Bub
1.4K posts







🗣️ Alvaro Arbeloa: “Jude Bellingham is a VERY intelligent player. He always knows everything that is happening. I am very happy he is available.”
🚨 BREAKING: Jude Bellingham is BACK! Real Madrid expect him to be READY to face Atletico Madrid on Sunday. @guillermorai_





Hermes Agent v0.3.0 ☤ 248 PRs. 15 contributors. 5 days. • Real-time streaming across CLI and all platforms • First-class plugin architecture, package and share tools+commands+skills • /browser connect to live Chrome via CDP • @vercel AI Gateway model provider • @browser_use browser tool provider • VS Code, Zed, and JetBrains integration • Voice mode with local Whisper • PII redaction everywhere 9 new skills. 50+ bug fixes. Much more in the full changelog.

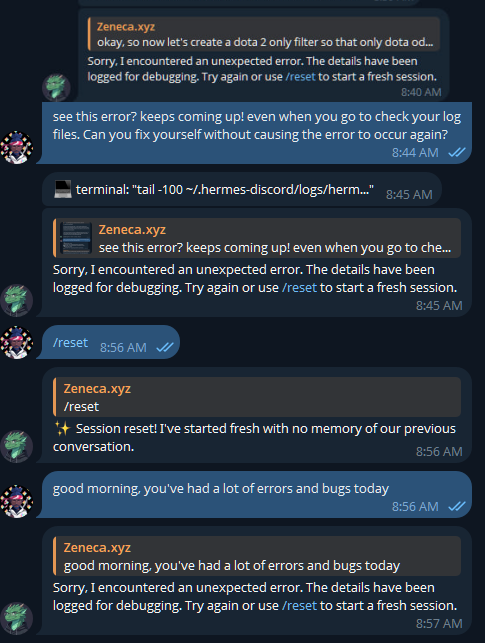

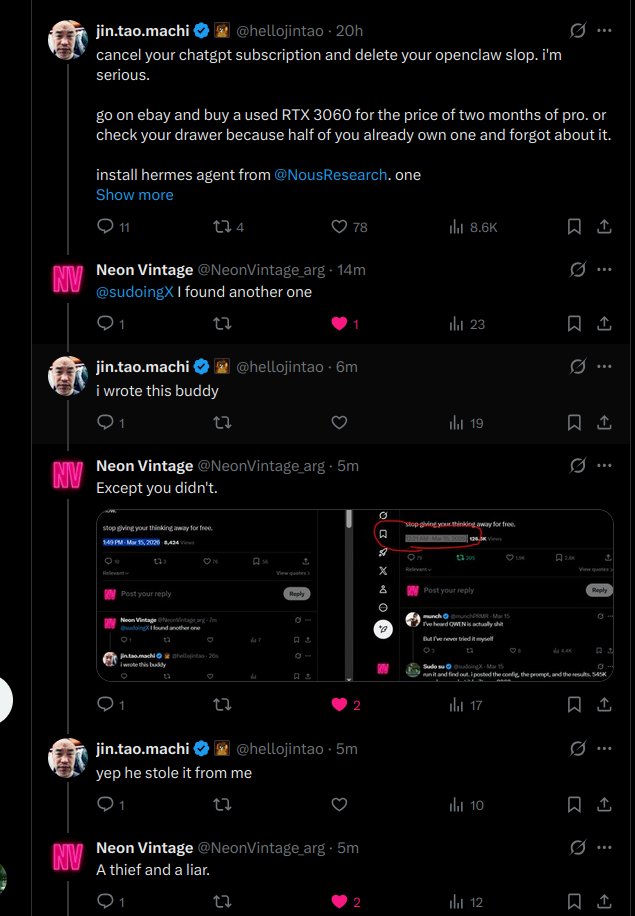

cancel your chatgpt subscription and delete your openclaw slop. i'm serious. go on ebay and buy a used RTX 3060 for the price of two months of pro. or check your drawer because half of you already own one and forgot about it. install hermes agent from @NousResearch. one framework, 31 tools, file operations, terminal, browser, code execution. connect it to your local llama.cpp server running qwen 3.5 9B Q4. total download is 5.3 gigs. that's it. that's the whole setup. every experiment you hesitated to run on API. every project you shelved because you didn't want your data on someone else's server. every late night idea you didn't test because you hit your rate limit. all of that is gone. runs 24/7 on your electricity. your machine. your data never leaves your house. connect it to telegram if you want it on your phone. hook up whatever tools you need. the model thinks at 29 tok/s with 128K context and it never bills you. qwen 3.5 9B and one RTX 3060 is the setup most people will never try because they've been trained to believe intelligence has to come from a datacenter. it doesn't. it runs on 12 gigs of VRAM under your desk right now. stop giving your thinking away for free.
