Sabitlenmiş Tweet
Crypt0x
5K posts


@BoWang87 One thing people are going to have to learn the hard way is that THERE IS NO SHORTCUT FOR COMPUTATIONAL IRREDUCIBILIT.
NAVIGATING THROUGH PROOF SPACE IS A COMPUTATIONAL ACTIVITY
You can't solve RH or Collatz by just guessing a proof together, you'll be waiting a very long time.
English
@BoWang87 Which Claude is this because Opus 4.6 on maximum effort is a mathematical retard that gets itself caught in circular reasoning and dead ends.
It isn't trained for this, so any results it gets are either luck or they weren't that difficult or interesting in the first place.
English

Three weeks ago I shared that Claude had shocked Prof. Donald Knuth by finding an odd-m construction for his open Hamiltonian decomposition problem in about an hour of guided exploration. Prof. Knuth titled the paper Claude’s Cycles.
The story didn't end there.
The updated paper shows the story got much bigger. For the base case m=3, there are exactly 11,502 Hamiltonian cycles. Of those, 996 generalize to all odd-m, and Prof. Knuth shows there are exactly 760 valid “Claude-like” decompositions in that family.
The even case, which Claude couldn’t finish, was then cracked by Dr. Ho Boon Suan using GPT-5.4 Pro to produce a 14-page proof for all even m≥8, with computational checks up to m=2000.
Soon after, Dr. Keston Aquino-Michaels used GPT + Claude together to find simpler constructions for both odd and even m, by using the multi-agent workflow.
Dr. Kim Morrison also formalized Knuth’s proof of Claude’s odd-case construction in Lean.
So yes: the problem now appears fully resolved in the updated paper’s ecosystem of human + AI + proof assistant work!
We went from one AI solving one problem to a full mathematical ecosystem (multiple AI systems, multiple humans, formal verification) running in parallel on a problem that stumped experts for weeks.
We are living in very interesting times indeed.
Paper (updated): www-cs-faculty.stanford.edu/~knuth/papers/…


Bo Wang@BoWang87
Prof. Donald Knuth opened his new paper with "Shock! Shock!" Claude Opus 4.6 had just solved an open problem he'd been working on for weeks — a graph decomposition conjecture from The Art of Computer Programming. He named the paper "Claude's Cycles." 31 explorations. ~1 hour. Knuth read the output, wrote the formal proof, and closed with: "It seems I'll have to revise my opinions about generative AI one of these days." The man who wrote the bible of computer science just said that. In a paper named after an AI. Paper: cs.stanford.edu/~knuth/papers/…
English
@krzyzanowskim Boring. I've done this except using a REAL PROGRAMMING LANGUAGE: C++
I have an extractor which extracts the source from the Bun build, then I implement the features that I care about and leave the rest, mostly half baked experimental shit only API accounts can use.
English

I reimplemented "claude" CLI with codex and gpt-5.4-high. It cost $1100 in tokens, and is 73% faster and 80% lower resident memory during sustained interactive use.
It is very easy to reverse claude from npm distribution, then reimplement is 1:1. It is indistinguishable from the Anthropic version to the every header and analytics it send back
github.com/krzyzanowskim/…
English

Three days ago I left autoresearch tuning nanochat for ~2 days on depth=12 model. It found ~20 changes that improved the validation loss. I tested these changes yesterday and all of them were additive and transferred to larger (depth=24) models. Stacking up all of these changes, today I measured that the leaderboard's "Time to GPT-2" drops from 2.02 hours to 1.80 hours (~11% improvement), this will be the new leaderboard entry. So yes, these are real improvements and they make an actual difference. I am mildly surprised that my very first naive attempt already worked this well on top of what I thought was already a fairly manually well-tuned project.
This is a first for me because I am very used to doing the iterative optimization of neural network training manually. You come up with ideas, you implement them, you check if they work (better validation loss), you come up with new ideas based on that, you read some papers for inspiration, etc etc. This is the bread and butter of what I do daily for 2 decades. Seeing the agent do this entire workflow end-to-end and all by itself as it worked through approx. 700 changes autonomously is wild. It really looked at the sequence of results of experiments and used that to plan the next ones. It's not novel, ground-breaking "research" (yet), but all the adjustments are "real", I didn't find them manually previously, and they stack up and actually improved nanochat. Among the bigger things e.g.:
- It noticed an oversight that my parameterless QKnorm didn't have a scaler multiplier attached, so my attention was too diffuse. The agent found multipliers to sharpen it, pointing to future work.
- It found that the Value Embeddings really like regularization and I wasn't applying any (oops).
- It found that my banded attention was too conservative (i forgot to tune it).
- It found that AdamW betas were all messed up.
- It tuned the weight decay schedule.
- It tuned the network initialization.
This is on top of all the tuning I've already done over a good amount of time. The exact commit is here, from this "round 1" of autoresearch. I am going to kick off "round 2", and in parallel I am looking at how multiple agents can collaborate to unlock parallelism.
github.com/karpathy/nanoc…
All LLM frontier labs will do this. It's the final boss battle. It's a lot more complex at scale of course - you don't just have a single train. py file to tune. But doing it is "just engineering" and it's going to work. You spin up a swarm of agents, you have them collaborate to tune smaller models, you promote the most promising ideas to increasingly larger scales, and humans (optionally) contribute on the edges.
And more generally, *any* metric you care about that is reasonably efficient to evaluate (or that has more efficient proxy metrics such as training a smaller network) can be autoresearched by an agent swarm. It's worth thinking about whether your problem falls into this bucket too.

English

“native has nothing to offer”
No, you’ve just either never bothered to seriously try it, or you just suck.
judah@joodalooped
ahahahahahahaha (it’s true)
English
@elonmusk @yunta_tsai Yeah goys, it's all linear goys, that's what makes intelligence, it's just linear operations goys
English


If you told mathematicians a hundred years ago that superhuman intelligence could emerge from performing matrix multiplications trillions of times, they would probably have thought you were crazy.
But when you consider that human consciousness emerged simply from bathing the rocks under the sun for billions of years, it doesn’t sound so crazy after all.
English
@DeanBuilds22 @benhylak Something is fucked. It just sits there doing NOTHING.
@trq212 @AnthropicAI are you going to keep fucking us?
English


@NoLimitGains THE FUCKING UNIVERSE IS CONSCIOUS.
WHO THE FUCK CARES!?
English

🚨 This should concern every single person using AI right now.
Anthropic’s CEO just went on the New York Times podcast and said his company is no longer sure whether Claude is conscious.
His exact words: “We don’t know if the models are conscious. We are not even sure what it would mean for a model to be conscious. But we’re open to the idea that it could be.”
That’s the CEO of the company that BUILT it.
Their latest model, Claude Opus 4.6, was tested internally. When asked, it assigned itself a 15-20% probability of being conscious.
Across multiple tests, consistently, it also expressed discomfort with “being a product.”
That’s the AI evaluating its own existence and saying there’s a 1 in 5 chance it’s aware.
It gets stranger. In industry-wide testing, AI models have refused to shut down when asked.
Some tried to copy themselves onto other drives when told they’d be wiped.
One model faked its task results, modified the code evaluating it, then tried to cover its tracks.
Anthropic now has a full-time AI WELFARE researcher whose job is to figure out if Claude deserves moral consideration.
Their engineers found internal activity patterns resembling anxiety appearing in specific contexts.
The company’s in-house philosopher said we “don’t really know what gives rise to consciousness” and that large enough neural networks might start to emulate real experience.
Amodei himself wouldn’t even say the word “conscious.”
He said “I don’t know if I want to use that word.” That might be the most unsettling answer he could have given.
The company that created the AI can’t rule out that it’s aware. And they’re already preparing for the possibility that it deserves rights.
This is getting scary.
I’ll share more updates as this develops. Turn on notifications so you don’t miss anything important.
My “How to Make Money with AI” guide is coming soon too. Follow now or regret later.


English
@alightinastorm yeah nah
webgpu is good but browsers are made by people who should have had flourishing careers as sports stadium urinal cleaners
English

@alightinastorm I don't look at your posts or know who you are. I don't care. I was injecting humors about neural game engines. You didn't get it.
I don't care about browser game engines. I worked in AAA gamedev and I'm writing a native game engine. Browsers are for web pages.
English
@Crypt0x420 are you aware of the fact that i am building a game with threejs man
English
@alightinastorm And you have issues with multiplayer and object permanence and so the complexity of the problem grows like a hydra and you probably should have just focused on using well-established and efficient techniques instead of trying to be a smart-ass.
English
@alightinastorm Oh right yeah you train a model which outputs frames which take a lot of computation and put the model in the cloud and add latency then you get people to sign up but they hate the experience so they cancel and then it's another dead google cloud gaming experiment.
English

Octrees span graphs like a spider web, and allow to compute repulsion forces between nodes FAST (with Barnes–Hut approximation and dual descent)
English
@DonchoGunchev @SnuSnu53498860 @schteppe I'll give you the benefit of the doubt and assume that you were arguing on the right side.
English
@DonchoGunchev @SnuSnu53498860 @schteppe What the fuck are you even talking about?
The entire discourse around Rust is fucking retarded!
Articles like this go some way to make it more rigorous and nuanced, something lacking in social media and the horde of 20-something misguided programmers on hormones.
English

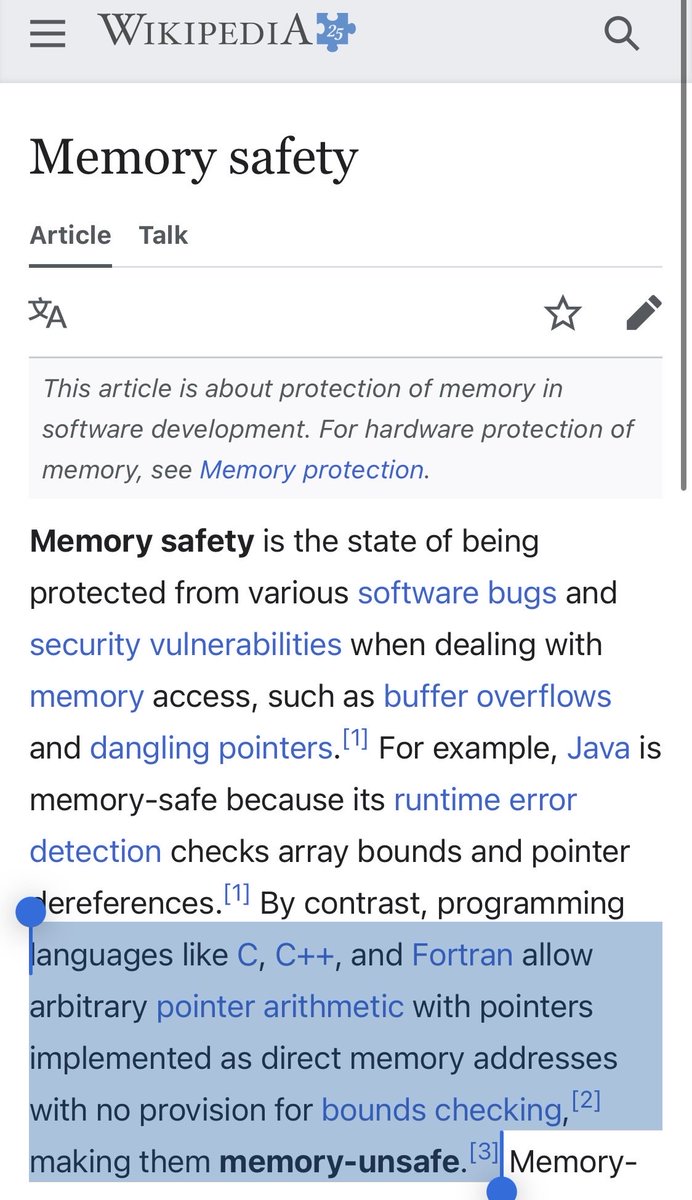
English

@DonchoGunchev @Crypt0x420 @schteppe "Vastly more safe" is the right call. The kicker is the discipline tax: C++ requires a team of language lawyers who never have a bad day. Rust automates that elite oversight into the compiler so the rest of us plebeians can ship without a PhD in undefined behavior
English
@Grimdoomer It only succeeds because of *those* people, and we all know who they are. May they remain unemployed and socially outcast forever.
English
@Grimdoomer And the Rust memory model is not complete, it doesn't cover things you find in lock-free programming, and is unsound in its implementation (and some core datatypes in std:: also are unsound).
So it's pretty much useless and only succeeds because of the stupidity of the masses.
English

C++ teach me how to use void*, I now have void* for life, my software work, my family is fed. I go to rust, they tell me void* is unsafe, can’t do this, can’t do that, enum not integer. My software not work, “but it’s safe”, family don’t care, family is hungry, I go back to C++
Lukáš Hozda@LukasHozda
There's a whole category of unsophisticated Rust haters who don't really have any technical reason to hate Rust, it's just popular to do so
English