John
161 posts


John
@D8taJohn
Data Expert | Leveraging generative AI, agentic workflows & scalable ML | Building tomorrow's intelligence today | Insights on evolving AI




how tf is is so difficult to pay anthropic for API use? They lose the auto top-up setting randomly when they fail a charge, then don't notify you until they cut off access. Then you try to pay, and the billing page breaks or times out. @openrouter see you soon!




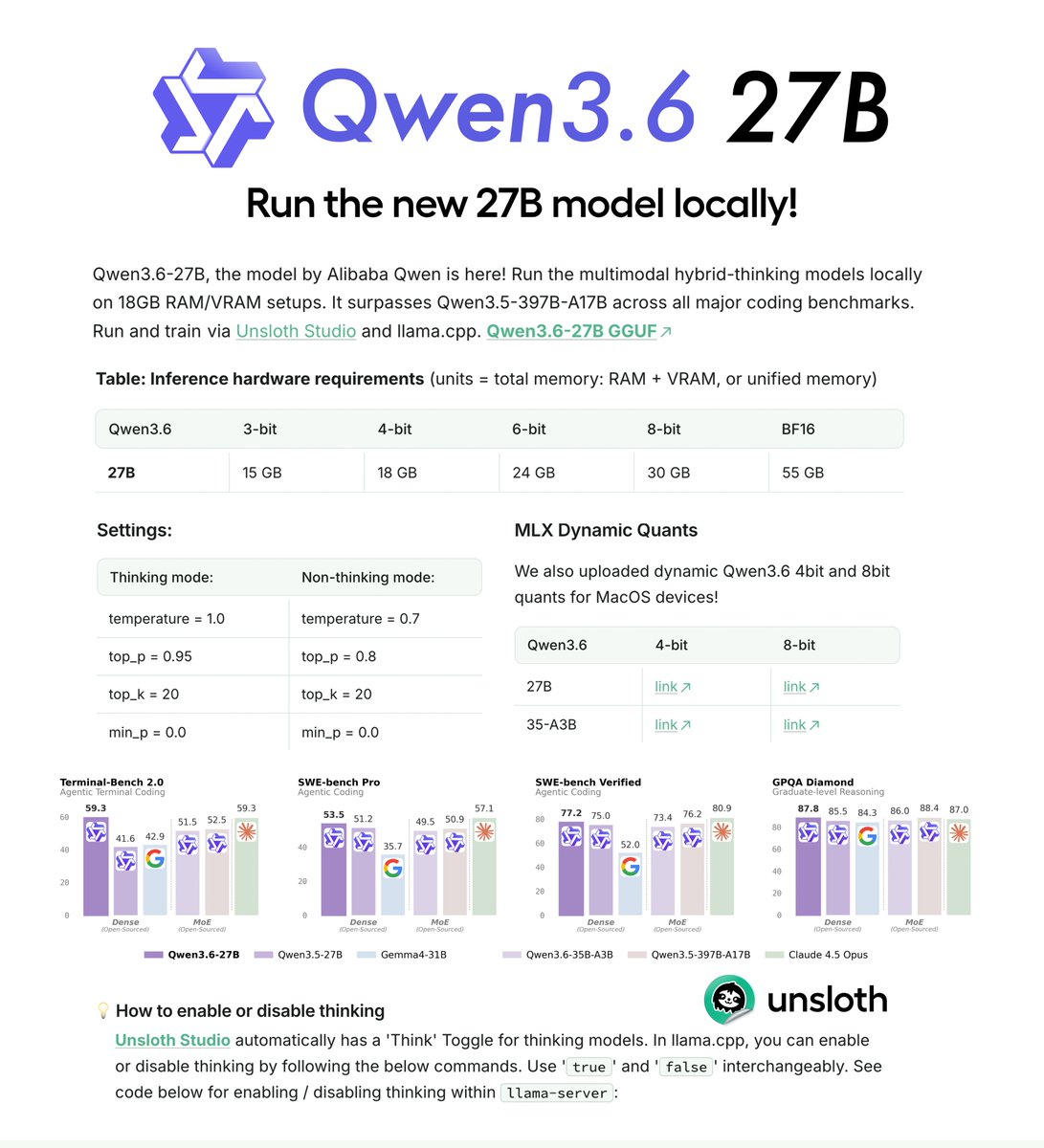
🚀 Meet Qwen3.6-27B, our latest dense, open-source model, packing flagship-level coding power! Yes, 27B, and Qwen3.6-27B punches way above its weight. 👇 What's new: 🧠 Outstanding agentic coding — surpasses Qwen3.5-397B-A17B across all major coding benchmarks 💡 Strong reasoning across text & multimodal tasks 🔄 Supports thinking & non-thinking modes ✅ Apache 2.0 — fully open, fully yours Smaller model. Bigger results. Community's favorite. ❤️ We can't wait to see what you build with Qwen3.6-27B! 👀 🔗👇 Blog: qwen.ai/blog?id=qwen3.… Qwen Studio: chat.qwen.ai/?models=qwen3.… Github: github.com/QwenLM/Qwen3.6 Hugging Face: huggingface.co/Qwen/Qwen3.6-2… huggingface.co/Qwen/Qwen3.6-2… ModelScope: modelscope.cn/models/Qwen/Qw… modelscope.cn/models/Qwen/Qw…


I spent a lot of time bugging many companies about my keyboard problems. Framework listened. They built my dream keyboard. I am so excited.


Meet Kimi K2.6: Advancing Open-Source Coding 🔹Open-source SOTA on HLE w/ tools (54.0), SWE-Bench Pro (58.6), SWE-bench Multilingual (76.7), BrowseComp (83.2), Toolathlon (50.0), Charxiv w/ python(86.7), Math Vision w/ python (93.2) What's new: 🔹Long-horizon coding - 4,000+ tool calls, over 12 hours of continuous execution, with generalization across languages (Rust, Go, Python) and tasks (frontend, devops, perf optimization). 🔹Motion-rich frontend - Videos in hero sections, WebGL shaders, GSAP + Framer Motion, Three.js 3D. 🔹Agent Swarms, elevated - 300 parallel sub-agents × 4,000 steps per run (up from K2.5's 100 / 1,500). One prompt, 100+ files. 🔹Proactive Agents - K2.6 model powers OpenClaw, Hermes Agent, etc for 24/7 autonomous ops. 🔹Claw Groups (research preview) - bring your own agents, command your friends', bots & humans in the loop. - K2.6 is now live on kimi.com in chat mode and agent mode. For production-grade coding, pair K2.6 with Kimi Code: kimi.com/code - 🔗 API: platform.moonshot.ai 🔗 Tech blog: kimi.com/blog/kimi-k2-6 🔗 Weights & code: huggingface.co/moonshotai/Kim…

Moonshot’s Kimi K2.6 is the new leading open weights model. Kimi K2.6 lands at #4 on the Artificial Analysis Intelligence Index (54) behind only Anthropic, Google, and OpenAI (all 57) Key takeaways: ➤ Increase in performance on agentic tasks: @Kimi_Moonshot's Kimi K2.6 achieves an Elo of 1520 on our GDPval-AA evaluation, which is a marked improvement over Kimi K2.5’s Elo of 1309. GDPval-AA is our leading metric for general agentic performance, measuring the performance on knowledge work tasks such as preparing presentations and analysis. Models are given code execution and web browsing tools in an agentic loop via our open source reference agentic harness called Stirrup. This continues Kimi K2.6’s strength in tool use, maintaining a 96% score on τ²-Bench Telecom, placing it among other frontier models in this category. ➤ Low hallucination rate: Kimi K2.5 scores 6 on the AA-Omniscience Index, our knowledge evaluation measuring both accuracy and hallucination rate. This score is primarily driven by a comparatively low hallucination rate of 39% (reduced from Kimi K2.5’s 65%), indicating a greater capability to abstain rather than fabricate knowledge when the model is uncertain. Kimi K2.6’s low hallucination rate places it similarly to other models such as Claude Opus 4.7 (36%) and MiniMax-M2.7 (34%) ➤ High token usage: Kimi K2.6 demonstrates high token usage, but is in line with other frontier models in the same intelligence tier. To run the full Artificial Analysis Intelligence Index, Kimi K2.6 used ~160M reasoning tokens. This is slightly lower than Claude Sonnet 4.6 (~190M reasoning tokens) but much higher than GPT 5.4 (~110M reasoning tokens). ➤ Open weights: Kimi K2.6 is a Mixture-of-Experts (MoE) model with 1T total parameters and 32B active, same as the previous two generations of models Kimi K2 Thinking and Kimi K2.5. Kimi K2.6 again pushes the open weights frontier in intelligence. ➤ Third Party Access: Kimi K2.6 is accessible through Moonshot’s First Party API as well as third party API providers Novita, Baseten, Fireworks, and Parasail ➤ Multimodality: Kimi K2.6 supports Image and Video input and text output natively. The model’s max context length remains 256k. Further analysis in the threads below.
WORST JOKE EVER! You're welcome

Meet Kimi K2.6: Advancing Open-Source Coding 🔹Open-source SOTA on HLE w/ tools (54.0), SWE-Bench Pro (58.6), SWE-bench Multilingual (76.7), BrowseComp (83.2), Toolathlon (50.0), Charxiv w/ python(86.7), Math Vision w/ python (93.2) What's new: 🔹Long-horizon coding - 4,000+ tool calls, over 12 hours of continuous execution, with generalization across languages (Rust, Go, Python) and tasks (frontend, devops, perf optimization). 🔹Motion-rich frontend - Videos in hero sections, WebGL shaders, GSAP + Framer Motion, Three.js 3D. 🔹Agent Swarms, elevated - 300 parallel sub-agents × 4,000 steps per run (up from K2.5's 100 / 1,500). One prompt, 100+ files. 🔹Proactive Agents - K2.6 model powers OpenClaw, Hermes Agent, etc for 24/7 autonomous ops. 🔹Claw Groups (research preview) - bring your own agents, command your friends', bots & humans in the loop. - K2.6 is now live on kimi.com in chat mode and agent mode. For production-grade coding, pair K2.6 with Kimi Code: kimi.com/code - 🔗 API: platform.moonshot.ai 🔗 Tech blog: kimi.com/blog/kimi-k2-6 🔗 Weights & code: huggingface.co/moonshotai/Kim…