Sabitlenmiş Tweet

Vault
2.7K posts

@CallmeVault
Travel Photographer, Crypto Enthusiast, Web3 dev 🇵🇹

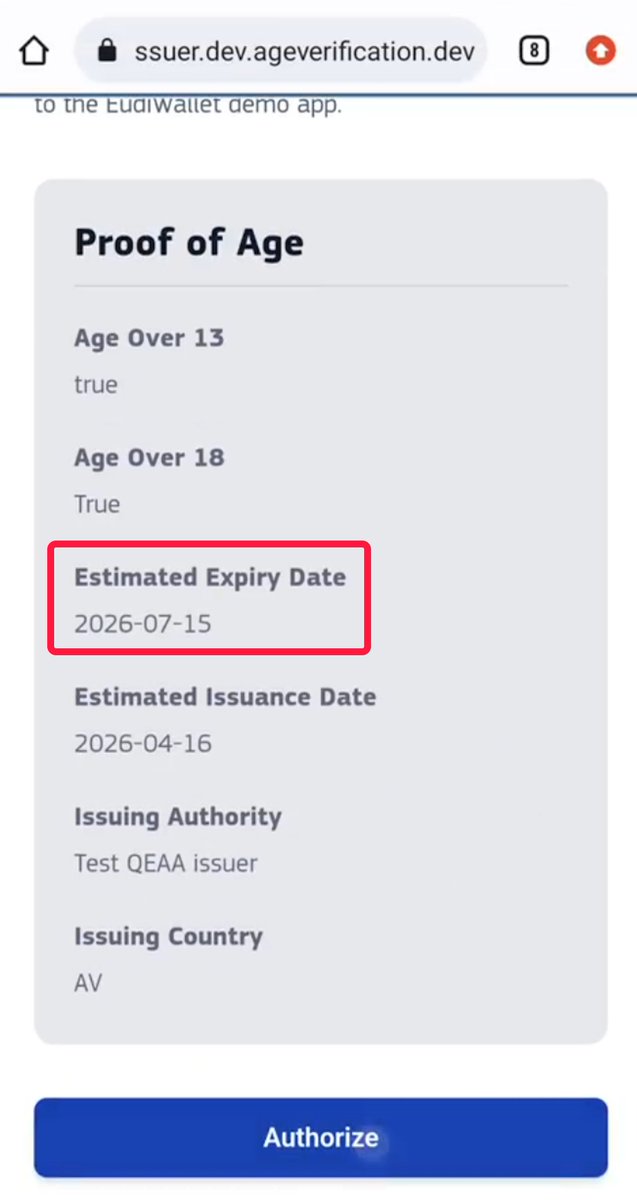
Hacking the #EU #AgeVerification app in under 2 minutes. During setup, the app asks you to create a PIN. After entry, the app *encrypts* it and saves it in the shared_prefs directory. 1. It shouldn't be encrypted at all - that's a really poor design. 2. It's not cryptographically tied to the vault which contains the identity data. So, an attacker can simply remove the PinEnc/PinIV values from the shared_prefs file and restart the app. After choosing a different PIN, the app presents credentials created under the old profile and let's the attacker present them as valid. Other issues: 1. Rate limiting is an incrementing number in the same config file. Just reset it to 0 and keep trying. 2. "UseBiometricAuth" is a boolean, also in the same file. Set it to false and it just skips that step. Seriously @vonderleyen - this product will be the catalyst for an enormous breach at some point. It's just a matter of time.




LLM Knowledge Bases Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So: Data ingest: I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them. IDE: I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides). Q&A: Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale. Output: Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base. Linting: I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into. Extra tools: I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries. Further explorations: As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows. TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.

if you don't have these in your configs you're ngmi


Starting Thursday, we'll be updating our revenue sharing incentives to better reward the content we want on X: We will be giving more weight to impressions from your home region—to encourage content that resonates with people in your country, in neighboring countries and people who speak your language. While we appreciate everyone's opinion on American politics, we hope this will disincentivize gaming the attention of US or Japanese accounts and instead, drive diverse conversations on the platform. We invite creators to start building an audience locally. X will be a much richer community when there's relevant posts for people in all parts of the world.


I hit my limits very quick this week - even with 20x pro plan. It makes my claude code unusable A good reason to do more stuff with Codex!