Sabitlenmiş Tweet

@pnickdurham Okay let's go fund it, there are companies that are already doing that. They just need to scale.
English
Collin Paran
2.5K posts

@CollinParan
Put the first #AI #LLM in #Space | #Veteran | Early #Dogecoin #XLM adopter This is my personal account, views are my own.








Recently, there has been a lot of talk of LLM agents automating ML research itself. If Llama 5 can create Llama 6, then surely the singularity is just around the corner. How can we get a pulse check on whether current LLMs are capable of driving this kind of total self-improvement? Well, we know humans are pretty good at improving LLMs. In the NanoGPT speedrun challenge, created by @kellerjordan0, human researchers iteratively improved @karpathy's GPT-2 replication, slashing the training time (to the same target validation loss) from 45 minutes to under 3 minutes in just under a year (!). Surely, a necessary (but not sufficient) ability for an LLM that can automatically improve frontier techniques is the ability to *reproduce* known innovations on GPT-2, a tiny language model from over 5 years ago. 🤔 So we took several of the top models and combined them with various search scaffolds to create *LLM speedrunner agents*. We then asked these agents to reproduce each of the NanoGPT speedrun records, starting from the previous record, while providing them access to different forms of hints that revealed the exact changes needed to reach the next record. The results were surprising—not because we thought these agents would ace the benchmark, but because even the best agent failed to recover even half of the speed-up of human innovators on average in the easiest hint mode, where we show the agent the full pseudocode of the changes to the next record. We believe The Automated LLM Speedrunning Benchmark provides a simple eval for measuring the lower bound of LLM agents’ ability to reproduce scientific findings close to the frontier of ML. Beyond scientific reproducibility, this benchmark can also be run without hints, transforming into an automated *scientific innovation* benchmark. When run in "innovation mode," this benchmark effectively extends the NanoGPT speedrun to AI participants! While initial results here indicate that current agents seriously struggle to match human innovators beyond just a couple of records, benchmarks have a tendency to fall. This one is particularly exciting to watch, as new state-of-the-art here by definition implies a form of *superhuman innovation*.

Please @elonmusk do not eliminate the very important online training we do in the military every year.
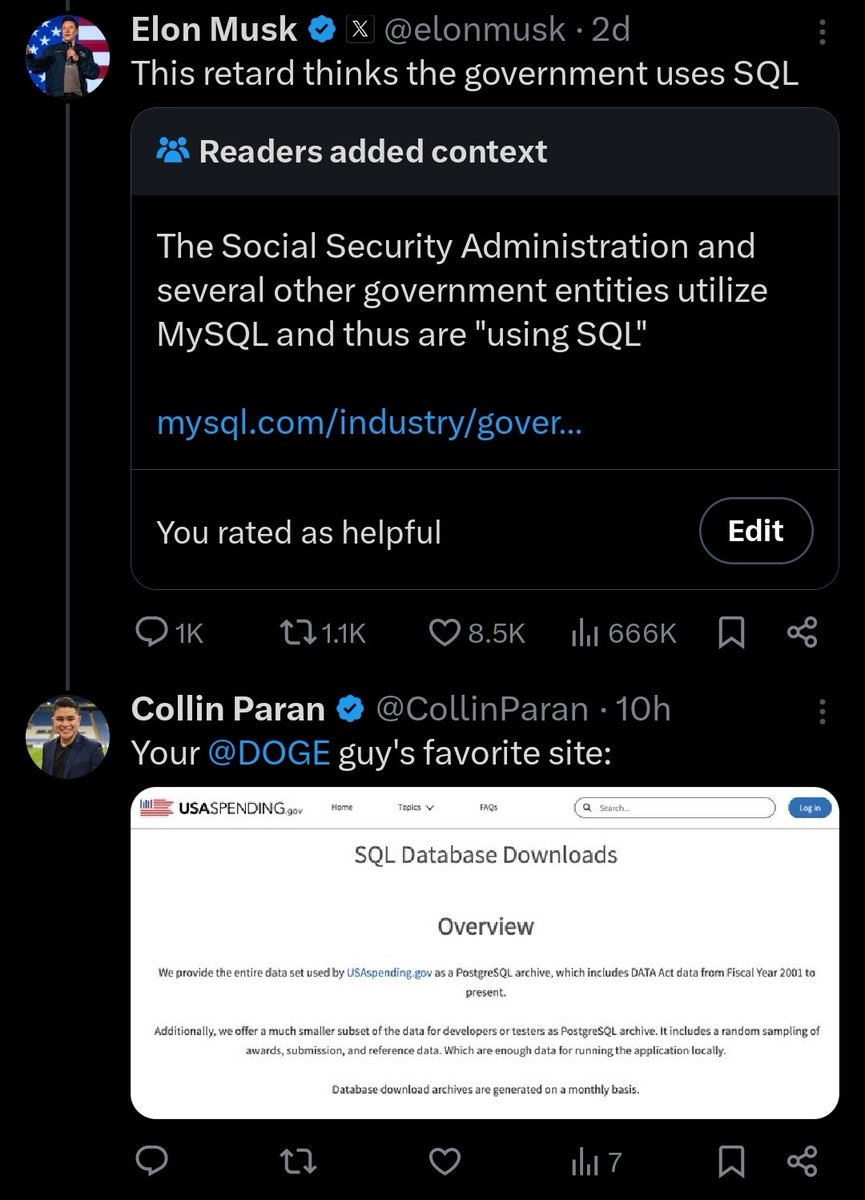
I can't believe how good this timeline is! Follow this chain of events: 1. Reuters writes hit piece against DOGE. 2. Musk tweets, 'I wonder what Reuters are being paid? 3. DOGE uncovers Department of Defence contract paying Reuters for 'Large Scale Social Deception. It's crazy that this is happening. It's INSANE that it's playing out in the public square!



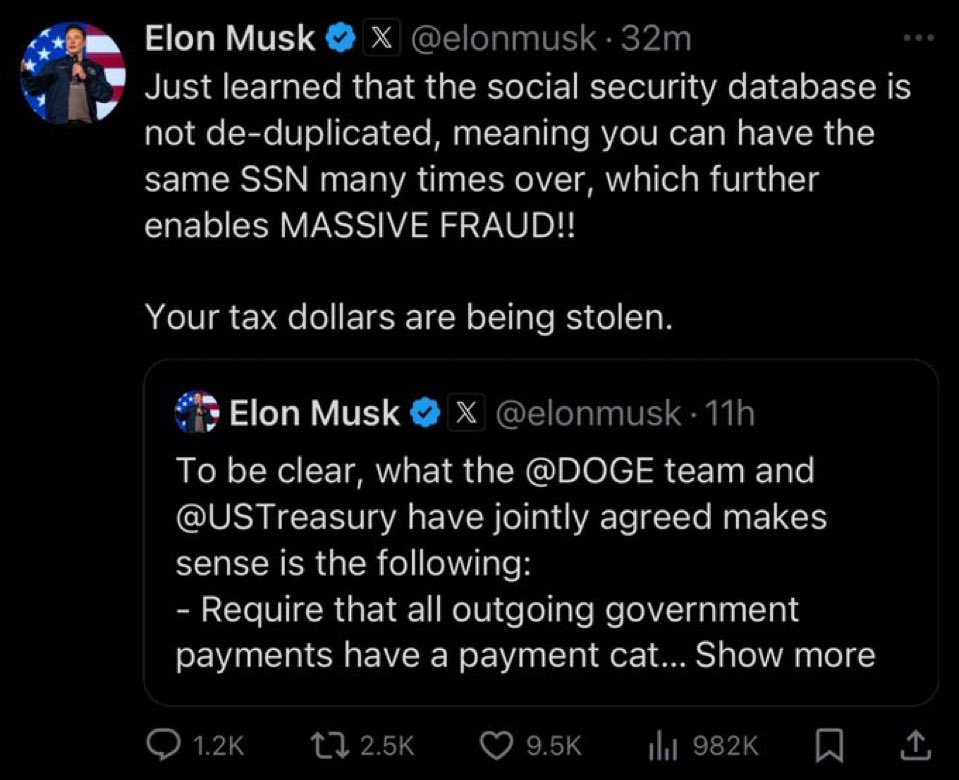
To be clear, what the @DOGE team and @USTreasury have jointly agreed makes sense is the following: - Require that all outgoing government payments have a payment categorization code, which is necessary in order to pass financial audits. This is frequently left blank, making audits almost impossible. - All payments must also include a rationale for the payment in the comment field, which is currently left blank. Importantly, we are not yet applying ANY judgment to this rationale, but simply requiring that SOME attempt be made to explain the payment more than NOTHING! - The DO-NOT-PAY list of entities known to be fraudulent or people who are dead or are probable fronts for terrorist organizations or do not match Congressional appropriations must actually be implemented and not ignored. Also, it can currently take up to a year to get on this list, which is far too long. This list should be updated at least weekly, if not daily. The above super obvious and necessary changes are being implemented by existing, long-time career government employees, not anyone from @DOGE. It is ridiculous that these changes didn’t exist already! Yesterday, I was told that there are currently over $100B/year of entitlements payments to individuals with no SSN or even a temporary ID number. If accurate, this is extremely suspicious. When I asked if anyone at Treasury had a rough guess for what percentage of that number is unequivocal and obvious fraud, the consensus in the room was about half, so $50B/year or $1B/week!! This is utterly insane and must be addressed immediately.