Sabitlenmiş Tweet

Voici HATS !🎩
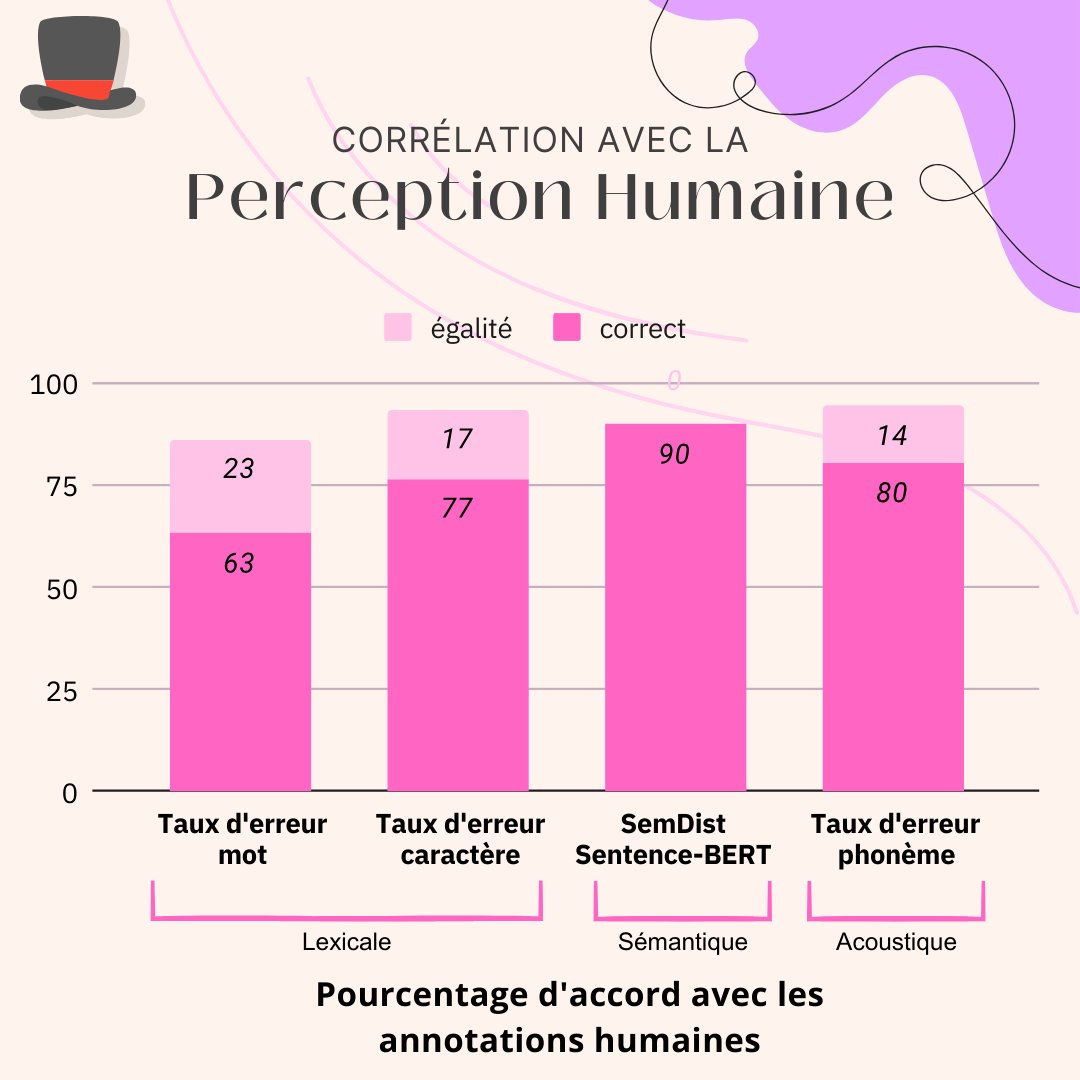
Grâce aux 143 personnes qui ont participé à mon expérience, j'ai pu obtenir 7150 annotations et construire le data set HATS que nous diffusons librement afin que la communauté puisse évaluer les métriques de reconnaissance de la Parole🎙️
Français