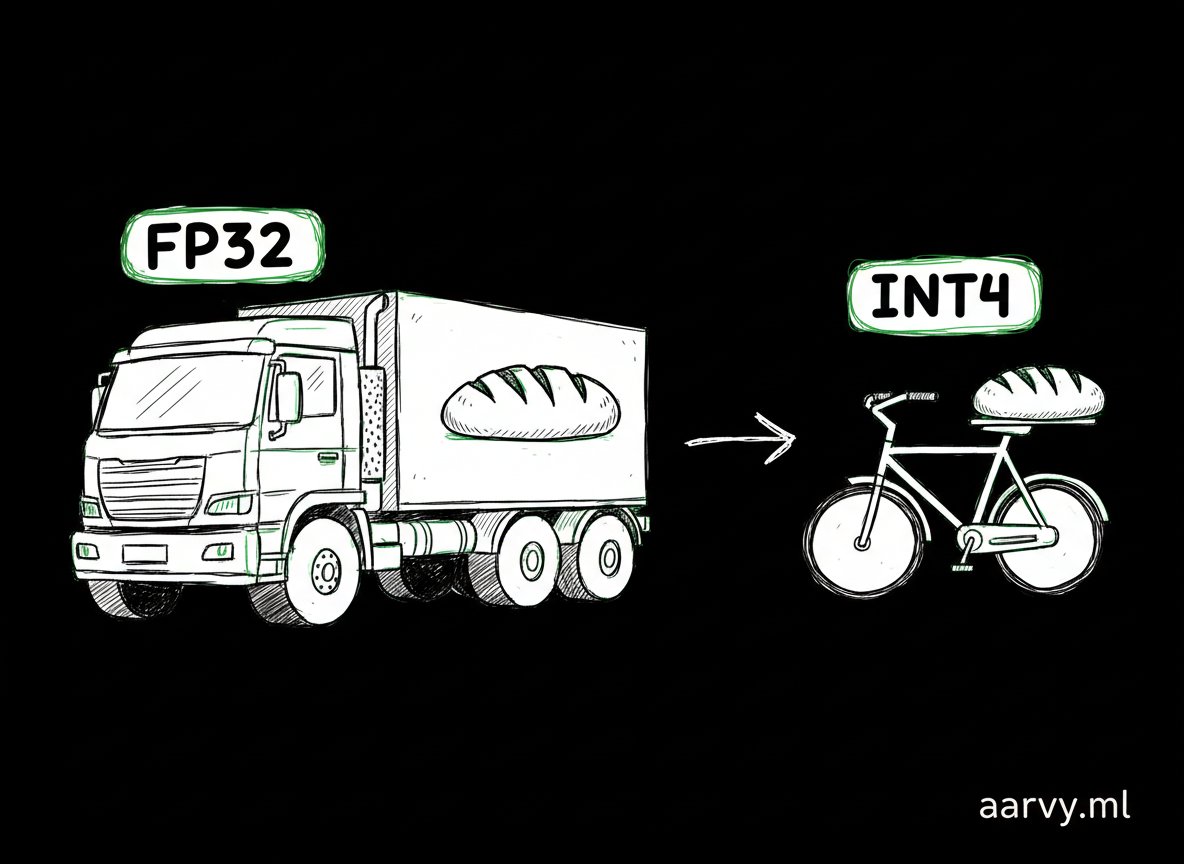
INT4 + good calibration beats FP32.
Users care about latency and cost.
The funny part is most transformers weights already have a distribution that quantizes extremely well.
**Stop being just a Prompt Engineer.** Real value lies in understanding the infrastructure that actually powers AI. Follow for deep dives into ML engineering and optimized deployments. 🚀
**Your GPU is dying for no reason.** Running LLMs in FP32 is like driving a truck to buy a loaf of bread. You're wasting massive VRAM and money for precision you don't actually need. Let's talk about Quantization. 🧵
@aayushchugh But that will come with its 3% fee
But in India you can go down to 2% on cards
And 0% in case of UPI
As far as I know most events tickets
Comes under Rupees 2,000