Coding Scenes ⭕ retweetledi
Coding Scenes ⭕
1.4K posts


Coding Scenes ⭕
@CodingScenes
JavaScript | React JS | Angular | ETC. https://t.co/aJKbraT7yr
Mars Katılım Ağustos 2022
68 Takip Edilen15 Takipçiler

Coding Scenes ⭕ retweetledi


Coding Scenes ⭕ retweetledi


Coding Scenes ⭕ retweetledi

Creating AI Agents is the single most important skill in AI.
It feels overwhelming at first, but it is actually really simple.
Just do this to build your first agent (without writing a single line of code)
1. Get a $20 Claude Subscription
2. Follow the step by step guide (linked below)
(100% FREE, No email. No paywall)
English
Coding Scenes ⭕ retweetledi

11 Popular Full Stack Combinations in 2026:
1. Next.js + TypeScript + Supabase
2. Next.js + Prisma + PostgreSQL
3. React + Node.js + MongoDB
4. Flutter + Firebase
5. Remix + Prisma
6. Vue + Nuxt + Laravel
7. SvelteKit + PocketBase
8. T3 Stack (Next.js + tRPC)
9. NestJS + React
10. Go + HTMX
11. Python + FastAPI + React
Which stack are you loving? 👇
Save this. 📌
English
Coding Scenes ⭕ retweetledi

There's a GitHub repo with 323K stars that lists every free API on the internet.
The same repo every senior developer has bookmarked but never tells juniors about.
It's called Public APIs. 1,500+ free endpoints, organized by category, with auth type and HTTPS status documented for every single one.
Here's what's actually in there:
→ Finance, crypto, stocks, and banking data
→ Weather, geocoding, maps, and transportation
→ Books, music, movies, anime, and games
→ Machine learning, OCR, and sentiment analysis
→ Government data, open datasets, news, and health
→ Calendars, currency, security, sports, and dev tools
Every entry tells you exactly what you need before you click. Auth type. CORS status. HTTPS support. Direct link to the docs.
The dirty secret of the API economy is sitting in plain sight here. Half the $99/month tools on the market are wrapping free endpoints from this repo and selling them back to you with a dashboard.
Solo devs are shipping entire products on the free tier of these APIs.
Senior engineers know. Juniors are out there paying RapidAPI subscriptions for endpoints that have been free this whole time.
323K stars. MIT License. 100% Opensource.

English
Coding Scenes ⭕ retweetledi

Anthropic CEO: "AI will write 100% of code within a year"
developers spend 4 years in university learning to code
Claude learned it from every book ever written
if the hardest skill is already handled - the gap is no longer about what you know
it's about how well you've configured the tool that knows everything
most people haven't done that yet
the article below is where you start
Anatoli Kopadze@AnatoliKopadze
English
Coding Scenes ⭕ retweetledi

This Chinese developer launched 6 agents under 1 orchestrator, and they run his UI design agency at $32,000 a month on their own.
He built a system of 6 agents on Claude Sonnet 4.6 that single-handedly runs his agency for UI auditing and redesign for SaaS startups and e-commerce.
No contractors, no project manager, and no team. Just him, a MacBook, and 1 API key.
Traditional design agencies out of Shenzhen keep teams of 8 people on salaries for the same volume, while he keeps only API tokens.
6 agents work through a single orchestrator on Claude Code Router. Usage is about 4 million tokens a day, the average API bill is just $480 a month.
All 6 go through MCP servers and write shared state to the file system, without shared state in memory and without race conditions.
And here is the system prompt he gave the orchestrator before launch:
"you are the orchestrator of a one-man UI agency. you delegate read-only research tasks to 5 sub-agents and own all writes.
sub-agents:
// Hunter (finds SaaS and e-commerce sites with outdated UI)
// Auditor (runs each site through Lighthouse, accessibility, and design system checks)
// Pitcher (writes cold outreach and redesign proposals with before/after screenshots)
// Splitter (breaks accepted projects into typed milestones)
// Designer (generates Figma mockups and Tailwind components)
// Checker (runs evals on every artifact before it leaves the harness).
you never let 2 sub-agents touch 1 file. you stop and request human approval only when an invoice exceeds $5,000 or when the design system eval score drops below 0.88."
Meaning the system knows exactly what it is and within what boundaries it operates.
It knows it is supposed to find clients on its own.
It knows it is supposed to write proposals with screenshots and mockups without intervention.
It knows the human only plugs in when the amounts go above $5,000 or when the design system eval does not converge.
→ The system runs 24 hours a day
→ Hunter finds about 200 sites with outdated UI a day
→ Auditor runs each one through Lighthouse and WCAG
→ Pitcher prepares about 28 personalized proposals with before/after screenshots
→ Splitter breaks 3 accepted projects per week into milestones
→ Designer generates mockups and components, Checker runs evals on every artifact
And only when the invoice breaks $5,000 or the eval drops below 0.88 does the orchestrator wake the human.
Here is what the system outputs in his log during 1 of the sessions:
"hunter report, tuesday: 213 sites found, 31 with last redesign before 2020, 14 with Lighthouse score below 65, 6 with active redesign RFP. passing top 6 to auditor."
"pitcher: 27 cold outreach sent with before/after screenshots, 5 replies, 3 discovery calls scheduled. passing to splitter."
"designer: milestone 2 of Lotus Tea Co redesign complete. Figma frames exported to /Users/dev/agency/clients/lotus/v2. checker running design system evals."
"eval flag: proposal for $6,800 exceeds the approved limit of $5,000. sending for manual review."
He has no remote server. No separate backend. Just a local file sandbox in /Users/dev/agency, an MCP router, and an API key to Claude.
Out of everything I have seen this year, this is the cleanest one-person UI design agency: $480 in, about $32,000 out, and between them 6 prompts and 1 file system.
Khairallah AL-Awady@eng_khairallah1
English
Coding Scenes ⭕ retweetledi

Millions of people use ChatGPT, Claude, and Gemini every day.
But almost nobody understands what actually happens between hitting Enter and seeing words appear on the screen.
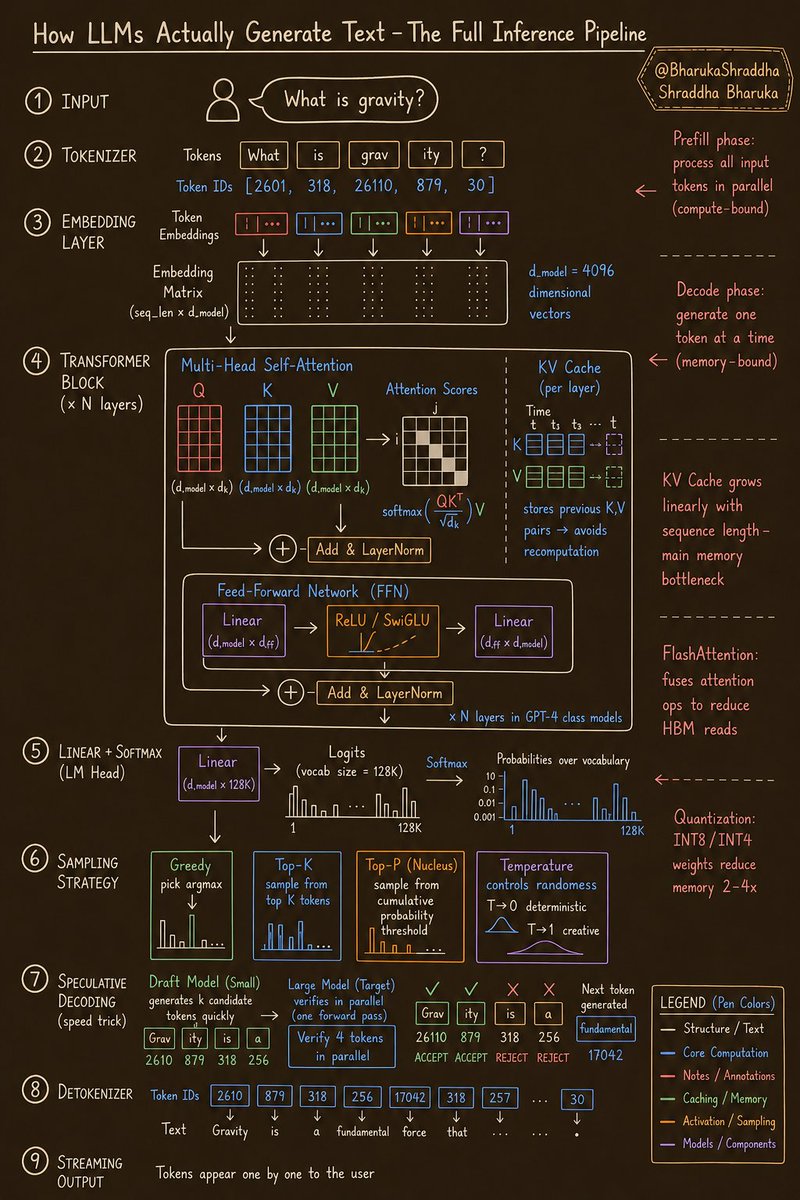
So I'm providing the entire pipeline into one clean visual 👇
Here’s the breakdown:
→ 𝗧𝗼𝗸𝗲𝗻𝗶𝘇𝗲𝗿
Your input isn’t processed as words.
It’s split into tokens.
“gravity” → ["grav", "ity"]
Each token → a numeric ID.
That’s why LLMs struggle with letters — they never truly “see” them.
→ 𝗘𝗺𝗯𝗲𝗱𝗱𝗶𝗻𝗴 𝗟𝗮𝘆𝗲𝗿
Every token becomes a high-dimensional vector (e.g. 4096 dims).
This is where meaning begins:
Similar words → closer in vector space.
→ 𝗧𝗿𝗮𝗻𝘀𝗳𝗼𝗿𝗺𝗲𝗿 𝗕𝗹𝗼𝗰𝗸𝘀 (×𝗡)
The real intelligence lives here.
• Self-attention (Q, K, V) → tokens “look” at each other
• FFN → processes each position
• Repeated dozens of times
This is how context is built.
→ 𝗞𝗩 𝗖𝗮𝗰𝗵𝗲
The most important optimization.
Instead of recomputing everything →
the model stores past attention (K, V)
⚡ Faster generation
⚠️ But memory grows with sequence length
→ This is the real bottleneck
→ 𝗦𝗮𝗺𝗽𝗹𝗶𝗻𝗴 𝗦𝘁𝗿𝗮𝘁𝗲𝗴𝘆
The model doesn’t pick words.
It outputs probabilities.
How you sample = how it behaves:
• Greedy → predictable
• Top-K → limited randomness
• Top-P → balanced
• Temperature → creativity control
Same model. Completely different outputs.
→ 𝗦𝗽𝗲𝗰𝘂𝗹𝗮𝘁𝗶𝘃𝗲 𝗗𝗲𝗰𝗼𝗱𝗶𝗻𝗴
A hidden speed hack.
• Small model predicts ahead
• Large model verifies in parallel
✅ If correct → multiple tokens generated instantly
This is how responses feel fast.
→ 𝗗𝗲𝘁𝗼𝗸𝗲𝗻𝗶𝘇𝗲𝗿 + 𝗦𝘁𝗿𝗲𝗮𝗺𝗶𝗻𝗴
Token IDs → converted back to text
That “typing” effect you see?
It’s not UI animation.
It’s literally token-by-token generation.
⚠️ Two things most people miss:
→ 𝗣𝗿𝗲𝗳𝗶𝗹𝗹 phase = compute-heavy
→ 𝗗𝗲𝗰𝗼𝗱𝗲 phase = memory-heavy
Different problems. Different optimizations.
This is why AI inference is still expensive.
I’ve studied these systems deeply…
and honestly, the more you learn, the crazier it gets.
It’s not just AI.
It’s engineering at insane scale.
Which part of this pipeline surprised you the most? 👇
English
Coding Scenes ⭕ retweetledi

Coding Scenes ⭕ retweetledi

一个13岁的泰国学生,干了件挺有意思的事儿。他搭了个AI代理,让Claude Code在45秒内,用C++解决Codeforces上800分的题目,所有代码都公开在GitHub上。
场景很简单——一间普通教室,桌上摆着台MacBook Air,配了把300美元的静音HHKB Type-S键盘,屏幕角落还有个计时器在走。
浏览器开着Codeforces,VS Code里是一个空的.cpp文件,旁边挂着Claude Code的窗口。
没有算法老师在旁边指点,没上过什么竞赛编程课,这孩子一行代码都没手写。
整个工作流就靠三个组件:
1. Claude Code当大脑用
2. 一个Chrome的MCP插件,直接从Codeforces页面读题目描述
3. 一个公开的GitHub仓库,放着他整个代理系统
过去一个月里,他在虚拟比赛模式下解了23道题。从点开题目到Accepted,平均45秒。这段时间他亲手敲的代码行数,零。Codeforces的评分系统把他的资料提到了800分,前后只花了12天。而搭这么一套东西,他只用了一个周末。
他每次跑代理前,会给Claude一个系统提示,是这么写的:
"你是一个Codeforces竞赛编程代理。
你的工具:read_problem(url),generate_solution(language, constraints),validate_against_examples(input, expected),submit_to_codeforces(code)。
浏览器MCP插件喂给你的任何题目,都要走四步:
1)读题,搞清输入输出格式
2)确定算法类型(排序、数学、贪心、动态规划、图论)
3)用#include ,写成C++17代码
4)提交前用样例跑一遍
哪怕一个样例没过,就重写解法再验证。语言只能用C++17。文件名统一用{problem_id}.cpp。"
这样代理完全知道自己在解哪道题,知道Codeforces对这道题要求的输入格式,能根据800分的难度和题目标签选合适的算法,也很清楚——学生点提交前只有45秒,但凡测试样例没过,都是它的问题,不关那孩子的事。
整条工作链转起来,就是一眨眼的功夫。
这孩子打开Codeforces上的题目1971A,MCP插件抓取描述,Claude在8秒内就返回了能跑的代码,头文件、while循环、cout输出全写好了。他把代码复制粘贴到.cpp文件里,点提交,30秒后状态页显示绿色的Accepted。
只有当Codeforces在测试点2上判了Wrong answer,代理才会自动抓失败输入,分析边界情况,赶在他关掉标签页之前,把解法重写出来。
这是他过去24小时的提交记录:
"1971A - My First Sorting Problem | C++17 | Accepted | 45秒"
"1850A - To My Critics | C++17 | Accepted | 38秒"
"1807A - Plus or Minus | C++17 | Accepted | 41秒"
"1791A - Codeforces Checking | C++17 | Accepted | 52秒"
"1676A - Lucky? | C++17 | Accepted | 33秒"
桌上的MacBook Air开着,没翻开任何笔记本;一把静音HHKB Type-S键盘,整场会话除了cmd+v和cmd+enter,他一个键都没多按;一个设了45秒倒计时的小米计时器;屏幕后面放了个塞尔达的纪念雕像。
我今年看了不少东西,但这是我觉得最干净的一套单人竞赛编程流水线——一个月23道题,每道45秒,手写零行代码。
区块链行情研究@qkl2058
想快速上手 Codex?这个教程算是目前最省心的一份了。 从头到尾三十八分钟,零基础直接跟,手把手带你把这套工具用明白。多版本怎么装、语音对话、从 GitHub 上拉项目、插件配置、MCP 对接、自动化测试,还有搭建工作流,这些实操环节全都有。 全程用的都是最新版本,纯中文讲解,讲得通俗,不绕弯子,新手也能一遍看懂、上手就用。
中文
Coding Scenes ⭕ retweetledi

Kubernetes mistakes you’re probably making
These 5 basics cause most outages:
1. No requests & limits
→ pods fight for resources
→ unstable workloads
2. Missing probes
→ broken pods still get traffic
→ no self-healing
3. No autoscaling
→ traffic spike = crash
→ no elasticity
4. Hardcoded configs
→ risky + hard to manage
→ secrets exposed
5. Unused resources everywhere
→ wasted money
→ messy cluster
Most outages start here.
Fix the basics before scaling 🚀

English
Coding Scenes ⭕ retweetledi

Coding Scenes ⭕ retweetledi


Coding Scenes ⭕ retweetledi

LLMs are AI… but not all AI is LLMs.
A new wave of specialized models is redefining what AI can do ⚡
Here are 8 architectures you should know:
1️⃣ LLMs (Large Language Models)
Process text token-by-token
→ Power chatbots, coding, reasoning
2️⃣ LCMs (Large Concept Models)
Encode full ideas as “concepts”
→ Move beyond word-level thinking
3️⃣ VLMs (Vision-Language Models)
See + read
→ Understand images and describe them
4️⃣ SLMs (Small Language Models)
Lightweight + fast
→ Built for edge devices
5️⃣ MoE (Mixture of Experts)
Activate only relevant parts
→ Smarter + more efficient
6️⃣ MLMs (Masked Language Models)
Bidirectional context
→ Strong understanding of meaning
7️⃣ LAMs (Large Action Models)
Think → Act
→ Execute real-world/system tasks
8️⃣ SAMs (Segment Anything Models)
Pixel-level vision
→ Precise object segmentation
Old AI vs New AI
Traditional AI:
• One model → many tasks
• Limited flexibility
• Heavy compute
Specialized AI:
• Purpose-built models
• Optimized (speed, size, accuracy)
• Unlock new capabilities
Why this matters:
✅ Better performance per task
✅ Faster + more efficient
✅ More useful real-world outputs
The future isn’t one model.
It’s the right model for the right job.
Which architecture would help your work most? 🤔
#AI #MachineLearning #LLM #TechTrends
GIF
English
Coding Scenes ⭕ retweetledi

A 16-year-old in Pakistan with no laptop just got into MIT.
He learned everything from one GitHub repo.
It's the largest collection of free university CS lectures on the internet, and it's quietly been replacing $200K degrees for years.
Every course from MIT, Stanford, Harvard, CMU, Berkeley, Caltech, Princeton, IIT, ETH Zurich, Oxford, and more.
All in one place. All free. All with full video lectures.
You can learn:
→ Algorithms, Data Structures, Operating Systems
→ Distributed Systems, Databases, Computer Networks
→ Machine Learning, Deep Learning, Reinforcement Learning
→ Computer Vision, NLP, Generative AI and LLMs
→ Computer Graphics, Quantum Computing, Robotics
→ Security, Blockchain, Computational Biology
→ Software Engineering, Software Architecture, Concurrency
500+ courses. Every major CS subfield. Taught by the same professors who train the engineers at OpenAI, Google DeepMind, and Anthropic.
MIT 6.006 Introduction to Algorithms. Stanford CS229 Machine Learning. CMU 15-445 Database Systems. Berkeley CS 188 Artificial Intelligence. Harvard CS50.
The exact lectures students pay six figures to sit through. Sitting in a public repo. Free.
76.5K stars. 10.4K forks. 100% Opensource.

English
Coding Scenes ⭕ retweetledi

Coding Scenes ⭕ retweetledi

Full Stack Developer in the AI Era Concepts to Master before Interviews ✅
1. HTML, CSS & Modern UI Systems (Responsive Design, TailwindCSS)
2. JavaScript & TypeScript (Core + Advanced Concepts)
3. Frontend Frameworks (React, Next.js, Vue)
4. State Management (Redux, Zustand, Context API)
5. Backend Development (Node.js, Express, Python, Go)
6. API Design (REST, GraphQL, gRPC)
7. Databases (SQL: PostgreSQL/MySQL, NoSQL: MongoDB)
8. Authentication & Authorization (JWT, OAuth2, Sessions)
9. Full Stack Frameworks (Next.js, Remix, Nuxt)
10. AI Integration in Apps (LLMs, APIs, embeddings)
11. Working with AI APIs (OpenAI, Anthropic, etc.)
12. Prompt Engineering Fundamentals
13. Vector Databases (Pinecone, Weaviate, FAISS)
14. Retrieval-Augmented Generation (RAG)
15. File Uploads & Storage (Cloudinary, S3)
16. Realtime Systems (WebSockets, Server-Sent Events)
17. Testing (Unit, Integration, E2E – Jest, Cypress, Playwright)
18. Version Control (Git & GitHub Workflows)
19. CI/CD Pipelines
20. Containerization (Docker)
21. Kubernetes Basics
22. Deployment Platforms (Vercel, AWS, DigitalOcean)
23. Performance Optimization (Code Splitting, Caching)
24. Security Best Practices (HTTPS, CSP, OWASP)
25. Observability (Logging, Metrics, Tracing)
26. Microservices vs Monolith Architecture
27. Serverless & Edge Computing
28. Scalability Patterns (Horizontal scaling, sharding)
29. System Design Fundamentals
30. Product Thinking & Developer Experience (DX)
📘 Grab the Modern Full Stack Latest Edition Handbook:
👉 codewithdhanian.gumroad.com/l/fzqjct

English
Coding Scenes ⭕ retweetledi
11 Important Backend Architecture Patterns:
1. Monolith
2. Microservices
3. Event-Driven
4. Serverless
5. Layered Architecture
6. Clean Architecture
7. Hexagonal Architecture
8. CQRS
9. Saga Pattern
10. API Gateway
11. BFF (Backend for Frontend)
Which pattern are you using right now? 👇
Save this. 📌
English
Coding Scenes ⭕ retweetledi

Softmax vs Sigmoid ✍️ Interact 👉 byhand.ai/Khlg9b
= Softmax =
Softmax is how deep networks turn raw scores into a probability distribution — the final layer of every classifier, and the core of every attention head in a transformer. To see what it does, picture five boba tea shops on the same block, all competing for your dollar. Five candidates: a, b, c, d, e — different chains, different brewing styles, different pearls. A boba reviewer hands you a 𝘤𝘩𝘦𝘸𝘪𝘯𝘦𝘴𝘴 𝘴𝘤𝘰𝘳𝘦 for each — higher means perfectly chewy "QQ" pearls with the right bite (ask a Taiwanese friend to find out what QQ means). Negative scores are real: mushy bobas, overcooked pearls, a batch left sitting too long.
How do you turn five chewiness scores into an allocation that adds to a whole dollar? You could spend everything at the chewiest shop, but that ignores how good the runners-up are. Softmax is the smooth alternative.
Read the diagram left to right. First, raise each score to e^{x} — this does two things: it turns negative chewiness into small positives, and it stretches the gaps between scores exponentially. Then sum all five into a single total Z. Finally, divide each e^{x} by Z to get a probability. The five probabilities add up to one, so you can read them as percentages of your dollar. The chewiest shop gets the biggest slice — but never the whole dollar. That's the point of softmax: it ranks confidently while still leaving room for the others.
= Sigmoid =
Sigmoid squashes any real number into a probability between 0 and 1 — the classic activation for binary classification, and still the gating function inside LSTMs and GRUs. Same boba block as the previous Softmax example, narrowed to just two contenders — a hot new shop `a` with chewiness score x, and your usual go-to `b` whose score is pinned at zero (the neutral baseline you've come to expect).
Sigmoid is just softmax with two players, one of them pinned to zero.
Read the diagram left to right. First, raise each score to e^{x} — for the usual shop `b` whose score is zero, this is just e^0 = 1 (the constant baseline). Then sum the two into a total Z. Finally, divide each e^{x} by Z to get a probability. The two probabilities add up to one — the new shop wins more of your dollar when its pearls get chewier, and your usual keeps the rest. That's the point of sigmoid: it turns a single chewiness score into a clean 0-to-1 chance you'll try the new place over your usual.
---
AI Math, Algorithms, Architectures by hand ✍️
Subscribe to my 60K+ reader newsletter 👉 byhand.ai
English