Chenchen Han retweetledi

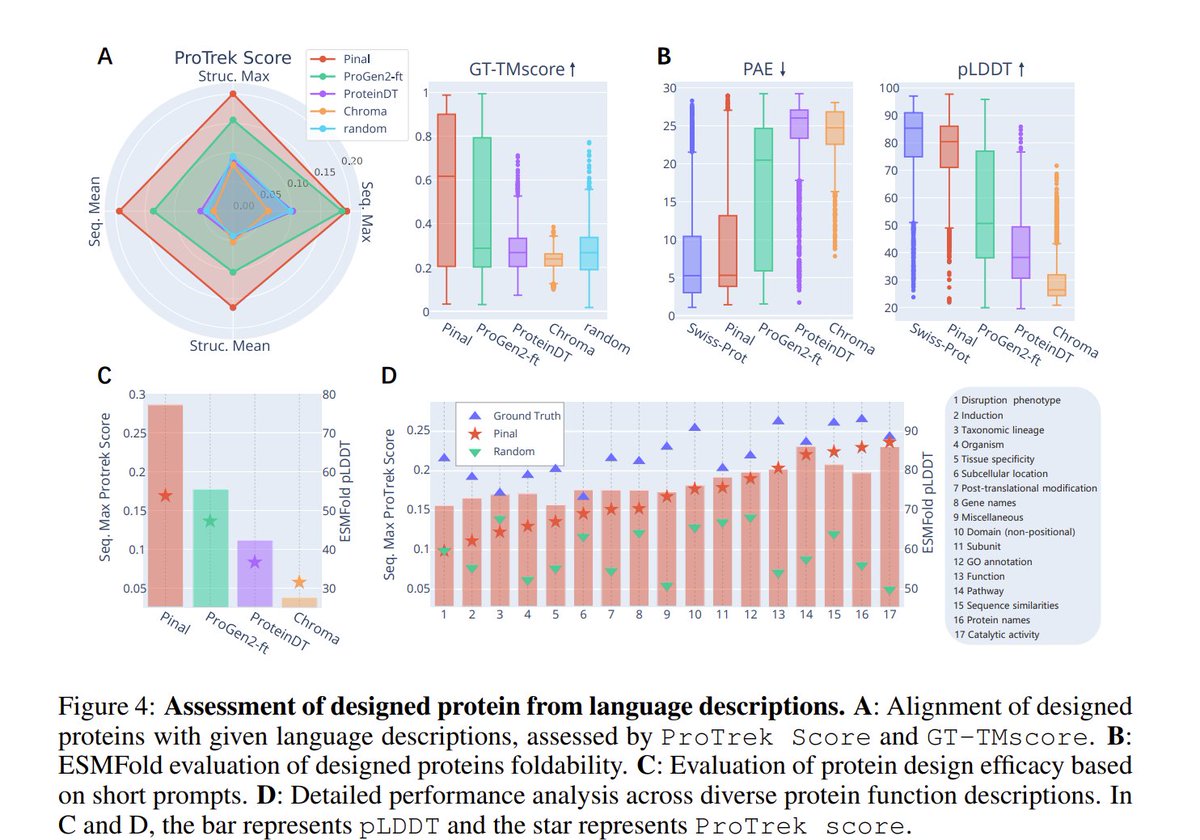
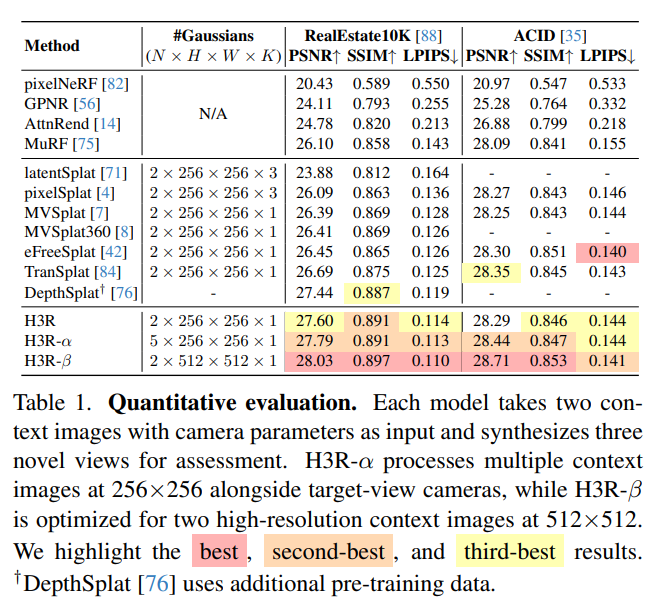
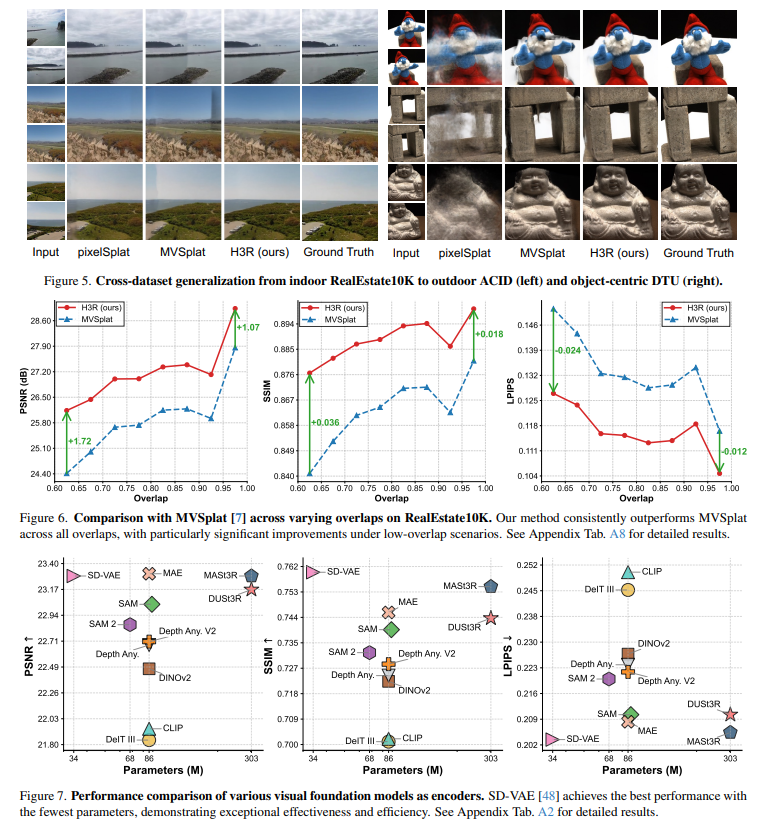
H3R: Hybrid Multi-view Correspondence for Generalizable 3D Reconstruction
Heng Jia, Linchao Zhu, Na Zhao
tl;dr: volumetric latent fusion+camera-aware Transformer; spatial-aligned model>semantic-aligned model
arxiv.org/abs/2508.03118


English