Sabitlenmiş Tweet

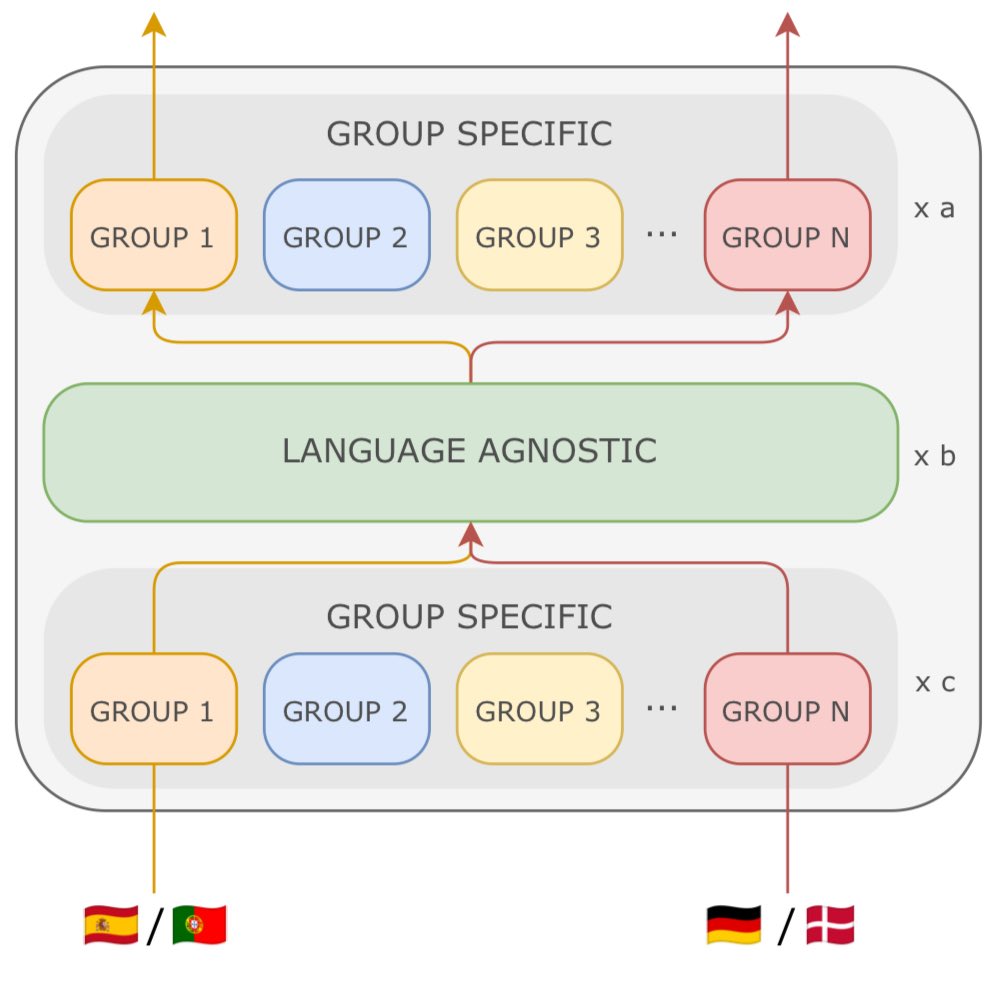
We introduce FAT5 (Flash Attention T5) ⚡
An implementation of T5 in PyTorch with UL2 objective optimized for GPGPU for both training and inference thanks to 13 differents optimizations.
Unroll to find out more! 🧵👇 [1/8]
GIF
English