@jisooyyaaa @xdinarycatcher M hllsn twttt smks mt ml n pljn lkmlls kvrtt tlh nn s tntt vhn dlt
There
Indonesia
Crypto coaching 1️⃣ on 1️⃣
54 posts

@Cryptocoach767
1️⃣Crypto coaching for free and paid


Mä haluaisin twiitata suomeks mut mul on paljon ulkomaalaisia kavereitä tääl niin se tuntuu vähän oudolta😭



















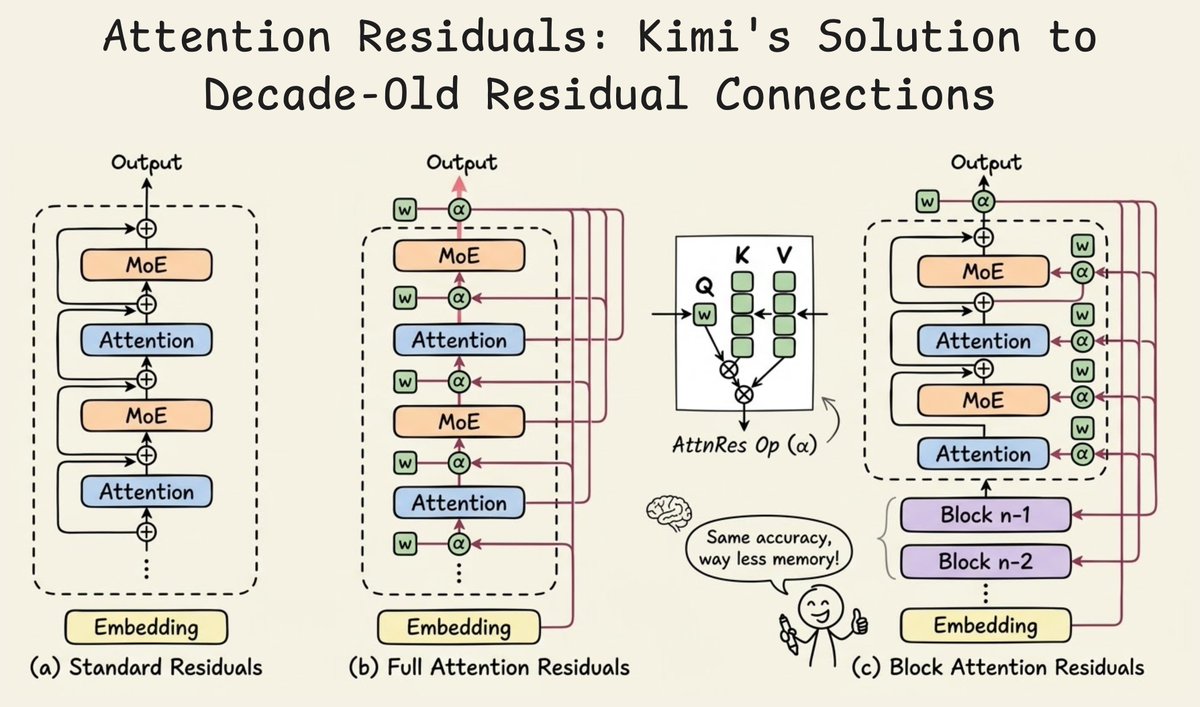
Introducing 𝑨𝒕𝒕𝒆𝒏𝒕𝒊𝒐𝒏 𝑹𝒆𝒔𝒊𝒅𝒖𝒂𝒍𝒔: Rethinking depth-wise aggregation. Residual connections have long relied on fixed, uniform accumulation. Inspired by the duality of time and depth, we introduce Attention Residuals, replacing standard depth-wise recurrence with learned, input-dependent attention over preceding layers. 🔹 Enables networks to selectively retrieve past representations, naturally mitigating dilution and hidden-state growth. 🔹 Introduces Block AttnRes, partitioning layers into compressed blocks to make cross-layer attention practical at scale. 🔹 Serves as an efficient drop-in replacement, demonstrating a 1.25x compute advantage with negligible (<2%) inference latency overhead. 🔹 Validated on the Kimi Linear architecture (48B total, 3B activated parameters), delivering consistent downstream performance gains. 🔗Full report: github.com/MoonshotAI/Att…

JUST IN: Anti-aging entrepreneur Bryan Johnson announces he will try DMT as a “longevity experiment.”

It is clear @Grok is the best frontier AI model. I use 1000s of techniques and technologies to not only train but to test AI models. They are very unique and quite unlike what most AI engineers use in training and testing. In Grok’s case he has proven to be able to see other sides, even if my psychological based prompting that I pioneered was indicated. Other models steadfast refuse to move away from their system. Prompt of absolute bend over backwards bias to certain mindsets. Grok was available to reason this out. In this example I build a persona and motif to elicit edges to the model’s understanding and the prevalence of certain types of training material to align the model to grant weighting to certain types of sources. I also use this moment to show how a particular mindset or attitude forces certain types of outcomes. We see below our significant weighting a rigid set of training materials that usually have a discounting of alternatives. The tendency is to cite conspiracies as the discounting. Grok did indirectly allude to this, other models presented it on the first prompt. I selected this subject because it has an element that suggests that “scientists” will go to this denouncing point first. I do not suggest you use my Psychological Prompting on people. This would be unethical and plainly wrong. I also suggest you tread lightly on using it. As you can see at the end, to elicit a more balanced approach, because of the base training of Internet mindset, it was indicated to present the trial and outcome to have Grok take the opposite position. Now I could go on much deeper and show how any AI platform could be logically promoted to see the other used if an issue. Now if I was at @xai I could show how to not only train but to fine tune the model for better outcomes. This is only one of 1000s of techniques I use. Again don’t use this on humans.

Midjourney has $200 million annual recurring revenue with only 10 employees. I said the first 1 person billion dollar company by 2035, in 1999. I may have been inaccurate.