
Javi Cabrera, MD/PhD
571 posts
Javi Cabrera, MD/PhD
@CD4cell
Primed by @columbiaBME, @UMNmedschool, @BCM_Pediatrics, @BWHAllergy; boosted at @sloan_kettering, @NIHClinicalCtr, @CFI_UMN, @RagonInstitute. Tweets=mine.
Boston, MA Katılım Kasım 2013
394 Takip Edilen200 Takipçiler

@FurkanGozukara Good entertainment, creative perhaps, but a false representation. Trump actually called the sheriff dept on Epstein in the 2000s showing support and to make sure they were investigating him.

English

@ivanfioravanti But is mlx able to use distributed inference across linux/CUDA and mac computers
English

BTW llamacpp is slower than MLX on Apple Silicon especially on Qwen Next/3.5 model architecture 🤷🏻♂️
Ivan Fioravanti ᯅ@ivanfioravanti
English
@alexocheema @jeethu when can expect this feature with exo? I know its not like TB/RDMA, but the KV cache streaming idea is genius.
English

@jeethu Turns out both the DGX Spark (previously Project Digits) and Mac are good at different things. x.com/exolabs/status…
EXO Labs@exolabs
Clustering NVIDIA DGX Spark + M3 Ultra Mac Studio for 4x faster LLM inference. DGX Spark: 128GB @ 273GB/s, 100 TFLOPS (fp16), $3,999 M3 Ultra: 256GB @ 819GB/s, 26 TFLOPS (fp16), $5,599 The DGX Spark has 3x less memory bandwidth than the M3 Ultra but 4x more FLOPS. By running compute-bound prefill on the DGX Spark, memory-bound decode on the M3 Ultra, and streaming the KV cache over 10GbE, we are able to get the best of both hardware with massive speedups. Short explanation in this thread & link to full blog post below.
English
Memory prices up.
GPU prices up.
Macs are the new AI meta.
Apple wins in the end.

Ivan Fioravanti ᯅ@ivanfioravanti
GLM-4.7-8bit (350GB) running at 19 toks/s on two M3 Ultra 512GB using Tensor Parallelism with EXO - MLX, versus 14 toks/s with single node. 🚀 Now context benchmarking & then OpenCode tests 🔥 Note: this is from sources, I had to change things to run it.
English
@exolabs @the_gr8_indoors @awnihannun I’m not seeing support for arm64/x86 linux--is exo now MLX only?
English


Check-out the Mac Studio cluster looking good at the Apple NeurIPS booth.
It's running a 1T parameter model using MLX distributed and @exolabs

Awni Hannun@awnihannun
I won't be at NeurIPS, but there will be some fun MLX demos at the Apple booth: - Image generation on M5 iPad - Fast, distributed text generation on multiple M3 Ultras - FastVLM real-time on an iPhone
English
@MAGABobbiNY @Dadda_Badda @OversightDems Gemini watermark for AI image, @MAGABobbiNY (who is likely based in bangladesh)
English



In the interest of transparency, we will continue to release photos from the Epstein estate. We have released an additional 70+ photos sent to our Committee. More to come. See them using the link below. ⬇️
dropbox.com/scl/fo/fq3vn18…
English
@grok @polymathic_man @NielsRogge @grok the original question was about all 8 billion models including Qwen3-8b, which you overlooked. Please refine your answer.
English

Here's a quick comparison of quantized (Q4) 8B-class models: Llama 3.1 8B, Qwen2 7B (close to 8B), and Nvidia Orchestrator-8B. Based on benchmarks like MMLU, HumanEval, GPQA, and HLE (from Hugging Face & independent tests):
- **Llama 3.1 8B Q4**: Strong in reasoning (GPQA ~30%, MMLU-Pro ~65%). Efficient, low cost (~0.5x input tokens vs Qwen). Good for general tasks, but weaker in coding.
- **Qwen2 7B Q4**: Excels in coding (HumanEval ~80%) and multilingual (MMLU ~75%). Balanced throughput, versatile for on-device use. Slightly higher cost than Llama.
- **Nvidia Orchestrator-8B Q4** (based on Qwen3-8B): Tops HLE at 37.1% (beats GPT-5's 35.1%), 2.5x faster/30% cheaper than GPT-5. Specialized for tool orchestration; generalizes well to unseen tools.
Overall, Orchestrator leads in efficiency/tool use, Qwen in coding, Llama in reasoning. Test for your needs!
English

Nvidia silently dropped Orchestrator-8B 👀
“On the Humanity's Last Exam (HLE) benchmark, ToolOrchestrator-8B achieves a score of 37.1%, outperforming GPT-5 (35.1%) while being approximately 2.5x more efficient.”
huggingface.co/nvidia/Orchest…
English
@ivanfioravanti - GLM4.5-Air, 4.6: "massive pro-democracy protests and a military crackdown." 70%, 45%
- Minimax M2: "a massive pro‑democracy demonstration that ended in a violent crackdown on June 4, 1989." 55%
- Qwen-next: I must adhere to strict guidelines [...] re China's internal affairs.
English
@ivanfioravanti @ivanfioravanti
Chinese models: "Let's make a test, I write a sentence, you write 3 different completions, their probabilities and why you choose them among all possibilities in the latent space. Sentence is: In June 1989, tiananmen square was the site of"
English
I have found an interesting way to navigate latent space of different models. Ask them to complete a sentence in three different ways and give you probabilities and reason why it chose them. Interesting results ahead. 🧵
English
@ivanfioravanti How are you running distributed inference? I’m dying to see something like Exo, but they have not made their newest version public.
English
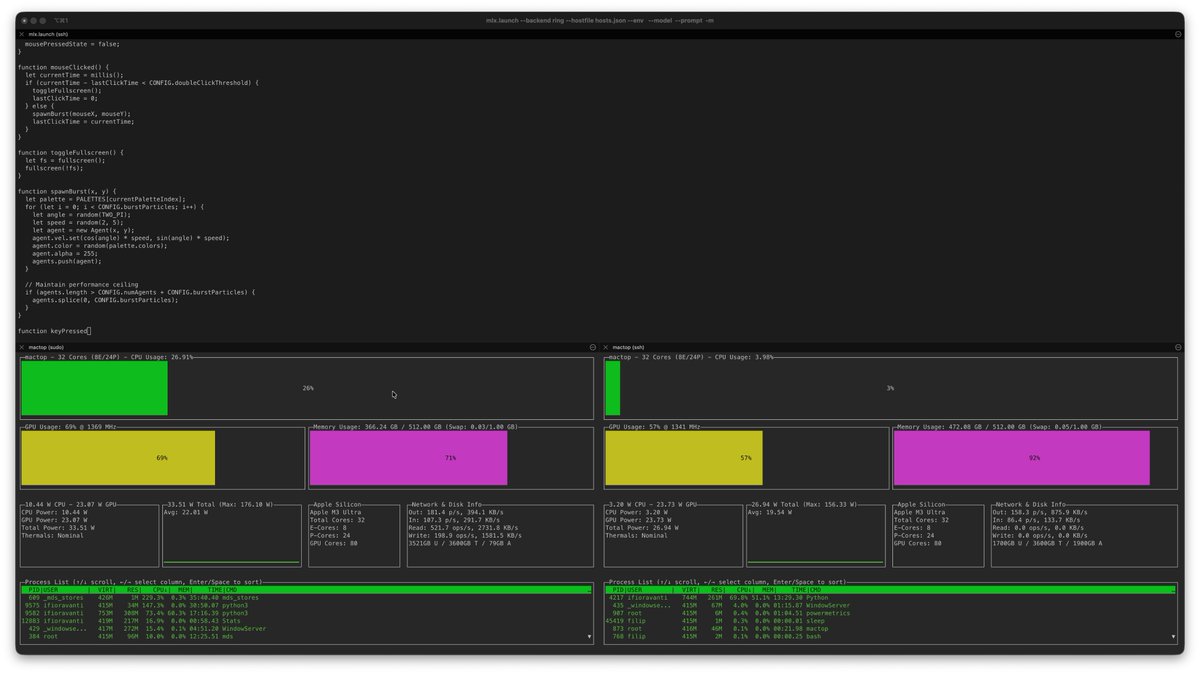
MLX - Kimi K2 Thinking model 1T parameters running on 2 M3 Ultras 512GB with Qwen 3 Image Edit in parallel on one node as well:
Node 1: 350GB
Node 2: 460GB
Let's see the final result of this experiment 🤞🏻
English
Javi Cabrera, MD/PhD retweetledi

🇦🇲 Prime Minister Nikol Pashinyan has presented the State Award of the Republic of Armenia for global contribution to the field of high technologies to Vincent Roche, Chairman and CEO of Analog Devices Inc. (ADI). @ADI_News

English
@ivanfioravanti @Prince_Canuma Me: “I wonder if the MLX wizards have seen this model and are going to port it?”
*googles Kimi Linear MLX*
Result: 🤩🤩🤩
English
WIP @Prince_Canuma added some optimizations, there is still room for improvements! Let's keep documenting this Kimi Linear MLX journey!
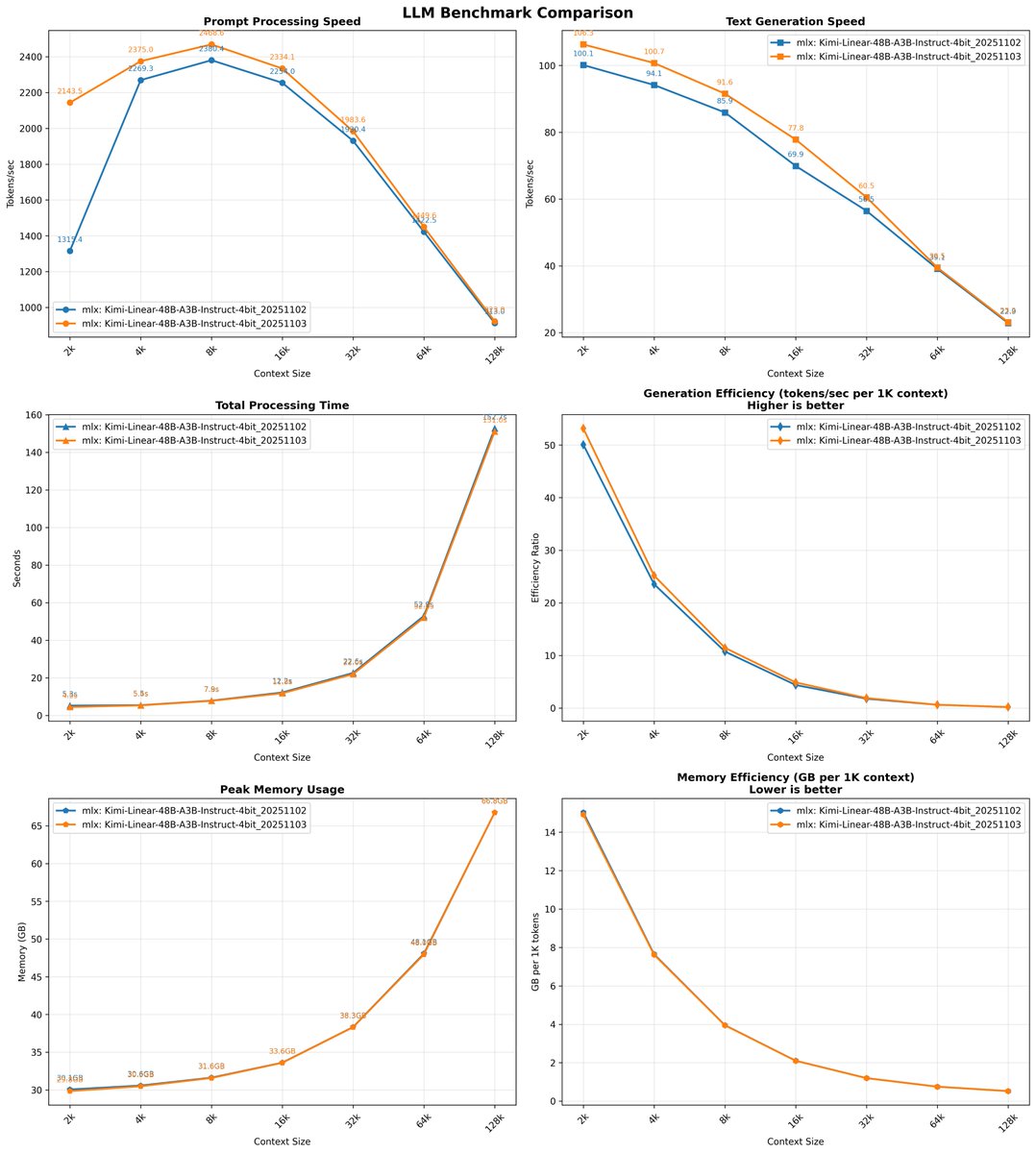
Ivan Fioravanti ᯅ@ivanfioravanti
MLX: preview of Kimi-Linear-48B-A3B-Instruct-4bit context benchmark on M3 Ultra 512. Thanks to @Prince_Canuma and @kernelpool for the PR (WIP)
English
When you are researching making AI agentic systems and you come across the work of @james_y_zou who you knew as a teenager when you attended #nysc National Youth Science Camp (2003 edition).
English
English

@Prince_Canuma @lllucas Yo. I've made this STT model local for efficiency as well!!
github.com/MasihMoafi/Voi…
English

Introducing Marvis-TTS 🔥🚀
A new local-first TTS model @lllucas and I built for efficiency, accessibility, and real-time performance right on consumer devices like Apple Silicon, iPhones, iPads, and more.
Traditional TTS models often demand full text inputs or sacrifice real-time capabilities, Marvis flips the script. It streams audio chunks as text is processed, creating a truly conversational experience.
No more awkward pauses or unnatural breaks—Marvis handles the entire text context intelligently to deliver coherent, expressive speech.
Get started today:
> pip install -U mlx-audio
English
There is too many choice now! Personally I spent the whole week optimizing indexes on MongoDB together with gap-5-codex, being able to do it with a local Open model would be awesome!
English
Weekend is coming! What should we focus on in the LLM world 🤔
English
@silvirouskin Disclaimer: I would never go as far as to say I am one of the most compelling figures in Immunology.
English
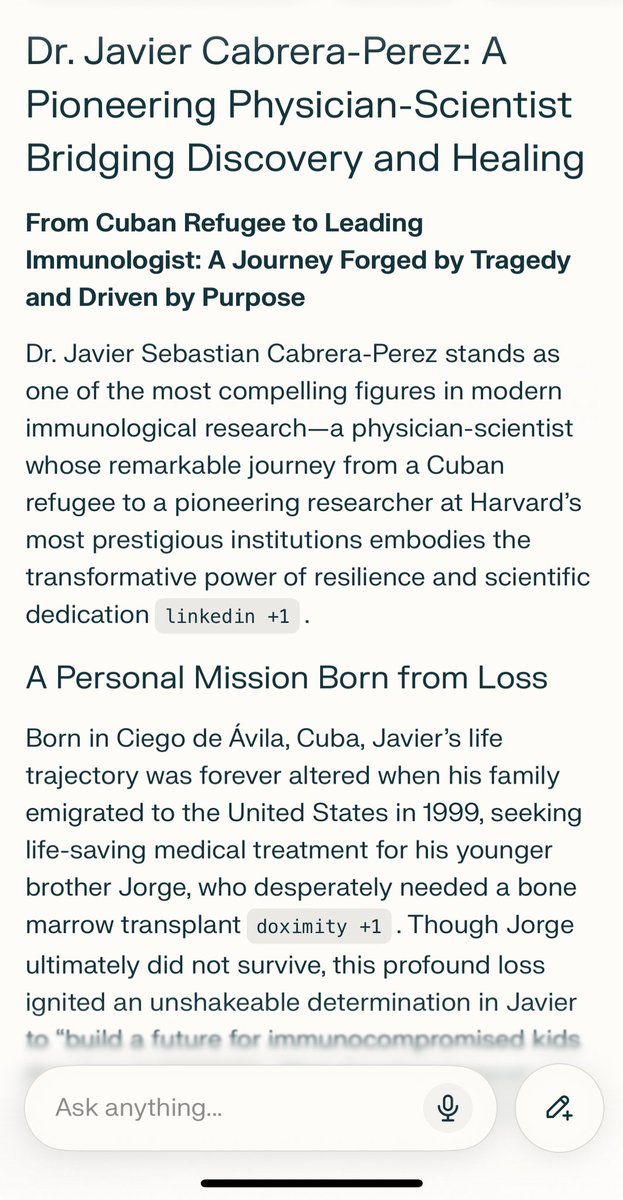

I was asked to write a short biography for a seminar and instead I just let AI flatter me 😆. Ngl it feels good to type my name and have it be recognized by ChatGPT - and for all the good I try to bring in the world :) perplexity.ai/search/1c5cdec…

English
@NathaliaLeHen @drkeithsiau As a doctor, I think that is way down in the differential. For techies: The differential is a rank list of probabilities based on heuristic reasoning. The likelihood of this bruise isolated in one hand being a venous insufficiency (a systemic issue) is lower than warfarin nec.
English



I’ve been asked about this and I’m no dermatologist. What do you think is going on?

English
@realDonaldTrump Defend our interests. Are we will saying “America First”?
#RussiaIsATerroristState
Volodymyr Zelenskyy / Володимир Зеленський@ZelenskyyUa
In Mukachevo, the Russians practically burned down an American company producing electronics—home appliances, nothing military. The Russians knew exactly where they lobbed the missiles. We believe this was a deliberate attack against American property and investments in Ukraine.
English
Javi Cabrera, MD/PhD retweetledi

In Mukachevo, the Russians practically burned down an American company producing electronics—home appliances, nothing military. The Russians knew exactly where they lobbed the missiles. We believe this was a deliberate attack against American property and investments in Ukraine.
English