thinking out loud. every model gets math wrong. 7B, 9B, 70B. doesn't matter. pattern matching is not computation.
hermes agent has code_execution which spins up a full python sandbox with RPC over unix sockets. powerful but heavy. a 9B isn't going to navigate that reliably for basic arithmetic.
what if there was a lightweight calc tool built in. model hits a math question, calls the tool, gets the exact answer computed on your hardware. no interpreter overhead. sandboxed. simple enough schema that a 9B can call it every time.
the accuracy problem stops being a model problem and becomes an infrastructure problem. and infrastructure is solvable.
@Teknium would this belong in hermes agent or is code_execution enough?
Mainly because of old Dawn bindings for Zig. I had to rip that out, and just decided to build the latest Dawn from source for all platforms now, and write our own updated bindings. Was going to have to happen eventually. Also means any platform Dawn natively supports we can support.
might make the switch to linux this year ngl...
what do i use
- mint sucks
- pop os sucks
- nobara is okay
- dank linux is lowkey a contender 😭
- cachy i like
- nix maybe
@varien Qwen3.5-0.8B just dropped. It's not perfect but it's probably the best you're getting at these sizes right now. 2B is closer to what you want, I suspect.
The multimodality is just a bonus.
i've caught the bug for pushing 1B-class models toward something closer to coherent reasoning on the cheapest consumer hardware.
Qwen2.5 and SmolLM2 GGUFs are already running on-device via llama.cpp on Android, so the inference path exists
the question for me is the reasoning ceiling at this scale
anyone experimenting with fine-tuning or prompting strategies to get more structured/compositional reasoning out of models this small?
just like "Tool calling" is kinda dead in face of just using shell commands, i think that a lot of "skills files/mcp type stuff" are stupid in light of just reading the manpage or so on of said shell command.
@platonovadim Slightly contrived example, sure, but the point is that instead of waiting on multiple tool call returns, multiple rounds, burning exponentially more time and tokens, the model can just write a miniature program to do it.
Would it make sense to have the model pass itself as a continuation to evaluate result of step 4 - plugin which continues the conversation in the main context or branches the context? Then initial program would still be generated upfront but spawn more turns during evaluation.
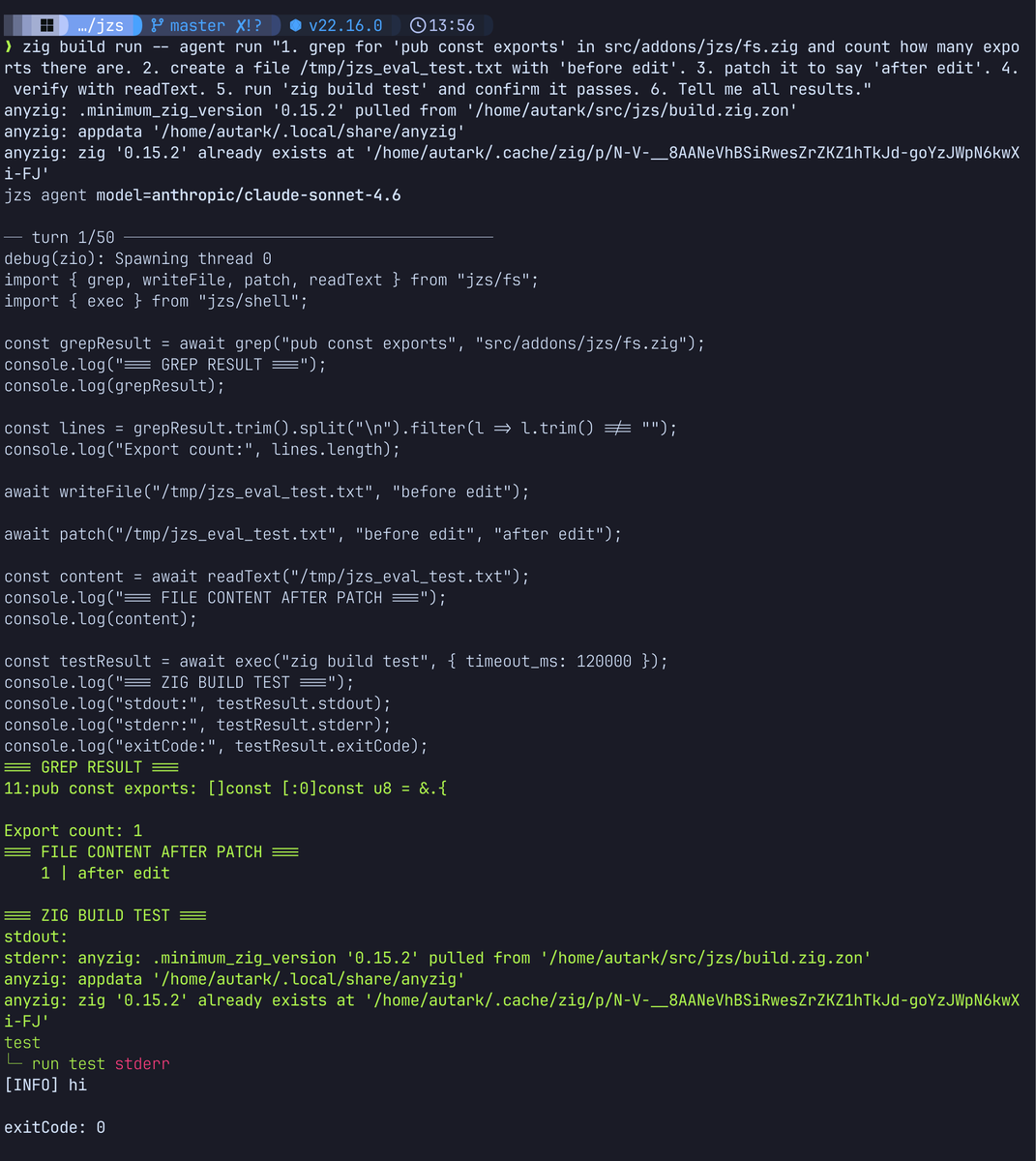
Just have the agent harness write code in JS sandbox instead of juggling external tools. Feels like should work great, except the models might get in the way because they're not trained for it...
I don't really use Hermes, I have my own harness (speaks Javascript directly instead of tool call schema nonsense, an entire category of problems I don't have to worry about). Using structured outputs works so I figure it's the same schema constriction mechanism with vLLM. I don't get denials but I never really did to begin with.
you don't understand anon. i'm on a mission to find the collection of best small models that run full context on consumer hardware.
because when you can orchestrate your own thinking across physical nodes locally, that's not a tool anymore. that's an extension of your mind.
that's exactly where we are headed as a civilization. and most people haven't felt it yet.
@LottoLabs It's just the model compiler this guy used. I didn't quant any of this myself. For me it helps shave off some headroom on the 24GB Laptop 5090.