By maintaining a constant sense of threat to oil supply routes, Iran can keep a geopolitical risk premium embedded in oil prices and sustain tension across global markets.
5/
Put it all together and you get a proof market.
Projects request proofs.
Provers generate them.
The network coordinates the compute.
Instead of building huge prover clusters, teams can just use Fermah.
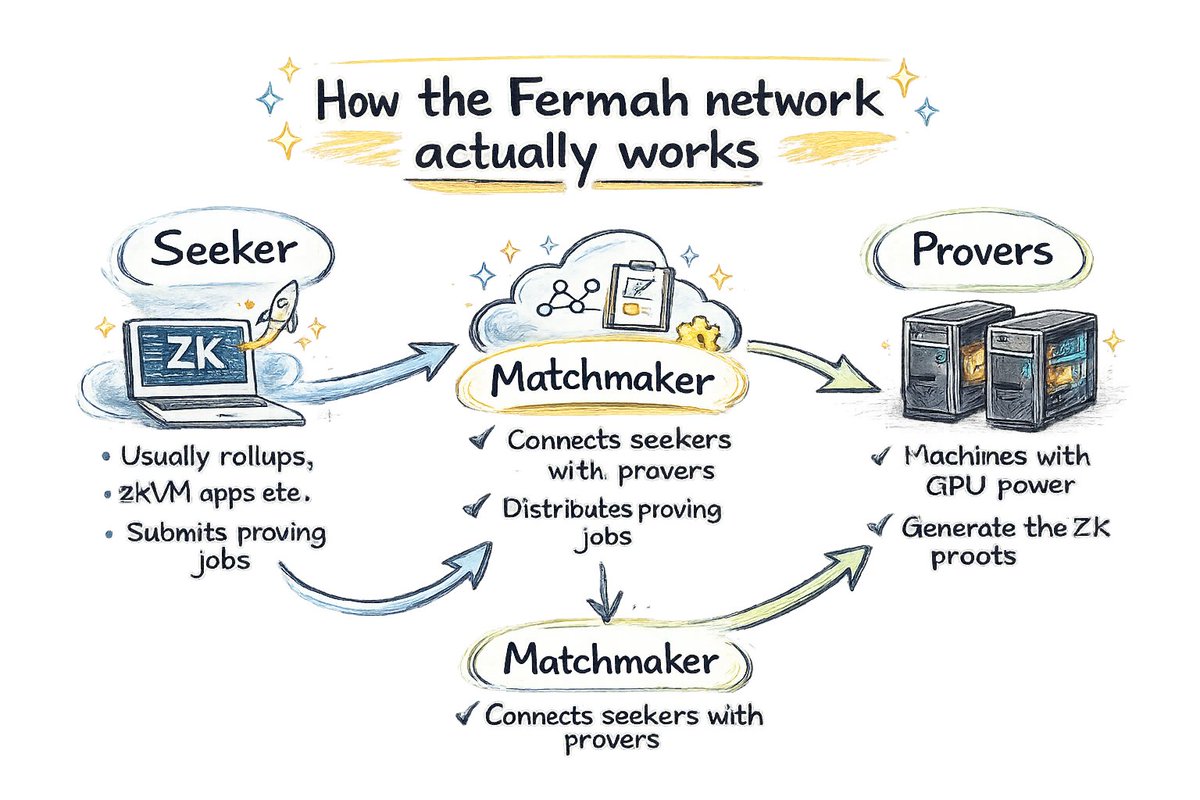
4/ Matchmaker
This is the coordination layer.
It routes proving jobs to available provers and distributes work across the network.
Think of it like a scheduler for proving tasks.
Let’s break down how the Fermah network actually works
1/ If you zoom out, Fermah is basically building a marketplace for ZK proving compute.
Projects need proofs.
Machines generate them.
Fermah connects the two.
Genesis Globe is coming.
The mint date is officially set for March 11.
Minting will happen via @opensea : opensea.io/collection/gen…(Wallets are not added yet)
If you still don’t have WL, you still have a chance.
You can apply on our website: genesisglobe.xyz
For the next 48 hours.
This is your chance to be part of Genesis Globe.
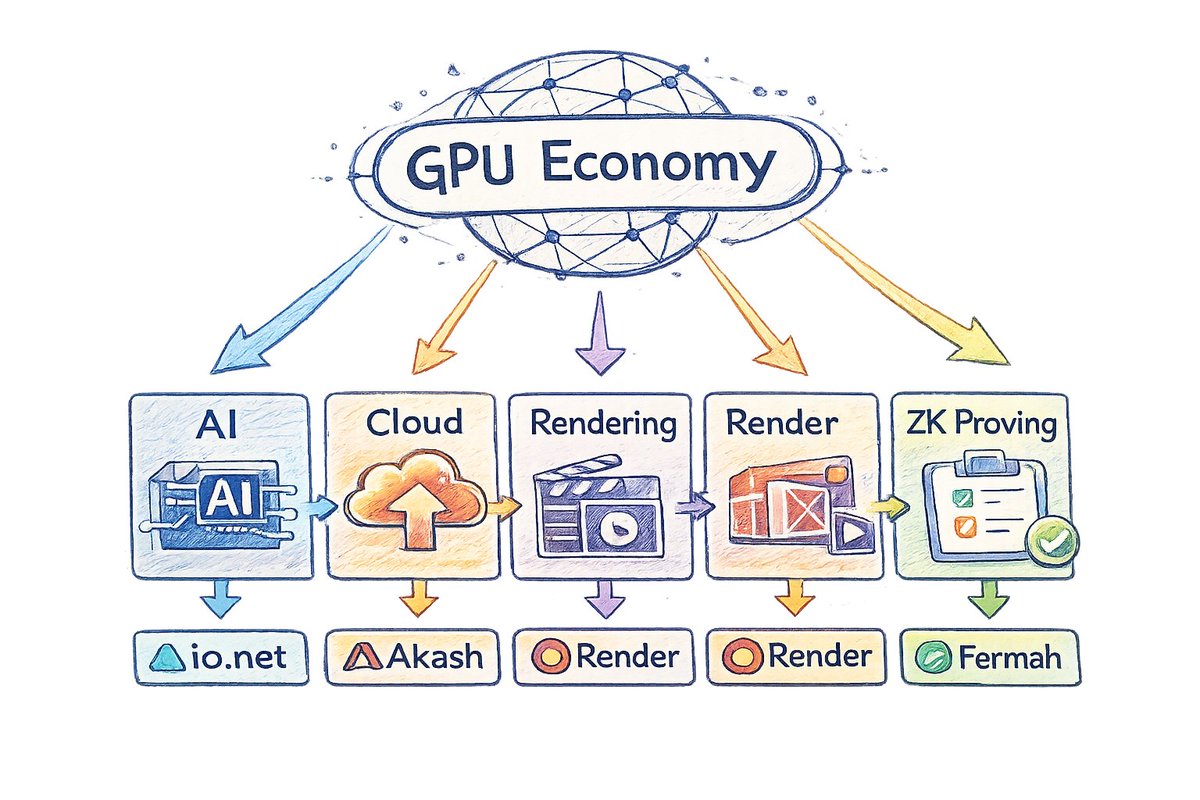
5/ Zoom out and the pattern becomes clear:
crypto isn’t just building financial networks.
It’s starting to build markets for global compute.
And GPU networks like Render, Akash, io. net, and @fermah_xyz could become key infrastructure.
4/ @fermah_xyz focuses on another major GPU workload:
ZK proving.
Generating zero-knowledge proofs requires huge amounts of compute.
Fermah turns this into a marketplace for proving power.
1/ Projects like @fermah_xyz are emerging around a simple idea: turn heavy compute workloads into decentralized markets for GPUs.
ZK proving is one example — but it’s part of a much bigger trend.
A global GPU economy in crypto is starting to take shape 👇
4/ Once the proof is generated, it’s verified and returned to the project.
From the outside it looks simple:
submit job → receive proof.
But under the hood, a distributed compute network coordinated hardware, scheduling, and parallel proving.
3/ Then the job gets scheduled and distributed.
Not every prover setup is the same — some GPUs or machines are better for specific proving systems.
Large proving jobs can also be split and run in parallel, improving throughput and latency.
1/ In the previous thread we looked at the roles in Fermah.
Now let’s go one level deeper:
what actually happens after a proving job enters the network?
Here’s the simplified pipeline 👇