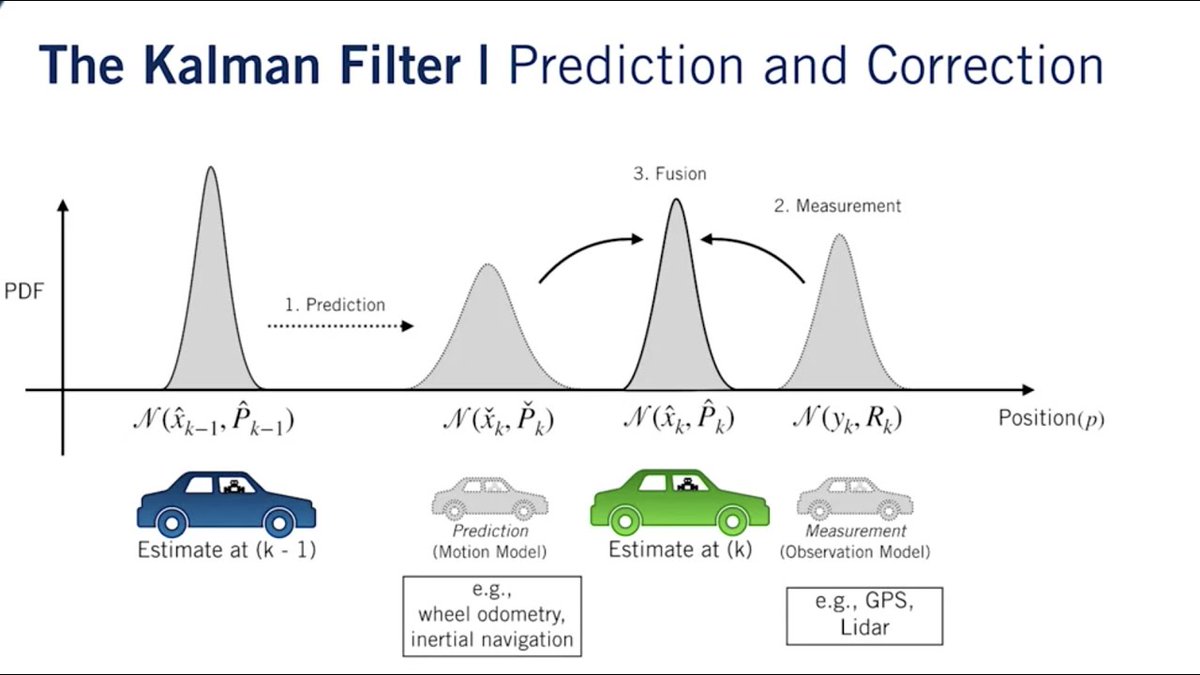
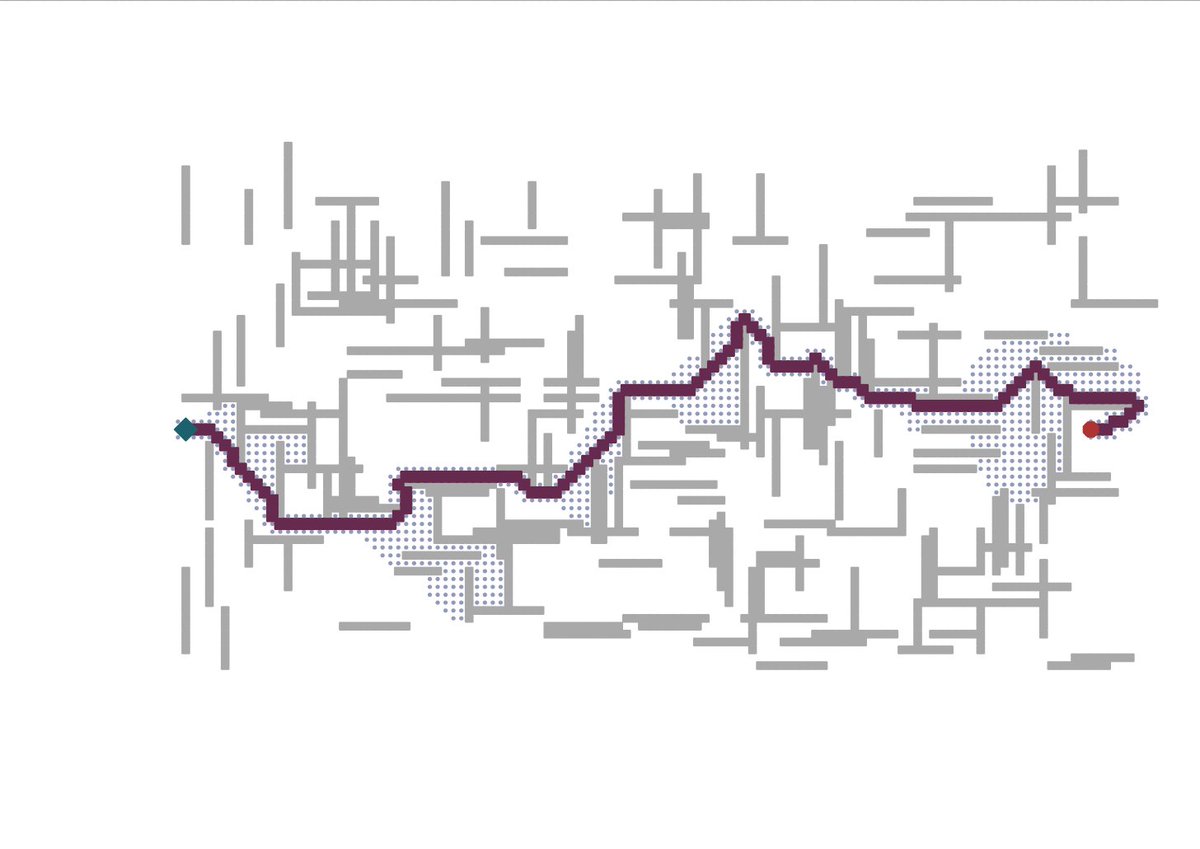
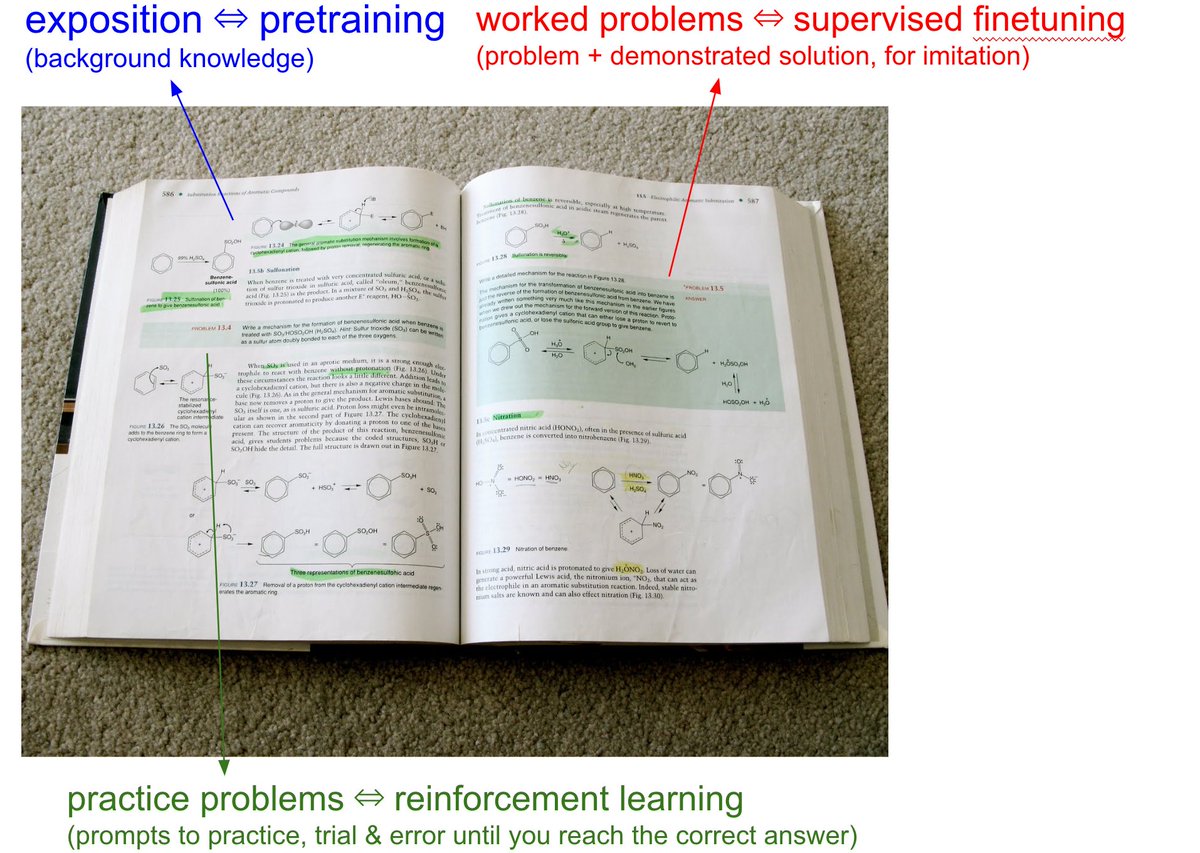
Andrew Bonello retweetledi

This essay is one of the most readable criticisms of US housing finance and policy I’ve ever seen: @byrnehobart/the-30-year-mortgage-is-an-intrinsically-toxic-product-200c901746a" target="_blank" rel="nofollow noopener">medium.com/@byrnehobart/t…
English