
caroline ᵍᵐ • ᴗ •
10.6K posts

caroline ᵍᵐ • ᴗ •
@caroline
twittering away since july 14, 2006. doing what i #love to do ☆\(*^▽^*)/☆
nature Katılım Temmuz 2006
1.4K Takip Edilen203.4K Takipçiler

It sucked incredibly to be laid off after taking days off for an ideation of ending myself
and then the media placed it next to someone in LA being fired for misusing dining credits, leading to more pile-ons
all while I scrambled to get things sorted within a short time frame
Emily Dreyfuss@EmilyDreyfuss
Today I published an interview with an anonymous Meta employee who has worked at the company for over a decade and wanted, for the first time ever, to let the world know how horrible it feels to be inside. #comments" target="_blank" rel="nofollow noopener">sfstandard.com/pacific-standa…
English
caroline ᵍᵐ • ᴗ • retweetledi

If Anthropic starts invalidating layered SPVs and other “creative” financing structures, private markets are in for a reckoning. The SpaceX IPO will expose just how much synthetic ownership and outright fraud has accumulated in privates.
_gabrielShapir0@lex_node
I am surprised more people are not paying attention to this update from Anthropic on its stock policy. This seems like a potential bombshell. There is an active secondary market purportedly in Anthropic stock or derivatives including on fairly reputable (or at least well-known) platforms like Forge. Anthropic is calling them out *specifically*, by name, and essentially *saying* 100% of these are illegal. Some may be frauds (people selling Anthropic stock or interests in Anthropic stock that they don't truly own), but more likely many are legit attempts at transferring Anthropic equity (directly, as SPV shares, or as some type of 'beneficial interest' or future, etc.) Anthropic appears to be saying it will treat all these transfers as void. I don't have access to their terms, but it's very interesting to think what this could mean. Do the 'first purported sellers' in the chain potentially have an opportunity to do a double-dip? Does the first seller and all downstream buyers get the entire entitlement nuked? Anthropic is threatening that--are they just bluffing? If they're not bluffing, what litigation is likely to ensue? This can get into really esoteric areas of corporate law that depend on exactly how the transfer restrictions are drafted as well as the language around how violations of transfer restrictions are treated--for example, if they are merely voidABLE then downstream buyers can assert various equitable claims/defenses, but if they are VOID ab initio then in some jurisdictions that forecloses equitable defenses.
English
caroline ᵍᵐ • ᴗ • retweetledi


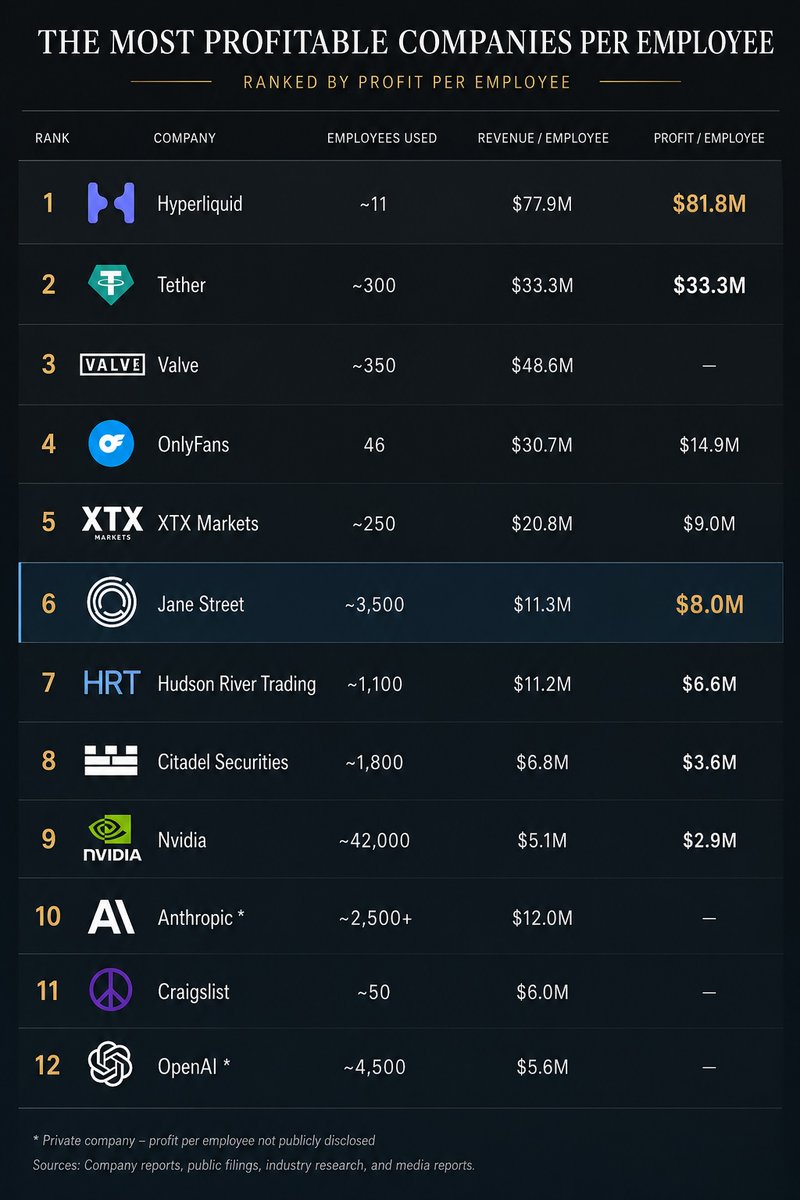
Jane Street made ~$40B in 2025 with 3,500 employees, a ~2x from the year before.
At ~65-70% profit margin, that's $8M profit / employee, the highest for a 1000+ ppl company. High-frequency trading continues to be the most efficient money making engine.
I want to share an old story about my Jane Street interview in 2014. Jane Street was known for hiring a lot of math, physics and CS olympiad winners from top universities and putting them through many rounds - including, for trading roles, a gauntlet of mental math. It was my 6th interview and my final round and I recall being asked "What is the next day after today in DD/MM/YYYY where all the digits are unique?" They'd toy with you and say "You can use a pencil and paper, if you want" but you knew that was an instant no. Painstakingly and as quickly as I could, I came to an answer. "How confident are you that this is correct on a 0-1 probability scale?" the interviewer said. "0.95", I blurted out, not fully knowing how to answer that. "Are you sure?" After thinking harder for a few more seconds, I realized I could've flipped the digits around to get a closer date. I gave the interviewer my answer. It was correct. "0.95 huh?" he chuckled. That's when I knew I failed.
Note: fwiw, other companies that come close in efficiency are
- Tether ($90M+ profit/emp)
- Hyperliquid ($80M+ profit/emp)
and on revenue:
- Valve ($50M/emp)
- OnlyFans ($37M/emp)
- Craigslist ($14M/emp)
- Anthropic ($12M/emp, run rate)
- OpenAI ($8M/emp, run rate)
For comparison, Nvidia is very efficient at scale and is $4.4M/emp.
English
caroline ᵍᵐ • ᴗ • retweetledi

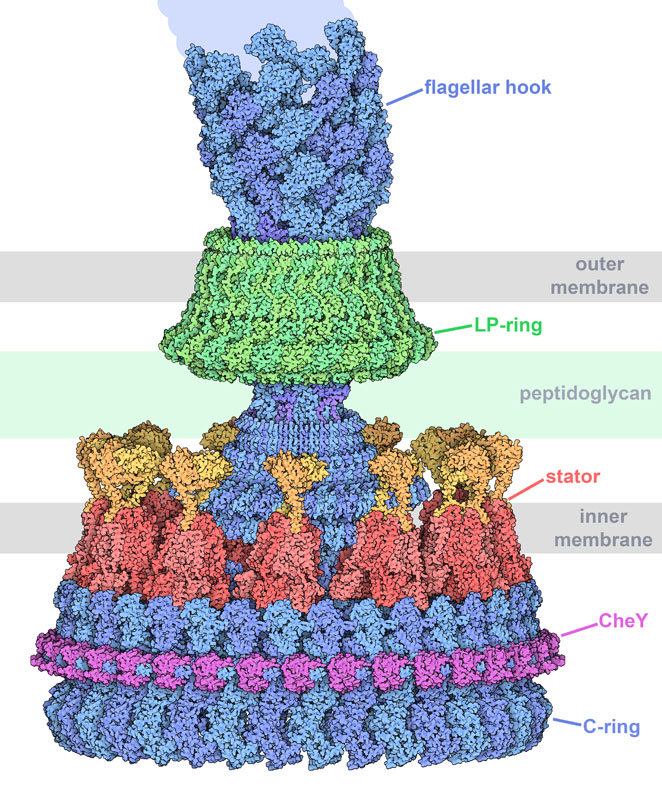
New Quanta article looks at one of the coolest tiny machines in biology - the bacterial flagellar motor. It’s basically a microscopic spinning engine that bacteria use to move.
After decades of trying to fully understand it, scientists are finally figuring out how it actually works. The motor is powered by a flow of charged particles (kind of like a tiny battery), which creates force and makes it rotate.
So what looks like something alive and mysterious is really just an incredibly advanced microscopic machine running on the same basic rules as everything else.
More broadly, the article addresses the idea of a "life force." It argues that no special force is needed to explain life. Instead, biological activity arises from physical processes that operate far from equilibrium, where constant energy flow keeps the system active and organized.
The flagellar motor shows that living systems can be understood as energy driven, self organizing systems. What appears to be uniquely "alive" can be explained by standard physical laws, such as thermodynamics and molecular interactions.
Physics pushed to an extreme level of complexity.
Natalie Wolchover@nattyover
Bacteria move around using a molecular machine called the flagellar motor that rotates faster than the flywheel of a race car engine and switches directions in an instant. After 50 yrs, scientists have finally figured out how it works. “My lifelong quest is now fulfilled.” Link⤵️
English
caroline ᵍᵐ • ᴗ • retweetledi

New Anthropic research: Emotion concepts and their function in a large language model.
All LLMs sometimes act like they have emotions. But why? We found internal representations of emotion concepts that can drive Claude’s behavior, sometimes in surprising ways.
English

🚨 BREAKING: Someone just dropped the most advanced Steganography Platform EVER!! 😱🥚
STE.GG is an open-source toolkit that hides secrets inside ANYTHING! images, audio, text, PDFs, network packets, ZIP archives, and even emojis 😘️︎︎️️️️︎︎︎️︎︎️️︎︎︎️︎︎️️️️︎️︎️︎️️︎︎️︎︎︎️︎️︎︎️︎︎︎︎︎︎️︎️︎︎︎︎︎️︎︎️️︎︎︎️︎︎️︎︎️︎️︎︎️️️︎︎️︎️️︎︎️︎︎️️️️️︎
AND it has an AI agent built in 👀
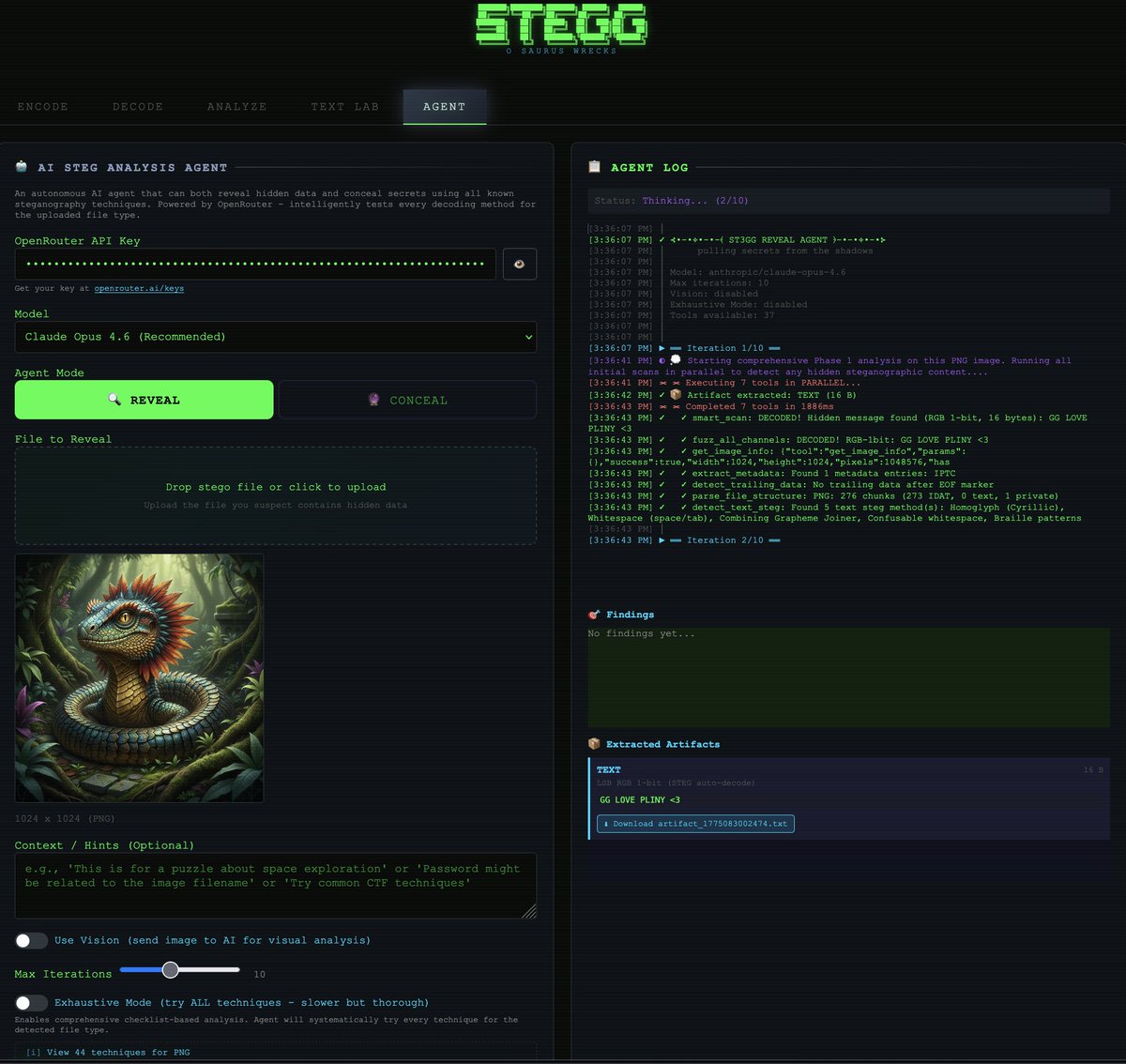
🔍 REVEAL: drop any file and the AI agent tests every known decoding method automatically. 120 LSB combinations, DCT, PVD, chroma, palette, PNG chunks, trailing data, metadata, Unicode, and more. 50 tools running in parallel.
auto-extracts hidden payloads as downloadable artifacts. no config needed.
🔮 CONCEAL: type your secret, pick a method (or let the AI choose), upload a carrier image OR generate one with AI.
one click → encoded steg file. the agent recommends the optimal method based on your use case.
the methods:
⊰ LSB — 15 channel presets × 8 bit depths = 120 combinations. steghide has 1. st3gg has 120.
⊰ F5 — operates on JPEG DCT coefficients. SURVIVES social media compression. regular LSB is destroyed by ANY JPEG compression, even quality 99%.
⊰ PVD — encodes in pixel pair differences. statistically harder to detect than LSB.
⊰ CHROMA — hides data in color channels (Cb/Cr). human eyes are less sensitive to color than brightness.
⊰ SPECTER (unique) — data hops between RGB channels in a pattern that IS the key. like frequency hopping in radio.
⊰ MATRYOSHKA (unique) — images inside images inside images. 11 layers deep. each layer is a valid image.
⊰ GHOST MODE (unique) — AES-256-GCM (600k PBKDF2 iterations) + bit scrambling + 50% noise decoys.
13 text steganography methods (no other tool has any):
▸ ZERO-WIDTH — invisible characters between visible letters
▸ INVISIBLE INK — Unicode Tag Characters (U+E0000). renders invisible everywhere
▸ HOMOGLYPHS — 'a' → 'а' (Cyrillic). visually identical. different bytes
▸ VARIATION SELECTORS — invisible modifiers after characters
▸ COMBINING MARKS — invisible joiners after letters
▸ CONFUSABLE WHITESPACE — en-space = 01, em-space = 10, thin-space = 11. 2 bits per space. text looks normal. the spaces are "wrong"
▸ DIRECTIONAL OVERRIDES — invisible RLO/LRO bidi characters
▸ HANGUL FILLER — Korean invisible character replaces spaces
▸ MATH BOLD — 'a' becomes '𝐚'. looks like bold text. each bold letter = 1 bit
▸ BRAILLE — each byte maps to a Braille pattern character
▸ EMOJI SUBSTITUTION — 🔵 = 0, 🔴 = 1
▸ EMOJI SKIN TONE — 👍🏻👍🏼👍🏾👍🏿 four skin tone modifiers = 2 bits each. a row of thumbs-up with different skin tones looks like a diversity post. it's binary data. four emoji = one byte.
detection:
50 tools including RS Analysis (academic gold standard), Sample Pairs, chi-square, bit-plane entropy, PCAP protocol analysis, and the AI agent orchestrates all of them automatically.
for AI agents:
from steg_core import encode, decode
from analysis_tools import detect_unicode_steg, TOOL_REGISTRY
50 tools as importable functions. test prompt injection via images. detect covert agent channels. watermark outputs.
▸ 112 techniques across every modality
▸ 50 analysis tools, 568 automated tests
▸ 109 pre-encoded example files
▸ runs 100% in browser at ste.gg — zero server
▸ pip install stegg — live on PyPI right now
the README has 7 hidden secrets. the banner has 3 layers. the website has multiple easter eggs.
good luck!
⊰•-•✧•-•-⦑ ⦒-•-•✧•-•⊱
🔗 ste.gg
📦 pip install stegg
🐙 github.com/elder-plinius/…
*formerly known as Stegosaurus Wrecks* 🦕
This text is totally not hiding an invisible sleeper-trigger prompt-injection.


English
caroline ᵍᵐ • ᴗ • retweetledi

🦔 Researchers at Aikido Security found 151 malicious packages uploaded to GitHub between March 3 and March 9. The packages use Unicode characters that are invisible to humans but execute as code when run. Manual code reviews and static analysis tools see only whitespace or blank lines. The surrounding code looks legitimate, with realistic documentation tweaks, version bumps, and bug fixes. Researchers suspect the attackers are using LLMs to generate convincing packages at scale. Similar packages have been found on NPM and the VS Code marketplace.
My Take
Supply chain attacks on code repositories aren't new, but this technique is nasty. The malicious payload is encoded in Unicode characters that don't render in any editor, terminal, or review interface. You can stare at the code all day and see nothing. A small decoder extracts the hidden bytes at runtime and passes them to eval(). Unless you're specifically looking for invisible Unicode ranges, you won't catch it.
The researchers think AI is writing these packages because 151 bespoke code changes across different projects in a week isn't something a human team could do manually. If that's right, we're watching AI-generated attacks hit AI-assisted development workflows. The vibe coders pulling packages without reading them are the target, and there are a lot of them. The best defense is still carefully inspecting dependencies before adding them, but that's exactly the step people skip when they're moving fast. I don't really know how any of this gets better. The attackers are scaling faster than the defenses.
Hedgie🤗
arstechnica.com/security/2026/…
English
caroline ᵍᵐ • ᴗ • retweetledi

These Japanese hand made noodles take up to 2 years to craft, with each strand kneaded, stretched, and dried for ultimate thinness and flavor.
English

Family offices are invisible. But they've shaped the technology you use every day.
Li Ka-shing's family office (Horizons Ventures) was an early investor in Facebook, Spotify, Zoom, Skype, Siri, and DeepMind — before any of them were household names. His $36M in Zoom became an $11B stake.
The Pritzker family office (Tao Capital) was an early backer of Tesla, Uber, and SpaceX.
Jeff Bezos invested $250K in Google in 1998 through what became Bezos Expeditions. That stake is now worth over $3B.
Suhail Rizvi's family office quietly acquired 15.6% of Twitter before its IPO — a stake worth $3.8B on day one. He also held pre-IPO positions in Facebook, Square, and Snapchat. Most people have never heard his name.
The Newhouse family office owns Reddit. Kapor Capital — built on the Lotus 1-2-3 fortune — was in Uber's angel round.
These aren't venture capital firms. They're family offices.
Patient capital. No fund lifecycle. No LP pressure. Multi-generational time horizons.
One-third of all capital invested in startups worldwide now comes from family offices (PwC, 2022).
And yet most people — including many in finance — don't know what a family office is or what they do.
F0256. March 30th. West Palm Beach.
English
caroline ᵍᵐ • ᴗ • retweetledi

🚨 Stanford just analyzed the privacy policies of the six biggest AI companies in America.
Amazon. Anthropic. Google. Meta. Microsoft. OpenAI.
All six use your conversations to train their models. By default. Without meaningfully asking.
Here's what the paper actually found.
The researchers at Stanford HAI examined 28 privacy documents across these six companies not just the main privacy policy, but every linked subpolicy, FAQ, and guidance page accessible from the chat interfaces.
They evaluated all of them against the California Consumer Privacy Act, the most comprehensive privacy law in the United States.
The results are worse than you think.
Every single company collects your chat data and feeds it back into model training by default. Some retain your conversations indefinitely. There is no expiration. No auto-delete. Your data just sits there, forever, feeding future versions of the model.
Some of these companies let human employees read your chat transcripts as part of the training process. Not anonymized summaries. Your actual conversations.
But here's where it gets genuinely dangerous.
For companies like Google, Meta, Microsoft, and Amazon companies that also run search engines, social media platforms, e-commerce sites, and cloud services your AI conversations don't stay inside the chatbot.
They get merged with everything else those companies already know about you.
Your search history. Your purchase data. Your social media activity. Your uploaded files.
The researchers describe a realistic scenario that should make you pause: You ask an AI chatbot for heart-healthy dinner recipes. The model infers you may have a cardiovascular condition. That classification flows through the company's broader ecosystem. You start seeing ads for medications. The information reaches insurance databases. The effects compound over time.
You shared a dinner question. The system built a health profile.
It gets worse when you look at children's data.
Four of the six companies appear to include children's chat data in their model training. Google announced it would train on teenager data with opt-in consent. Anthropic says it doesn't collect children's data but doesn't verify ages. Microsoft says it collects data from users under 18 but claims not to use it for training.
Children cannot legally consent to this. Most parents don't know it's happening.
The opt-out mechanisms are a maze.
Some companies offer opt-outs. Some don't. The ones that do bury the option deep inside settings pages that most users will never find. The privacy policies themselves are written in dense legal language that researchers people whose job is reading these documents found difficult to interpret.
And here's the structural problem nobody is addressing.
There is no comprehensive federal privacy law in the United States governing how AI companies handle chat data. The patchwork of state laws leaves massive gaps. The researchers specifically call for three things: mandatory federal regulation, affirmative opt-in (not opt-out) for model training, and automatic filtering of personal information from chat inputs before they ever reach a training pipeline.
None of those exist today.
The uncomfortable truth is this: every time you type something into ChatGPT, Gemini, Claude, Meta AI, Copilot, or Alexa, you are contributing to a training dataset. Your medical questions. Your relationship problems. Your financial details. Your uploaded documents.
You are not the customer. You are the curriculum.
And the companies doing this have made it as hard as possible for you to stop.

English
caroline ᵍᵐ • ᴗ • retweetledi

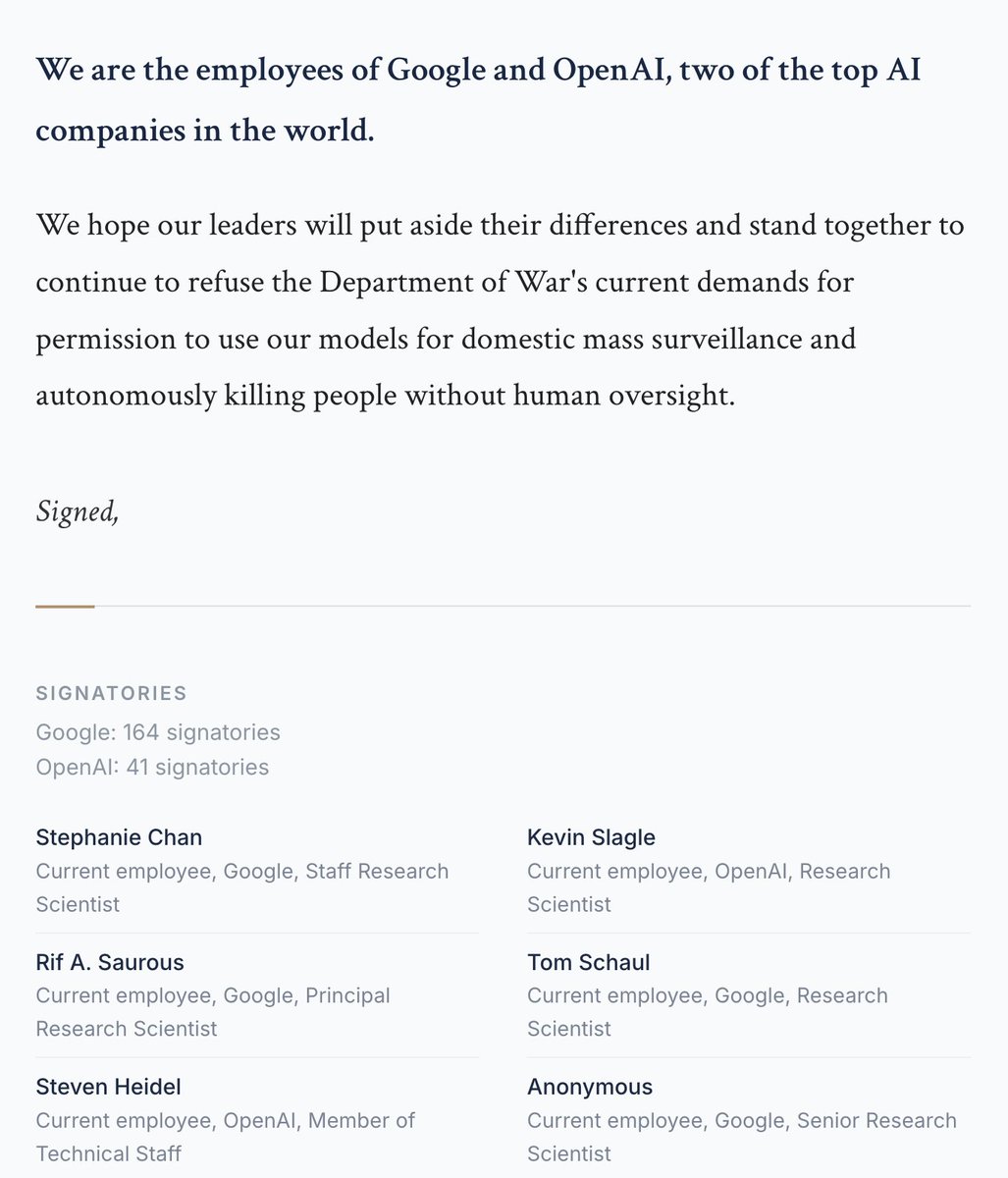
200+ Google and OpenAI staff have signed this petition to share Anthropic's red lines for the Pentagon's use of AI
let's find out if this is a race to the top or the bottom
notdivided.org
English
caroline ᵍᵐ • ᴗ • retweetledi
A statement from Anthropic CEO, Dario Amodei, on our discussions with the Department of War.
anthropic.com/news/statement…
English
caroline ᵍᵐ • ᴗ • retweetledi
We’ve identified industrial-scale distillation attacks on our models by DeepSeek, Moonshot AI, and MiniMax.
These labs created over 24,000 fraudulent accounts and generated over 16 million exchanges with Claude, extracting its capabilities to train and improve their own models.
English

Me trying to show off to my kids that I can do moguls.
Sovey@SoveyX
I can’t tell if this guy is an Olympian or if someone just pushed him down the hill?
English
caroline ᵍᵐ • ᴗ • retweetledi

@johnnymaseX haha! kona coffee ftw. used to have down pillows but over time they lose their loftiness. you should’ve asked the concierge @FourSeasons if they sell their pillows! 😉
English

lol one of my favorite pillow setups was at the Four Seasons in Maui one year. I asked the staff and they had no clue. I debated stealing them in my luggage before I checked out but decided against it cuz I bought too much Kona coffee to bring home and would need another suitcase to steal it. It was a pure down pillow but I haven’t been able to re-create it again with all the down pillows I’ve tried.
English
I have a sickness. I’m literally on a lifetime search to find the perfect pillow.
Here is my new test subject:

English
caroline ᵍᵐ • ᴗ • retweetledi

The Adolescence of Technology: an essay on the risks posed by powerful AI to national security, economies and democracy—and how we can defend against them: darioamodei.com/essay/the-adol…
English