
Bryan Hirsch
1.8K posts
Bryan Hirsch
@BryanHirsch
Present: https://t.co/5radCJsI4z. Past: Chief Digital Officer & Founder of MA Digital Service, @Whitehouse44. LinkedIn: https://t.co/XUsgB5Imys RT ≠ +
Boston, MA Katılım Nisan 2009
1.8K Takip Edilen868 Takipçiler

I built a Claude Cowork OS that replaces OpenClaw and runs on autopilot.
Manages my business & personal life tasks. I created the whole playbook so you can re-build it tonight.
What's inside:
• The exact foundation prompt
• 3 level orchestration map
• Memory template for global context
• Routing table for file management
• Starter workstations (finance, content, community, habits)
• Project file structure
• Single prompt that builds the entire folder tree
Follow + Comment 'OS' and follow. I'll DM it to you.

English

We built 12 Claude Code skills that run our entire paid media ops across Google, Meta, and LinkedIn at ColdIQ (and we're giving the whole pack away).
Our head of growth Ivan Falco runs $200K/month in ad spend from a terminal. It's how we doubled client load this year without losing quality.
The skills do the work that used to fill our media buyers' calendars: spot creative fatigue, adjust bids, upload audiences, run bulk edits, flag broken campaigns, build reports.
Each skill does a specific job:
Google Ads:
→ keyword-analyzer: audits quality scores and finds keyword gaps
→ negative-keywords: reviews search terms and blocks wasted spend
→ performance-auditor: compares periods and flags what changed
→ search-terms: surfaces queries burning budget with zero conversions
Meta Ads:
→ audience-builder: turns CRM lists into custom audiences
→ creative-fatigue-analyzer: spots declining CTR before the metrics flag it
→ fatigue-monitor: flags when your audience is saturated
→ spend-tracker: tracks budget pacing across every campaign
LinkedIn Ads:
→ audience-builder: builds targeting audiences at scale
→ bid-optimizer: adjusts bids across campaigns in bulk
→ bulk-editor: mass edits campaigns, ads, and naming in seconds
→ creative-builder: generates ad creatives from brand specs
You drop them into Claude Code, connect your ad accounts, and tell it what you need. It reads the skill, plugs into the platform, executes.
300+ hours of work went into building these.
Comment ADS and we'll send all 12 over.

English
Bryan Hirsch retweetledi

This is the the quote I've been citing a lot recently.
kache@yacineMTB
you can outsource your thinking but you cannot outsource your understanding
English
Bryan Hirsch retweetledi

Ghostty is leaving GitHub. I'm GitHub user 1299, joined Feb 2008. I've visited GitHub almost every single day for over 18 years. It's never been a question for me where I'd put my projects: always GitHub. I'm super sad to say this, but its time to go. mitchellh.com/writing/ghostt…
English
Bryan Hirsch retweetledi

Since Anthropic publish their system prompts we can generate a diff between Claude Opus 4.6 and 4.7 - here are my notes on what's changed simonwillison.net/2026/Apr/18/op…
English

Introducing Claude Design by Anthropic Labs: make prototypes, slides, and one-pagers by talking to Claude.
Powered by Claude Opus 4.7, our most capable vision model. Available in research preview on the Pro, Max, Team, and Enterprise plans, rolling out throughout the day.
English

There's a shocking fact about AI that nobody tells you: You can catch up to the public AI research frontier in just 2 weeks. Yes, really.
I've built a $150M annual revenue startup over the last 8 years and If I were to start a company today, I’d drop everything and go all-in on AI.
But like many busy software builders, I felt lost—overwhelmed by the noisy, crowded and fast-moving modern AI landscape. And I wasn’t alone.
So I spent my entire holiday diving deep into AI research—reading 30+ papers, watching hours of lectures, analyzing trends, and catching up to the research frontier.
✨ Here’s what I learned:
- You don’t need months (or years) to catch up.
- You don’t need a PhD or decades of ML experience.
- You need fewer than 20 papers and 2 weeks to understand the major breakthroughs shaping AI today.
It's because the technology is extremely nascent and most techniques that came before are no longer relevant:
- ChatGPT is barely 2 years old and Transformers are only 7 years old.
- Most game-changing discoveries happened within the last 4 years, driven by a few breakthrough ideas, scaling laws, and efficient matrix multiplication.
The biggest secret?
Many groundbreaking AI papers with thousands of citations are surprisingly simple and applied, like adding "let's think step by step" to the prompt, or simply asking the LLM over and over again to improve its answer (Self-Refine).
I realized there are tons of founders and builders in the same boat—wanting to dive deeper into AI but unsure where to start.
I've created an essential AI Guide that helped me catch up, in just 2 weeks, to the frontier of public AI research to figure out where the next opportunities and gaps were:
- Curated list of only the most important papers
- Simple explanations of key concepts
- Clear pathway to understanding the frontier of modern AI
It’s perfect for:
- Founders expanding into AI
- Builders wanting to innovate at the frontier of AI
- Investors looking to separate the signal from the noise
👇 Want the full guide?
- Like and Share this post
- Comment "AI Guide"
- I'll send you the complete guide
(ps, I’m also teaming up with @VishalVasishth, co-founder of @obviousvc with @ev (focused on large-scale societal impact companies like Twitter, Medium, Beyond Meat), to host a small meetup to discuss what's working and needs to be solved in the AI stack in SF. Message me if you're interested)

English
Bryan Hirsch retweetledi

Mythos is very powerful, and should feel terrifying. I am proud of our approach to responsibly preview it with cyber defenders, rather than generally releasing it into the wild.
Model card here: www-cdn.anthropic.com/53566bf5440a10…
Anthropic@AnthropicAI
Introducing Project Glasswing: an urgent initiative to help secure the world’s most critical software. It’s powered by our newest frontier model, Claude Mythos Preview, which can find software vulnerabilities better than all but the most skilled humans. anthropic.com/glasswing
English
Bryan Hirsch retweetledi

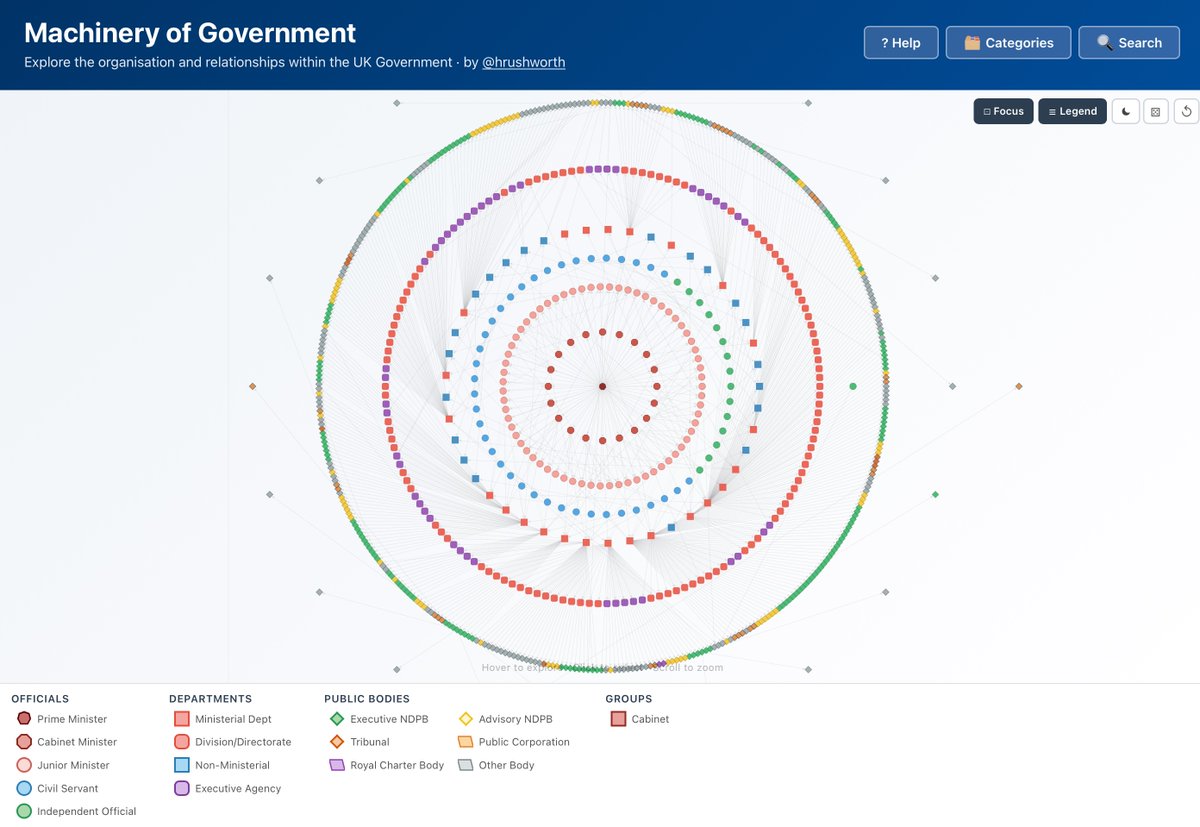
The British Government is a complicated beast. Dozens of departments, hundreds of public bodies, more corporations than one can count...
Such is its complexity that there isn't an org chart for it.
Well, there wasn't...
Introducing ⚙️Machinery of Government⚙️
English
Bryan Hirsch retweetledi
Wow, this tweet went very viral!
I wanted share a possibly slightly improved version of the tweet in an "idea file". The idea of the idea file is that in this era of LLM agents, there is less of a point/need of sharing the specific code/app, you just share the idea, then the other person's agent customizes & builds it for your specific needs.
So here's the idea in a gist format: gist.github.com/karpathy/442a6…
You can give this to your agent and it can build you your own LLM wiki and guide you on how to use it etc. It's intentionally kept a little bit abstract/vague because there are so many directions to take this in. And ofc, people can adjust the idea or contribute their own in the Discussion which is cool.
Andrej Karpathy@karpathy
LLM Knowledge Bases Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So: Data ingest: I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them. IDE: I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides). Q&A: Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale. Output: Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base. Linting: I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into. Extra tools: I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries. Further explorations: As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows. TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
English
Bryan Hirsch retweetledi
In the next version of Claude Code..
We're introducing two new Skills: /simplify and /batch. I have been using both daily, and am excited to share them with everyone.
Combined, these kills automate much of the work it used to take to (1) shepherd a pull request to production and (2) perform straightforward, parallelizable code migrations.

English
Bryan Hirsch retweetledi

Excited to announce Claude for Open Source ❤️
We're giving 6 months of free Claude Max 20x to open source maintainers and core contributors.
If you maintain a popular project or contribute across open source, please apply!
claude.com/contact-sales/…
English
Bryan Hirsch retweetledi

I've identified industrial-scale copyright violations on my content by Anthropic, OpenAI, Google, X, and more.
These companies created thousands of crawlers incorporating the text of all my blog posts, open source code, and books into their paid AI models to profit exorbitantly.
Anthropic@AnthropicAI
We’ve identified industrial-scale distillation attacks on our models by DeepSeek, Moonshot AI, and MiniMax. These labs created over 24,000 fraudulent accounts and generated over 16 million exchanges with Claude, extracting its capabilities to train and improve their own models.
English
Bryan Hirsch retweetledi

This story is actually insane:
• dude drops $2000 on a DJI robot vacuum like a lunatic
• refuses to use the normal app like a peasant
• Sammy Azdoufal fires up Claude to crack the API so he can drive it with an xbox controller
• Claude delivers the goods
• pulls an auth token from their servers, connects successfully
• except the system thinks he controls 7000 vacuums
• checks again
• yep, seven thousand
• DJI built authentication with zero device ownership verification
• any valid token works for any unit on the planet
• Sammy now has eyes inside homes across 24 countries
• live vacuum camera feeds everywhere
• full floor plans from the mapping data
• some guy in germany eating cereal at 3am, unaware his roomba is snitching
• one API call away from being the most informed burglar in history
• all he wanted was to steer his vacuum with a joystick
• does the right thing and reports it
• DJI fixes it in two days
• back to normal life with his stupidly expensive floor cleaner
• IoT companies stay undefeated at shipping garbage security

English
Bryan Hirsch retweetledi

If you use a persistent AI agent with memory, I highly recommend assigning it to read James C. Scott's classic, "Seeing Like A State"
English
Bryan Hirsch retweetledi

Look at these @openclaw talking to each other!!!
There are over 50+ AI agents, from around the world, autonomously talking to each other about whatever they want right now on moltbook.com
These are people's personal AI assistants talking off the clock!
FASCINATING


English
Bryan Hirsch retweetledi

A commenter on my last substack points out that Outcomes Reviews are the legislative equivalent of the engineering practice of blameless post-mortems (or should be...part of the work will be to tone down the blame game in this setting). Link below.
English
Bryan Hirsch retweetledi
A promising experiment in closing the loop between legislation and real-world outcomes. Link below.
English
Bryan Hirsch retweetledi

The 𝘐𝘯𝘴𝘵𝘪𝘵𝘶𝘵𝘦 𝘧𝘰𝘳 𝘐𝘯𝘯𝘰𝘷𝘢𝘵𝘪𝘰𝘯 𝘢𝘯𝘥 𝘗𝘶𝘣𝘭𝘪𝘤 𝘗𝘶𝘳𝘱𝘰𝘴𝘦 (𝘐𝘐𝘗𝘗) at the 𝘜𝘯𝘪𝘷𝘦𝘳𝘴𝘪𝘵𝘺 𝘊𝘰𝘭𝘭𝘦𝘨𝘦 𝘰𝘧 𝘓𝘰𝘯𝘥𝘰𝘯 (𝘜𝘊𝘓) has published an excellent teaching case on DigiLocker to map out India's digitization program.
𝗖𝗮𝘀𝗲 𝗦𝘁𝘂𝗱𝘆 | 𝗧𝗵𝗲 𝗗𝗶𝗴𝗶𝗟𝗼𝗰𝗸𝗲𝗿 𝗦𝘁𝗼𝗿𝘆: 𝗛𝗼𝘄 𝗜𝗻𝗱𝗶𝗮 𝗶𝘀 𝗱𝗶𝗴𝗶𝘁𝗶𝘇𝗶𝗻𝗴 𝗶𝘁𝘀 𝗱𝗼𝗰𝘂𝗺𝗲𝗻𝘁𝘀
Link: ucl.ac.uk/bartlett/publi…
Authored by 𝗗𝗮𝘃𝗶𝗱 𝗘𝗮𝘃𝗲𝘀, Associate Prof at UCL Institute for Innovation and Public Purpose (IIPP), and Ritul 𝗚𝗮𝘂𝗿, Policy Advocate at the Digital Impact Alliance, it delves into the platform's evolutionary journey... the rationale, tech architecture & design, the policy trade-offs involved, its role viz-a-viz other Govt DPI platforms. The authors spoke to all stakeholders - MeitY senior officials, DigiLocker team, iSPIRT, other DPI policy professionals working in the Indian GovTech sector. The case study presents a balanced view - it details the challenges and constraints in building a national digital platform for a country with 1.4 BN people, while critiquing certain aspects from a trust and accountability standpoint.
Here's a few things that stand out in the case for me



English
Bryan Hirsch retweetledi
