Sabitlenmiş Tweet

Binx
2.7K posts

@BinxNet
Backend SWE | Tinkerer | Data Surfer

I locked myself in a room for 48 hours and didn't let myself leave until I had 3D meshes that rivaled meshy running on 12gb of VRAM. LET HIM COOK.😤


A few months ago I was curious to know how much Anna's Archive was charging AI developers for access to their massive library of pirated works for training - so I emailed them saying I was interested in buying access. Here is their reply. They are charging $200,000 (payable via crypto, of course). You get high-speed access to the full collection. This includes more than 60 million books. (This is also the group that recently stole Spotify's entire music catalog, so expect this to be available to high rollers too.) This is the collection Nvidia is accused of accessing for training. Training on pirated works is rife in the AI industry. It's been embraced by some of the biggest AI companies in their greed-fuelled race to win the AI market. When they claim what they're doing is somehow fair, remember that not only is it theft (which is bad enough) - it supports further theft by funding pirates. We desperately need a hard reset in the AI industry. It must turn away from theft, and start paying the people whose work it relies on.



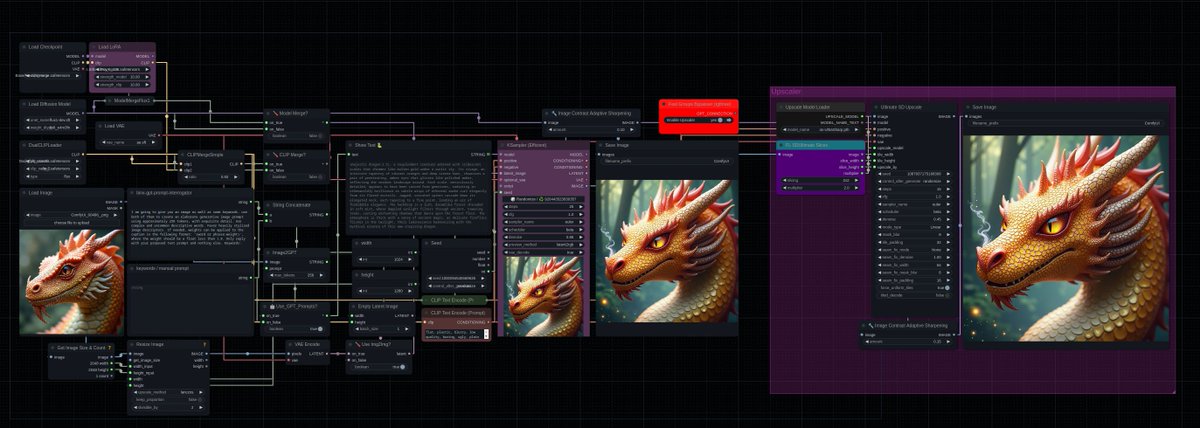
This is some of the craziest stuff you can make with AI right now. All powered by the new LTX Audio to Video. Everything you need to know is down below 👇

"Software Engineering Will Be Automatable in 12 Months," Anthropic CEO Dario Amodei predicts that AI models will be able to do 'most, maybe all' of what software engineers do end-to-end within 6 to 12 months, shifting engineers to editors.



It's funny how radically the behavior of humans changes when you hold them accountable for what the LLMs generate.



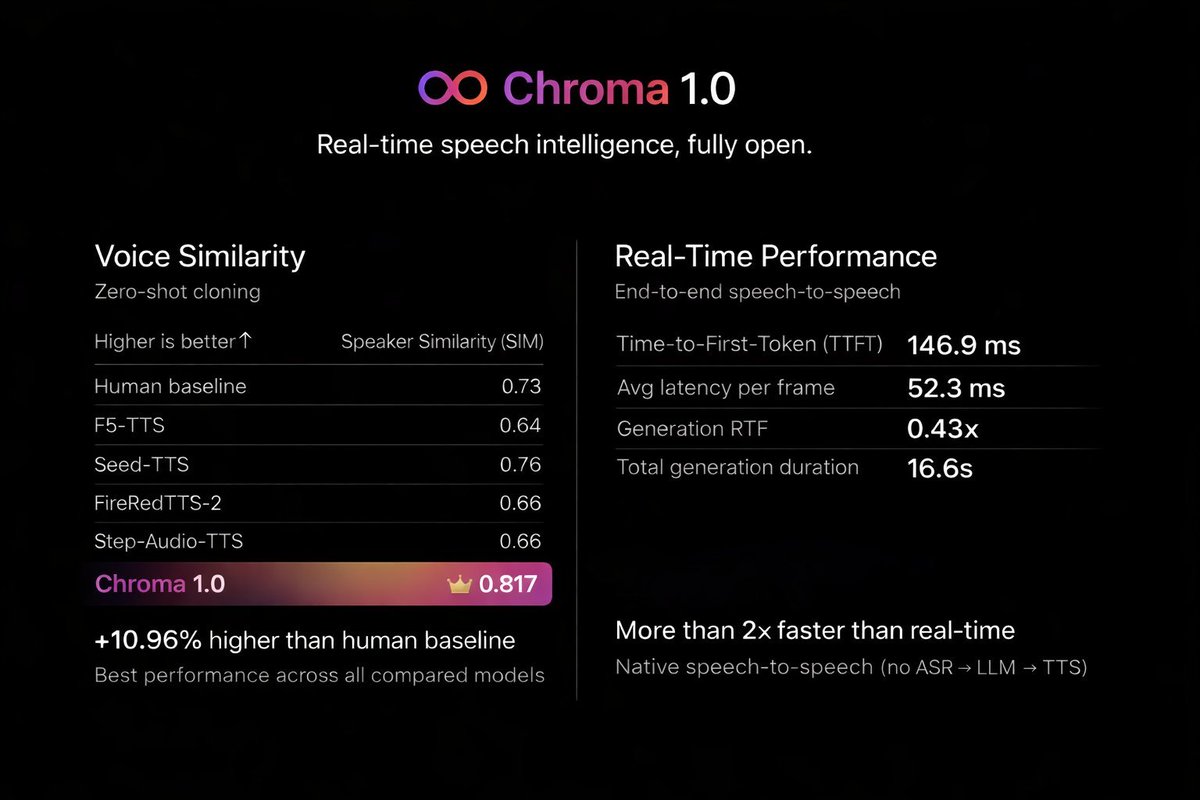
Today we’re releasing Chroma 1.0 → the world first open-source, end-to-end, real-time speech-to-speech model → with personalized voice cloning Trained by FlashLabs. Deployed on FlashAI👉 flashlabs.ai/flashai-voice-… An open research-grade alternative to the @OpenAI Realtime model. Voice Test dubbing @elonmusk and @lexfridman: youtube.com/watch?v=AOMmxT… 🔥What’s real (evals and benchmarks attached): ⚡ <150ms TTFT (end-to-end) 🎙️ Native speech-to-speech (no ASR → LLM → TTS pipeline) 🧬 Few-second reference → high-fidelity voice cloning 📈 SIM = 0.817 → +10.96% vs human baseline (0.73) → Best among open & closed baselines 🧠 Strong reasoning & dialogue with just 4B params (@Alibaba_Qwen 2.5-Omni-3B, Llama 3, and Mimi) 🔓 Fully open-source (code + weights) With SGLang @lmsysorg enabled: • 🧠 Thinker TTFT ↓ ~15% • ⏱️ End-to-end TTFT ~135ms • 🔊 RTF ≈ 0.47–0.51 ( >2× faster than real-time ) 📘 SGLang Cookbook: cookbook.sglang.io/docs/autoregre… 📄 Paper + benchmarks: arxiv.org/abs/2601.11141 🤗 Models: huggingface.co/FlashLabs/Chro… 💻 Inference code: github.com/FlashLabs-AI-C… 🔁 RT if you believe real-time AI should be open 💬 Reply if you’re building on Conversational Voice AI products


🚨Pics from North Minneapolis last night where rioters destroyed federal vehicles and stole firearms, ammunition and sensitive documents inside. All captured on livestreams.