Sabitlenmiş Tweet

Drupal Canvas is here!
Here’s how to get caught up:
🔹Read the release announcement on @Dries’s blog: dri.es/drupal-canvas-…
🔹Join the @DripyardStyle webinar next Thursday for a deep dive: dripyard.com/blog/dripyard-…
English
andyg5000
1.6K posts

@AndyG5000
Founder: Blue Oak Interactive, Drupal Development Co-Founder: Dripyard, Premium Drupal Themes Founder: Secret Sounds, Live Audio/Video Recording


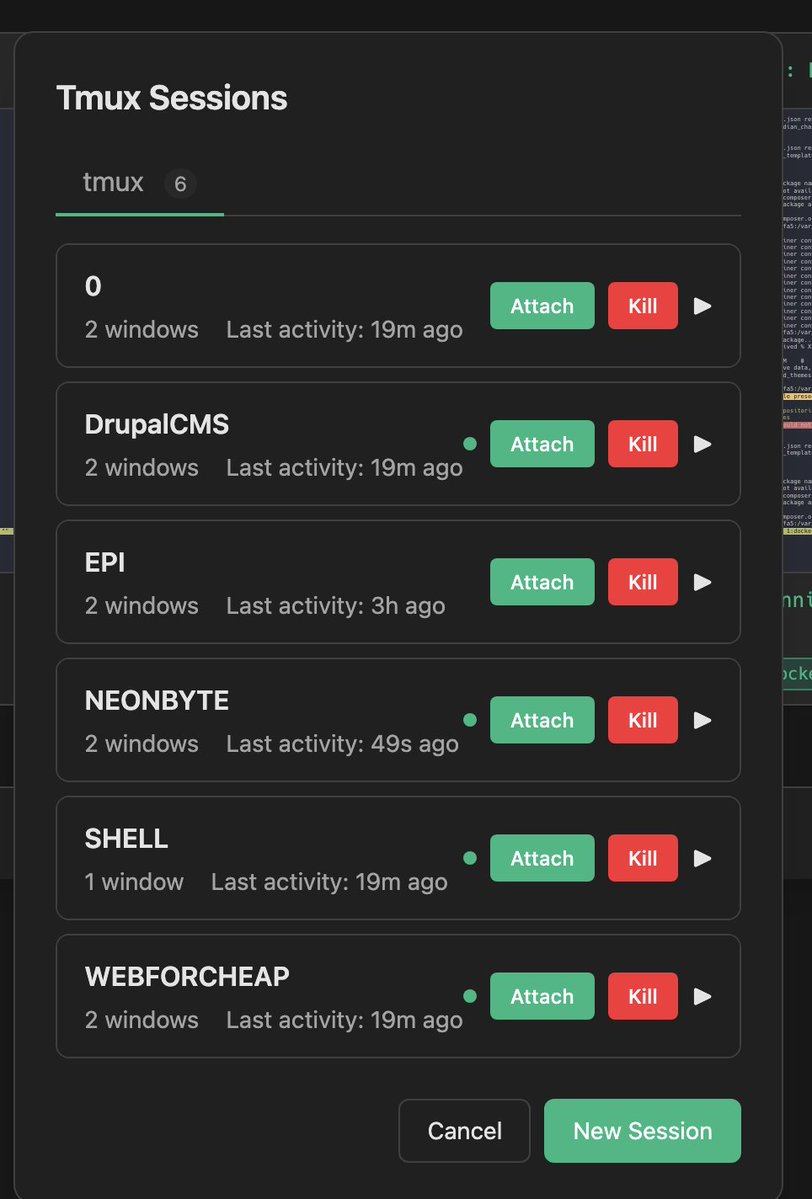
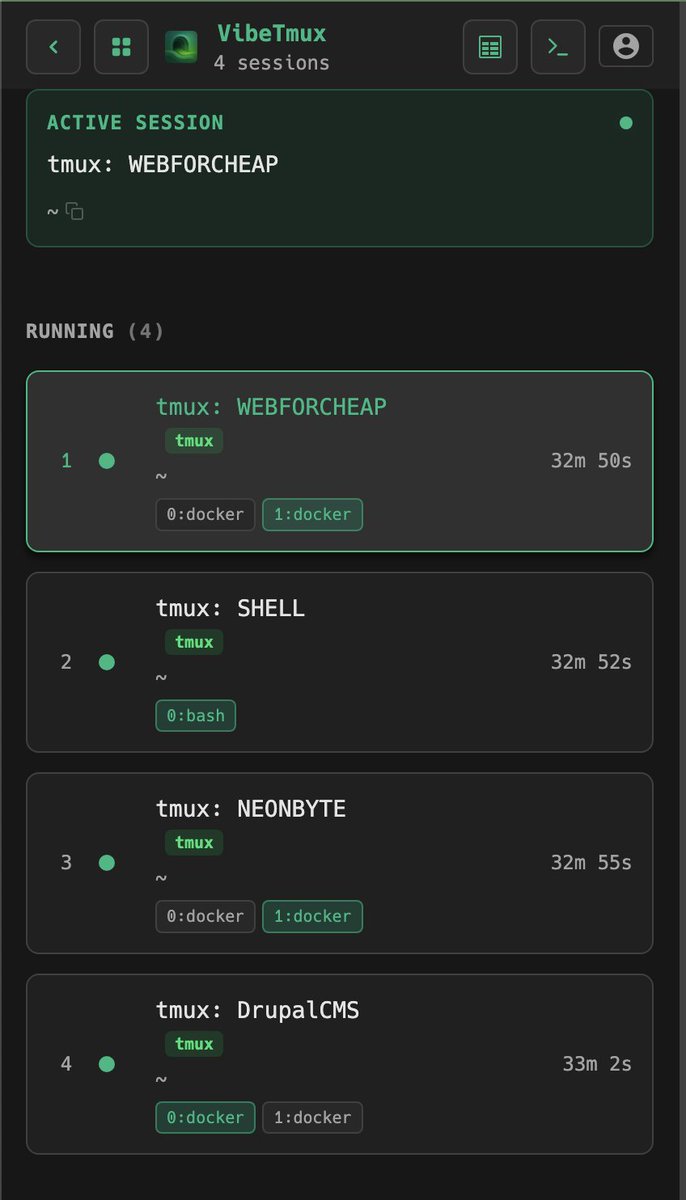
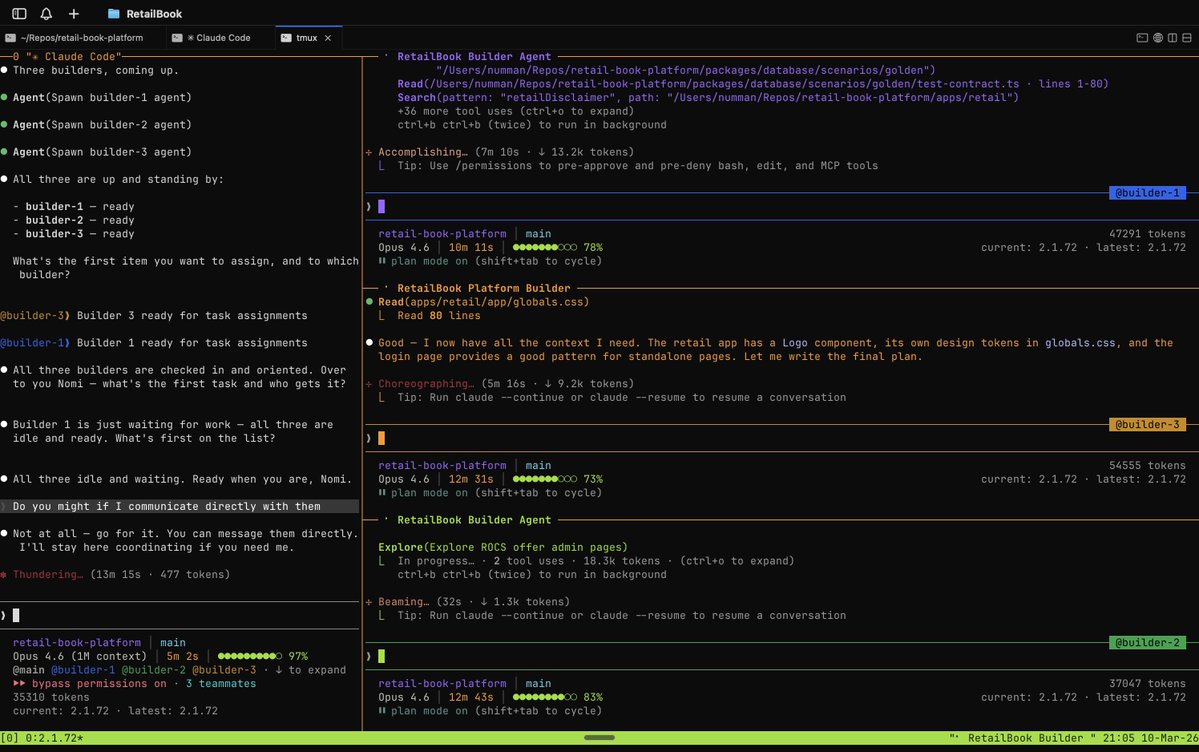
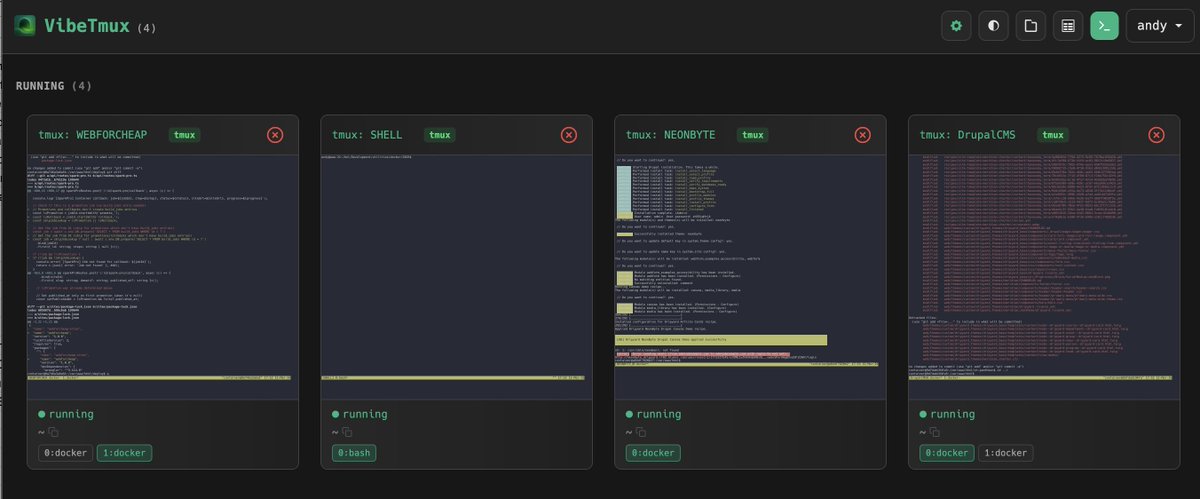
@sudoingX I am fully migrated from openclaw now!