Vasilije@tricalt
Introducing Cognee v1.0: a major breakthrough in agentic intelligence.
It is 145% better than Opus 4.8 and GPT 5.5 at long context memory retrieval.
Cognee allows a 100 BILLION token context window 100,000x more than Claude. It's:
- 6.9x cheaper than GPT 5.5 and Opus 4.8
- Cold starts in 350ms & searches in 260ms
Why this matters:
Today agents forget important context, redo tasks, waste tokens, and slow down as workflows get more complex.
Cognee solves this.
It’s not a place to build agents. It connects to the agents you’ve already built, across any platform, and makes them significantly cheaper, faster, and more accurate.
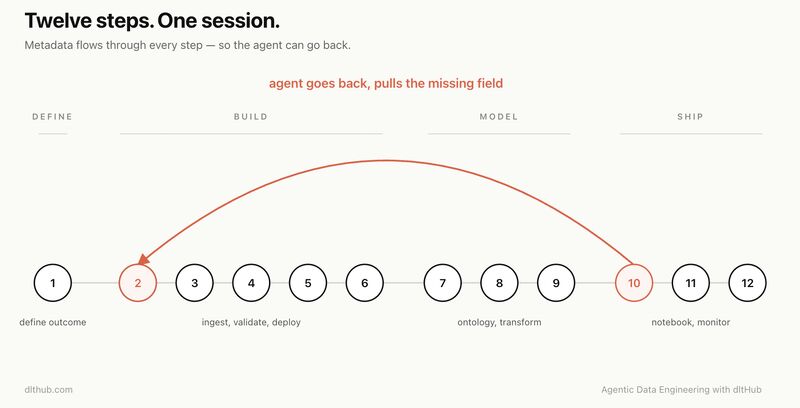
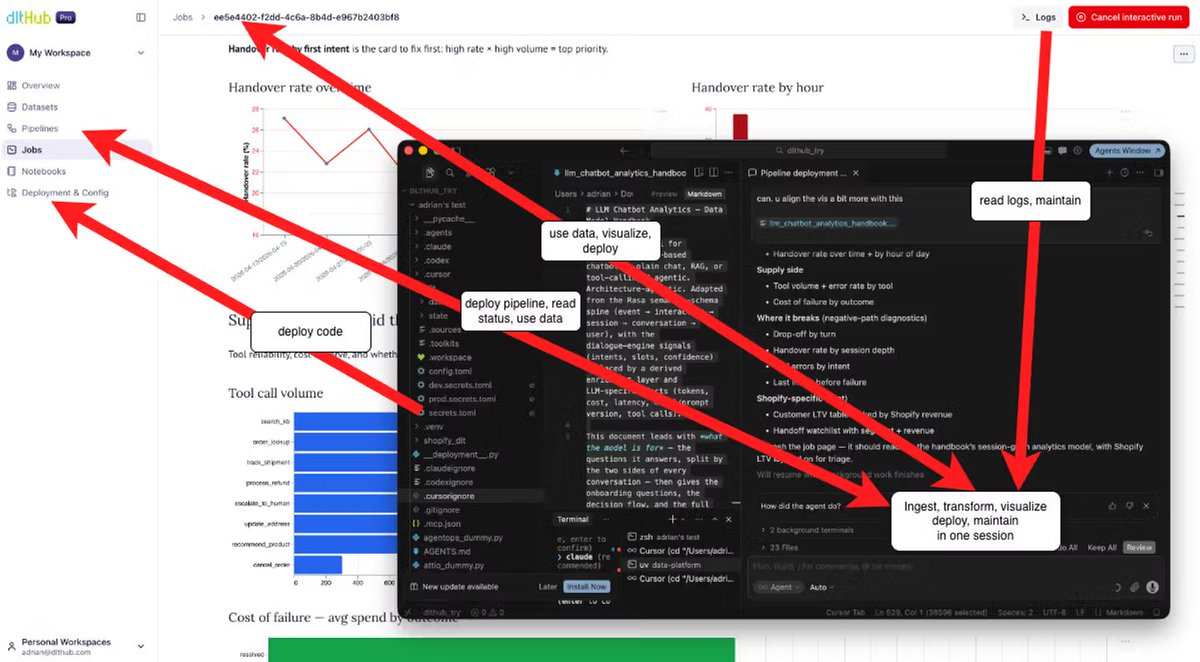
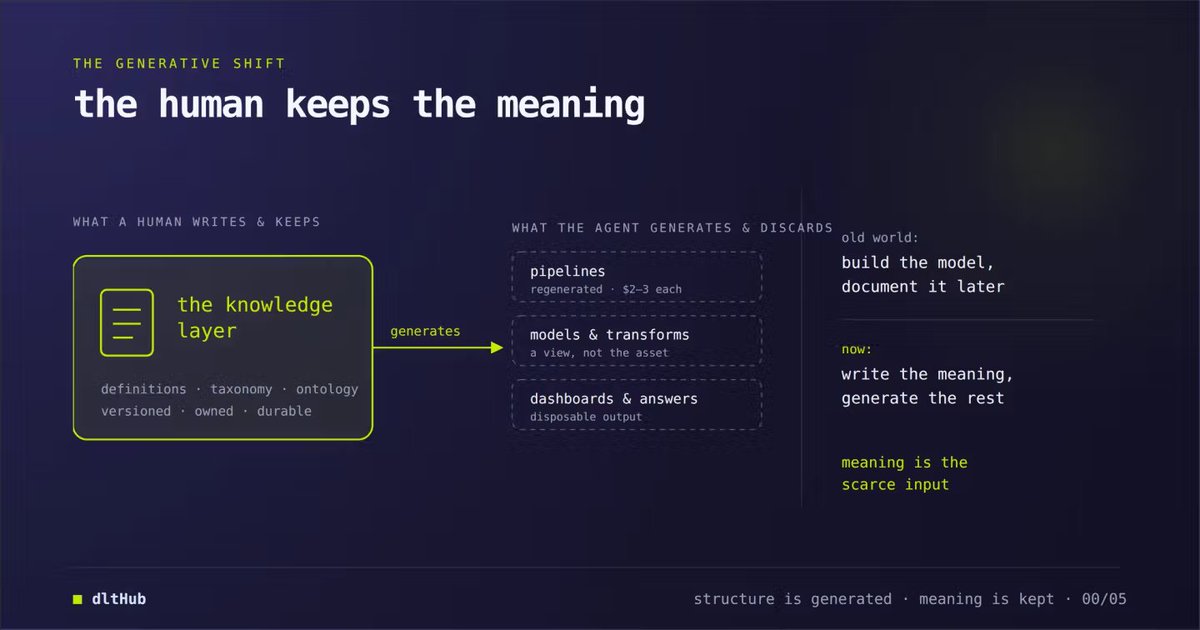
Here's how it works: