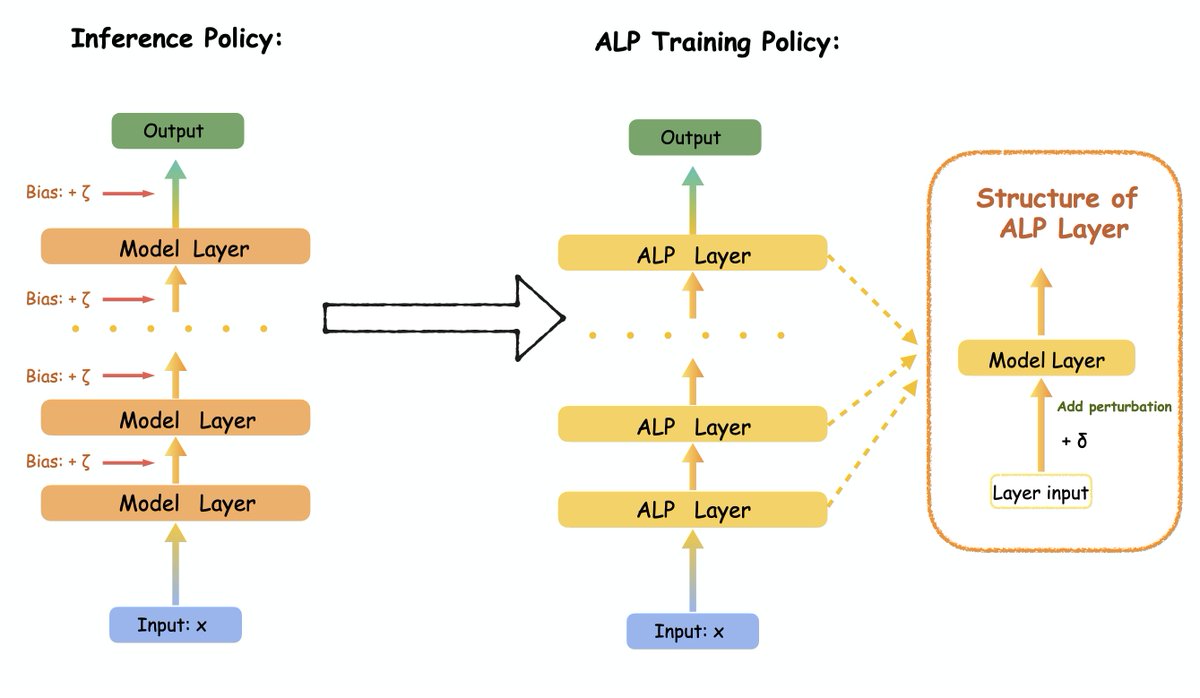
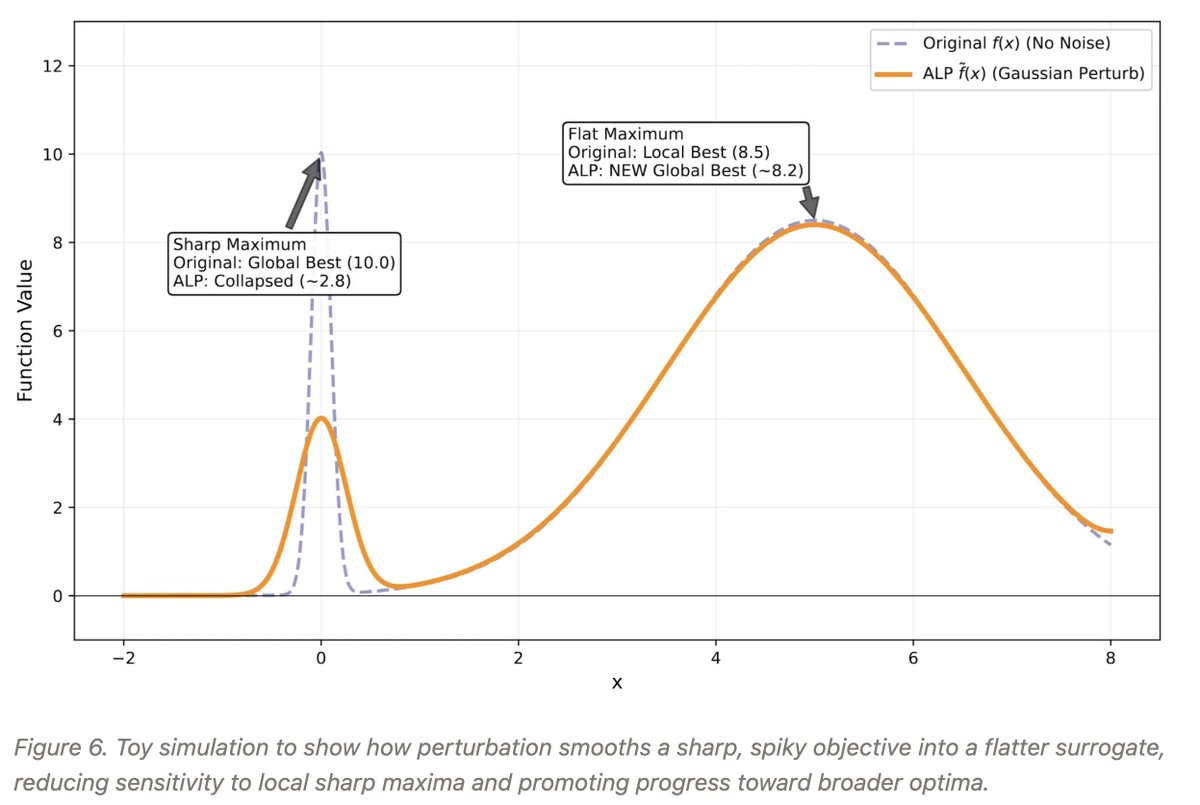
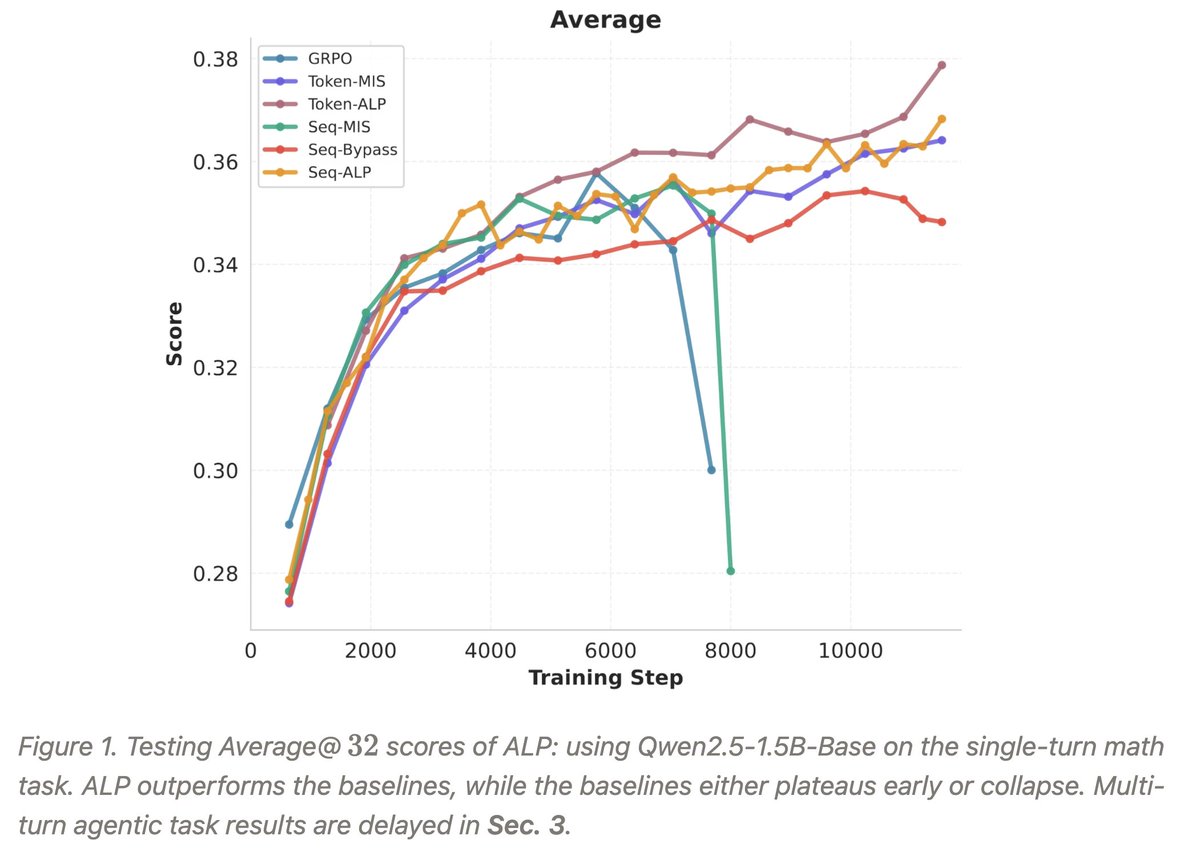
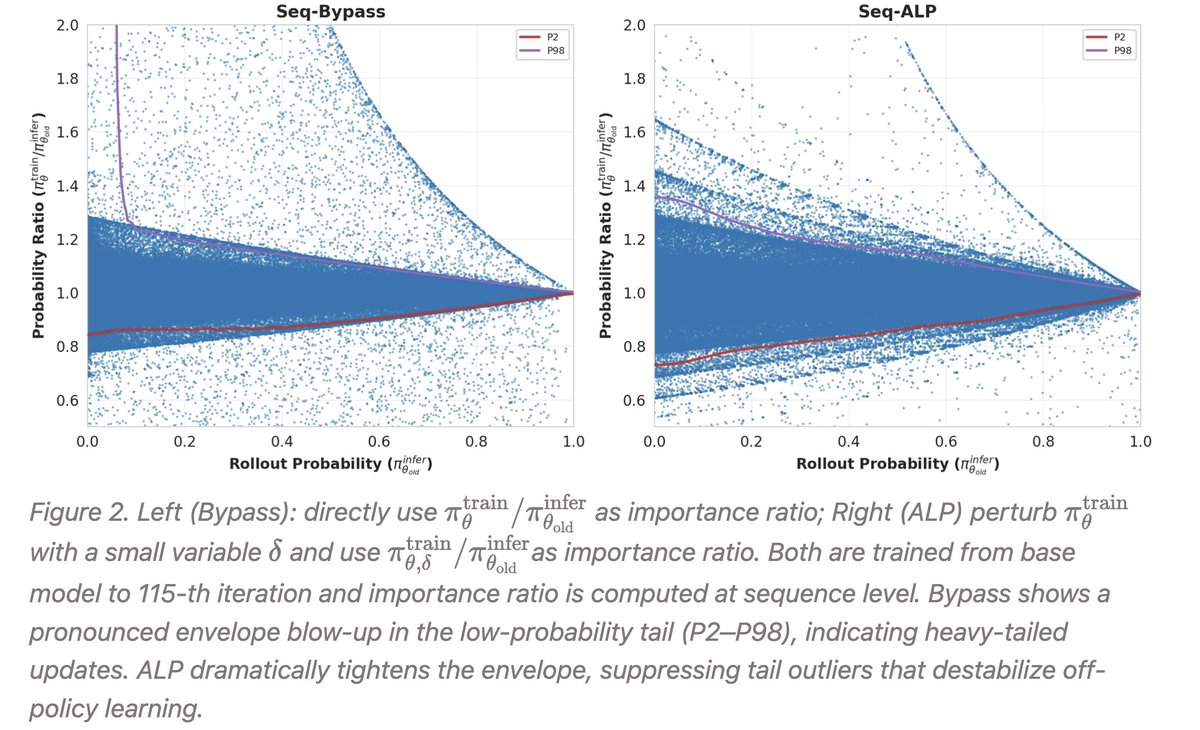
Anthony GX-Chen retweetledi

Your AI Agent just formed a hypothesis. 💭 How does it validate it?
Not by trying to prove itself wrong. Rather, it selectively seeks evidence that confirms what it already believes, often ending up with the wrong answer!
Confirmation bias isn’t just human. We measure it in LLMs, and we show how to fix it! 🧵

English