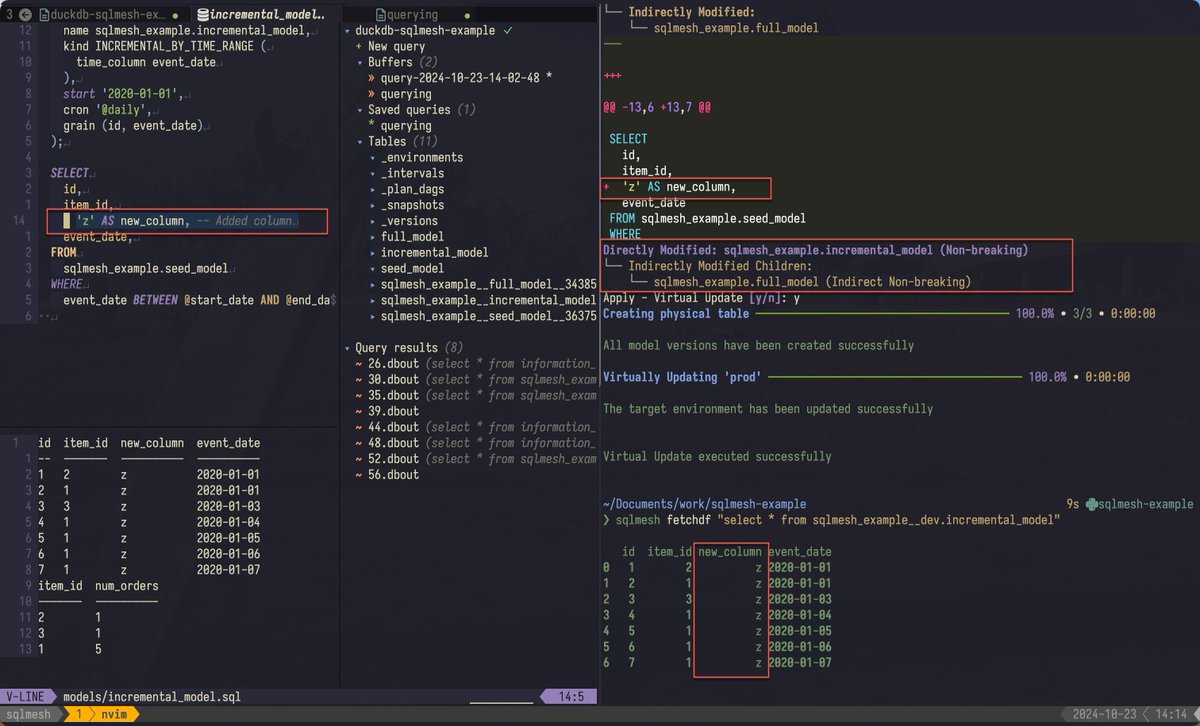
SQLMesh is a Python framework that makes writing and orchestrating SQL easier. All you have to do is write SQL and SQLMesh will figure out the rest. It can find dependencies automatically (no need for ref). It understands what has been done and what needs to be done (cron and version tracking). It even performs syntax checking and validations so you don't always have to send your queries to the warehouse.
But I guess if you are truly five years old, it'd be something like.
Your mommy and daddy help companies understand what's going on every day. When people buy things on the internet, computers get information. SQLMesh helps your mommy and daddy turn that information into numbers so that they can look at them in pretty pictures to make decisions.
English