Meet BitNet b1.58-2B. This isn't your average LLM. It's a '1-bit' language model, meaning its weights are mostly -1, 0, or +1. This radical efficiency could change how we deploy AI everywhere. The community is buzzing.
🔥 You don't need a $10,000 GPU to run 100B AI models anymore.
Microsoft just made it your laptop's job.
bitnet.cpp is a 1-bit inference framework that:
→ Runs 100B parameter models on CPU
→ Uses 82% less energy
→ Is 100% open-source
The game just changed.
This is one of those “this changes everything” moments.
Microsoft just broke a core assumption in AI.
You needed GPUs to run big models.
Not anymore.
They open-sourced BitNet,
an inference framework that runs a 100B parameter LLM on a single CPU 🤯
No GPU
No cloud
No expensive setup
Just your laptop.
Here’s the trick:
Instead of 16-bit or 32-bit weights...
BitNet uses 1.58 bits
Yes, seriously.
Weights = -1, 0, +1
That’s it.
No heavy matrix math.
Just simple integer ops your CPU already handles easily.
And the results?
• 100B model → 5–7 tokens/sec on CPU
• Up to 6x faster than llama.cpp
• 82% less energy usage
• Runs on x86 + ARM (MacBook)
• Memory reduced by 16–32x
But here’s the insane part:
👉 Accuracy barely drops.
Their model (BitNet b1.58 2B4T) competes with full-precision models trained the “normal” way.
So what does this unlock?
• Fully offline AI (privacy ↑)
• No more API bills
• AI on phones, IoT, edge devices
• Access in low-internet regions
We’re watching AI move from
“cloud-only” → “runs anywhere”
The GPU monopoly just got… shaky.
And this is open source.
Let that sink in. 🚀
Holy shit... Microsoft open sourced an inference framework that runs a 100B parameter LLM on a single CPU.
It's called BitNet. And it does what was supposed to be impossible.
No GPU. No cloud. No $10K hardware setup. Just your laptop running a 100-billion parameter model at human reading speed.
Here's how it works:
Every other LLM stores weights in 32-bit or 16-bit floats.
BitNet uses 1.58 bits.
Weights are ternary just -1, 0, or +1. That's it. No floats. No expensive matrix math. Pure integer operations your CPU was already built for.
The result:
- 100B model runs on a single CPU at 5-7 tokens/second
- 2.37x to 6.17x faster than llama.cpp on x86
- 82% lower energy consumption on x86 CPUs
- 1.37x to 5.07x speedup on ARM (your MacBook)
- Memory drops by 16-32x vs full-precision models
The wildest part:
Accuracy barely moves.
BitNet b1.58 2B4T their flagship model was trained on 4 trillion tokens and benchmarks competitively against full-precision models of the same size. The quantization isn't destroying quality. It's just removing the bloat.
What this actually means:
- Run AI completely offline. Your data never leaves your machine
- Deploy LLMs on phones, IoT devices, edge hardware
- No more cloud API bills for inference
- AI in regions with no reliable internet
The model supports ARM and x86. Works on your MacBook, your Linux box, your Windows machine.
27.4K GitHub stars. 2.2K forks. Built by Microsoft Research.
100% Open Source. MIT License
Microsoft made 100B parameter models run on a single CPU.
bitnet.cpp: The official inference framework for 1-bit LLMs.
The math behind 1-bit LLMs is what makes them revolutionary.
Traditional LLMs use 16-bit floating point weights. Every parameter is a number like 0.0023847 or -1.4729.
When you run inference, you multiply these floats together. Billions of times. That's why you need GPUs, they're optimized for floating point matrix multiplication.
BitNet b1.58 uses ternary weights: {-1, 0, 1}.
That's not a simplification. That's a fundamental change in the math.
When your weights are only -1, 0, or 1:
→ Multiply by 1 = keep the value
→ Multiply by -1 = flip the sign
→ Multiply by 0 = skip entirely
Matrix multiplication becomes addition and subtraction.
No floating point operations. No GPU required.
This is why bitnet.cpp achieves:
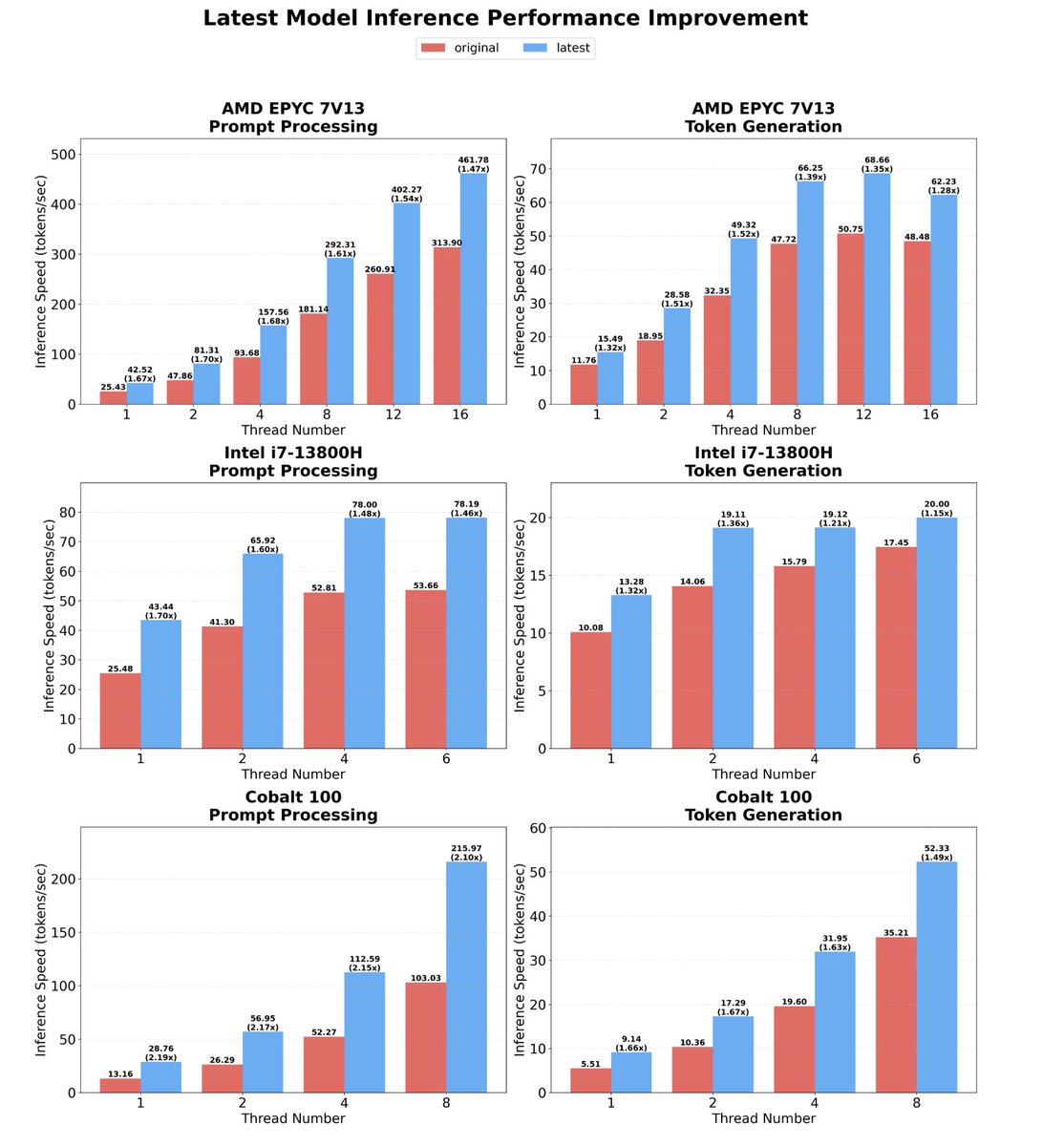
→ 2.37x to 6.17x speedup on x86 CPUs
→ 1.37x to 5.07x speedup on ARM CPUs
→ 71.9% to 82.2% energy reduction on x86
→ 55.4% to 70.0% energy reduction on ARM
The speedups scale with model size. Larger models see bigger gains because there are more operations to simplify.
A 100B parameter model running at human reading speed (5-7 tokens/second) on a single CPU.
That's not optimization. That's a different paradigm.
Why 1.58 bits? Because log₂(3) ≈ 1.58. Three possible values = 1.58 bits of information per weight.
The key insight: These models aren't quantized after training. They're trained from scratch with ternary weights. The model learns to work within the constraint. No precision loss. No quality tradeoff.
🚨 MICROSOFT NEW BITNET.CPP ALLOWS YOU TO RUN 100B MODELS LOCALLY
🔥Official inference framework for 1-bit LLMs.
It lets you run massive 100 billion parameter models on a regular CPU
Human reading speed — 5–7 tokens/sec
Zero GPU needed.• Up to 6.17× faster inference on x86
• 82% lower energy use
• Built on llama.cpp
• Full GGUF support + lossless ternary weights
No cloud. No expensive hardware.
True local 100B AI is here 👇🏻
github.com/microsoft/BitN…
Microsoft solved the biggest problem in local AI
running large models always meant expensive GPUs and cloud bills
they flipped that with BitNet
1-bit LLMs that run entirely on CPU
100B parameters. 82% less energy. speed that matches human reading
no GPU queue. no cloud dependency. just your machine
turns out the hardware was never the real limit
→ github.com/microsoft/BitN…
Holy shit... Microsoft open sourced an inference framework that runs a 100B parameter LLM on a single CPU.
It's called BitNet. And it does what was supposed to be impossible.
No GPU. No cloud. No $10K hardware setup. Just your laptop running a 100-billion parameter model at human reading speed.
Here's how it works:
Every other LLM stores weights in 32-bit or 16-bit floats.
BitNet uses 1.58 bits.
Weights are ternary just -1, 0, or +1. That's it. No floats. No expensive matrix math. Pure integer operations your CPU was already built for.
The result:
- 100B model runs on a single CPU at 5-7 tokens/second
- 2.37x to 6.17x faster than llama.cpp on x86
- 82% lower energy consumption on x86 CPUs
- 1.37x to 5.07x speedup on ARM (your MacBook)
- Memory drops by 16-32x vs full-precision models
The wildest part:
Accuracy barely moves.
BitNet b1.58 2B4T their flagship model was trained on 4 trillion tokens and benchmarks competitively against full-precision models of the same size. The quantization isn't destroying quality. It's just removing the bloat.
What this actually means:
- Run AI completely offline. Your data never leaves your machine
- Deploy LLMs on phones, IoT devices, edge hardware
- No more cloud API bills for inference
- AI in regions with no reliable internet
The model supports ARM and x86. Works on your MacBook, your Linux box, your Windows machine.
27.4K GitHub stars. 2.2K forks. Built by Microsoft Research.
100% Open Source. MIT License
🚨 Microsoft just flipped the AI game upside down.
No GPUs. No insane costs. No barriers.
They quietly dropped bitnet.cpp — and it changes everything.
A 1-bit inference framework
that runs 100B parameter models on your CPU
Read that again.
Not in a lab.
Not on expensive hardware.
On your normal machine.
Here’s why this is wild:
• Uses 82% less energy ⚡
• Runs massive models without GPUs
• Fully open-source (no lock-ins)
• Makes AI actually accessible
This isn’t an upgrade.
This is a shift from “AI for the few” → “AI for everyone.”
If this scales…
Your laptop might soon do what only data centers could.
And that’s when things get interesting🔥
Linke👇
🛠️🌐 L'IA lourde devient gratuite et locale : BitNet b1.58 tue les GPU !
100% open-source, Microsoft Research a tout libéré sous licence MIT
Plus besoin d'une RTX 4090 pour faire tourner un bon modèle… lance-le sur ton vieux laptop, ça marche déjà mieux !
👉 Sans carte graphique, sans cloud, sans facture monstrueuse chez OpenAI ou Google.
Au lieu de stocker chaque paramètre du modèle avec 16 bits de précision (comme presque tous les LLM actuels), BitNet le force à n’utiliser que trois valeurs possibles : -1, 0 ou +1
Mathématiquement, ça représente environ 1,58 bit par paramètre.
👉 Concrètement :
- La taille du modèle explose à la baisse : un modèle de 2–3 milliards de paramètres pèse souvent moins de 1Go (contre 4–6 Go en FP16 classique).
- Les calculs deviennent ultra-simples : exit les multiplications flottantes coûteuses, place aux additions et soustractions rapides → ton CPU (même un vieux Intel ou un Apple M2) accepte !
- Énergie divisée par 3 à 6, parfois jusqu’à 80% d’économies sur x86.
- Vitesse multipliée par 2 à 6 selon le matériel : sur ARM (Mac, smartphones), jusqu’à ×5. Sur PC classique, jusqu’à ×6
Le flagship BitNet b1.58 2B-4T (2 milliards de paramètres entraînés sur 4 trillions de tokens) rivalise sérieusement avec des modèles full-precision de même taille (Llama 3.2 1B, Gemma 3 1B, Qwen 2.5 1.5B) sur les benchmarks classiques :
- Maths
- Raisonnement
- Code
- Compréhension
- Conversation
À partir de quelques milliards de paramètres, la perte due à cette compression extrême devient quasi invisible.
👉 Pourquoi c’est révolutionnaire ?
- IA vraiment privée : tout reste sur ton appareil, rien ne part chez qui que ce soit.
- IA sur téléphone, Raspberry Pi, pays mal connectés : fini le besoin de data center.
- Agents autonomes 24/7 sans payer à chaque requête.
- Fin de la dépendance aux GPU hors de prix : l’IA lourde devient accessible à tous, pas seulement aux Big Tech.
Le code est MIT, les modèles sur Hugging Face, les optimisations s’enchaînent (dernières updates en janvier 2026 boostent encore les perfs CPU).
#OpenSource
🚨 Microsoft’tan yapay zekâ dünyasına büyük bir adım: **BitNet** tamamen açık kaynak olarak yayınlandı.
bitnet.cpp ile artık **100 milyar parametreli** modelleri GPU olmadan, sadece CPU’da çalıştırabiliyorsunuz.
En çarpıcı özellikler:
• %82 daha az enerji tüketimi
• Tamamen 1-bit inference (ağır kuantizasyon)
• 100B+ parametreli modelleri sıradan bilgisayarlara sığdırıyor
• GPU bağımlılığını büyük ölçüde ortadan kaldırıyor
Bu gelişme, özellikle yerel AI (local AI) ve edge computing alanında devrim niteliğinde.
AI’nin daha erişilebilir, daha verimli ve daha sürdürülebilir bir geleceğe adım attığı önemli bir an.
Sizce bu proje NVIDIA’nın egemenliğini sarsar mı?
Yoksa CPU tabanlı AI’nin gerçek başlangıcı mı?
Yorumlarda görüşlerinizi paylaşın. 💻
#BitNet#bitnetcpp#MicrosoftAI#LocalAI#1BitInference#OpenSourceAI#YapayZeka#AI2026
🚨 BREAKING: You can now run a 100B LLM on a single CPU 🤯
No GPU
No cloud costs
No crazy setup
Microsoft’s bitnet.cpp is making it real
It runs 1.58-bit models that are:
⚡ up to 6x faster
🔋 ~80% more energy efficient
🧠 still insanely capable
And the wildest part?
You get 5–7 tokens/sec — basically human reading speed
This isn’t a small upgrade
This is a complete rewrite of how AI runs
We’re moving from:
GPU-heavy, expensive, cloud-only
→ to
Local, cheap, efficient AI anyone can run
Built on llama.cpp with custom kernels, quantization, and parallel optimizations
Translation:
AI is no longer locked behind big tech infra
It’s coming to your laptop
This changes everything
Holy shit 🤯
Microsoft just open-sourced a framework that runs a 100B parameter LLM on a single CPU.
No GPU.
No cloud.
No expensive setup.
Just your laptop.
It’s called BitNet.
And it breaks one of the biggest assumptions in AI.
Here’s the trick:
Most LLMs use 16-bit or 32-bit floats.
BitNet uses:
1.58 bits.
Yes… bits.
Weights are just:
-1, 0, +1
That’s it.
No heavy matrix math.
Just simple integer operations your CPU already handles efficiently.
The result is insane:
• 100B model runs on CPU at 5–7 tokens/sec
• 2–6× faster than llama.cpp on x86
• 82% less energy usage
• 1–5× faster on ARM (MacBooks)
• 16–32× lower memory
The craziest part?
Accuracy barely drops.
Their flagship model (trained on 4 trillion tokens) performs competitively with full-precision models.
They didn’t break the model.
They removed the waste.
What this unlocks:
→ Run LLMs fully offline
→ AI on phones, edge devices, IoT
→ No API costs for inference
→ Works even without reliable internet
MacBook.
Linux.
Windows.
It just runs.
27K+ GitHub stars.
Built by Microsoft Research.
100% open source.
This might be the moment AI stops being cloud-first…
and becomes device-first.
🚨Breaking: Microsoft just broke the AI hardware game.
They dropped bitnet.cpp — 1-bit AI that runs 100B models on your CPU.
No GPU.
82% less energy.
100% open-source.
This isn’t an upgrade.
It’s a takeover. ⚡
Repo: github.com/microsoft/BitN…
🚨Breaking: Microsoft just broke the AI hardware game.
They dropped bitnet.cpp — 1-bit AI that runs 100B models on your CPU.
No GPU.
82% less energy.
100% open-source.
This isn’t an upgrade.
It’s a takeover. ⚡
Repo: github.com/microsoft/BitN…
🚨 Microsoft has solved the biggest problem with AI.
They open-sourced bitnet.cpp. It’s a 1-bit inference framework that runs massive 100B parameter models directly on your CPU without GPUs.
it uses 82% less energy.. 100% open-source.
Microsoft open sourced an inference framework that runs a 100B parameter LLM on a single CPU.
It's called BitNet. And it does what was supposed to be impossible.
No GPU. No cloud. No $10K hardware setup. Just your laptop running a 100-billion parameter model at human reading speed.
Here's how it works:
Every other LLM stores weights in 32-bit or 16-bit floats.
BitNet uses 1.58 bits.
Weights are ternary just -1, 0, or +1. That's it. No floats. No expensive matrix math. Pure integer operations your CPU was already built for.
The result:
- 100B model runs on a single CPU at 5-7 tokens/second
- 2.37x to 6.17x faster than llama.cpp on x86
- 82% lower energy consumption on x86 CPUs
- 1.37x to 5.07x speedup on ARM (your MacBook)
- Memory drops by 16-32x vs full-precision models
The wildest part:
Accuracy barely moves.
BitNet b1.58 2B4T their flagship model was trained on 4 trillion tokens and benchmarks competitively against full-precision models of the same size. The quantization isn't destroying quality. It's just removing the bloat.
What this actually means:
- Run AI completely offline. Your data never leaves your machine
- Deploy LLMs on phones, IoT devices, edge hardware
- No more cloud API bills for inference
- AI in regions with no reliable internet
The model supports ARM and x86. Works on your MacBook, your Linux box, your Windows machine.
27.4K GitHub stars. 2.2K forks. Built by Microsoft Research.
100% Open Source. MIT License.