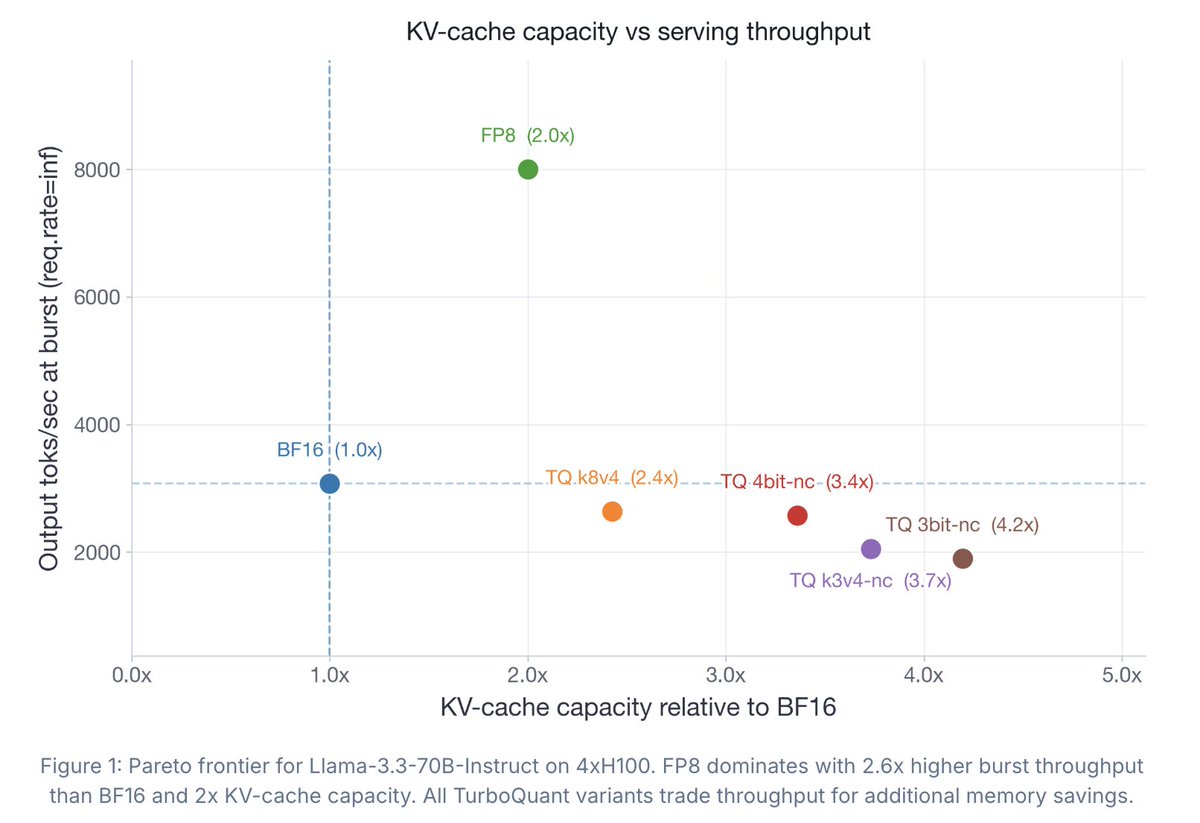
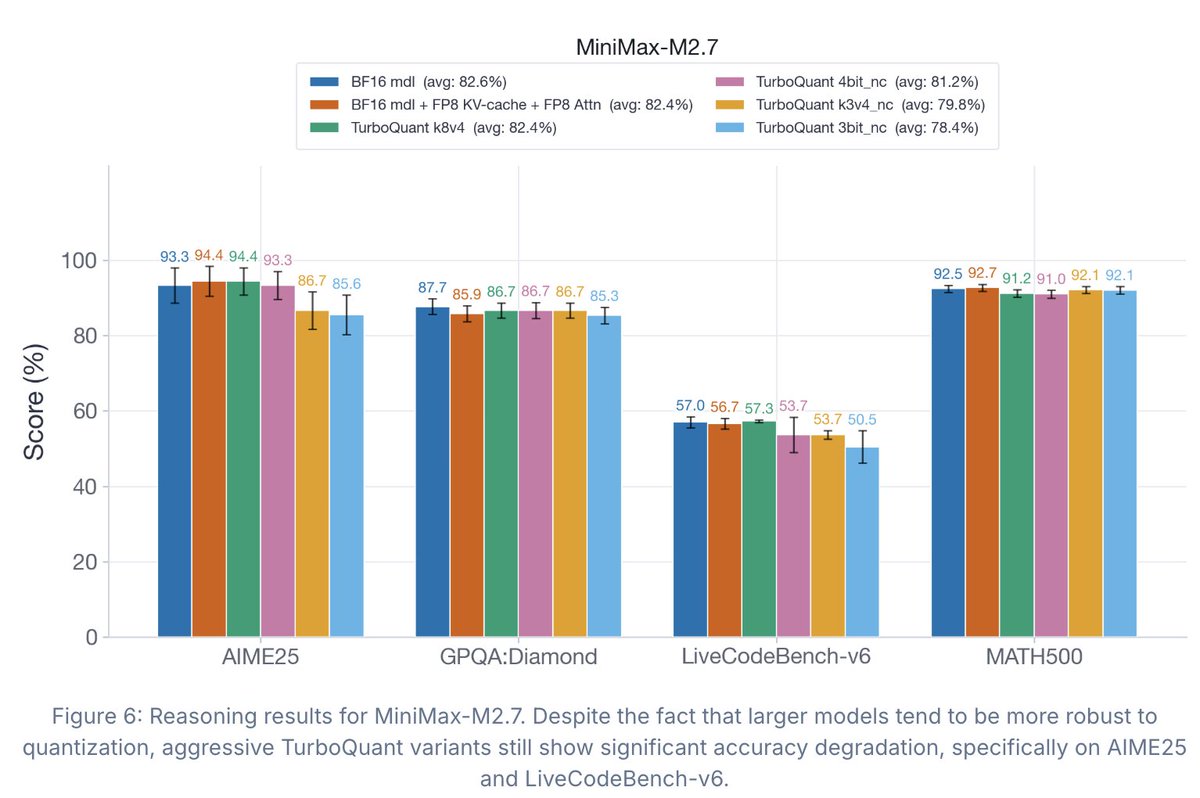
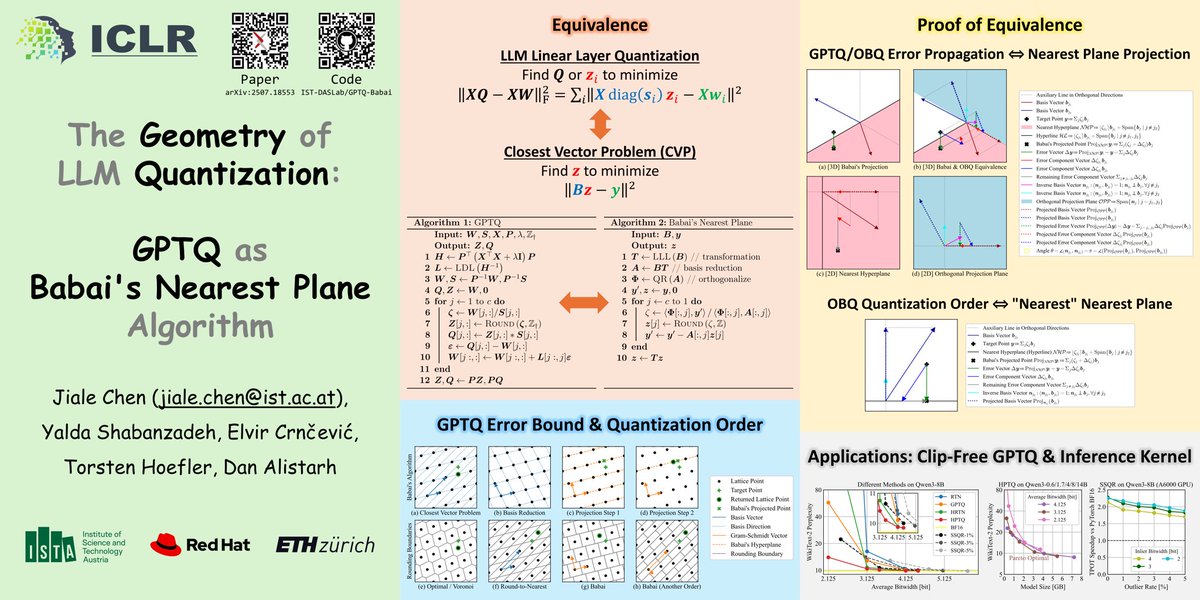
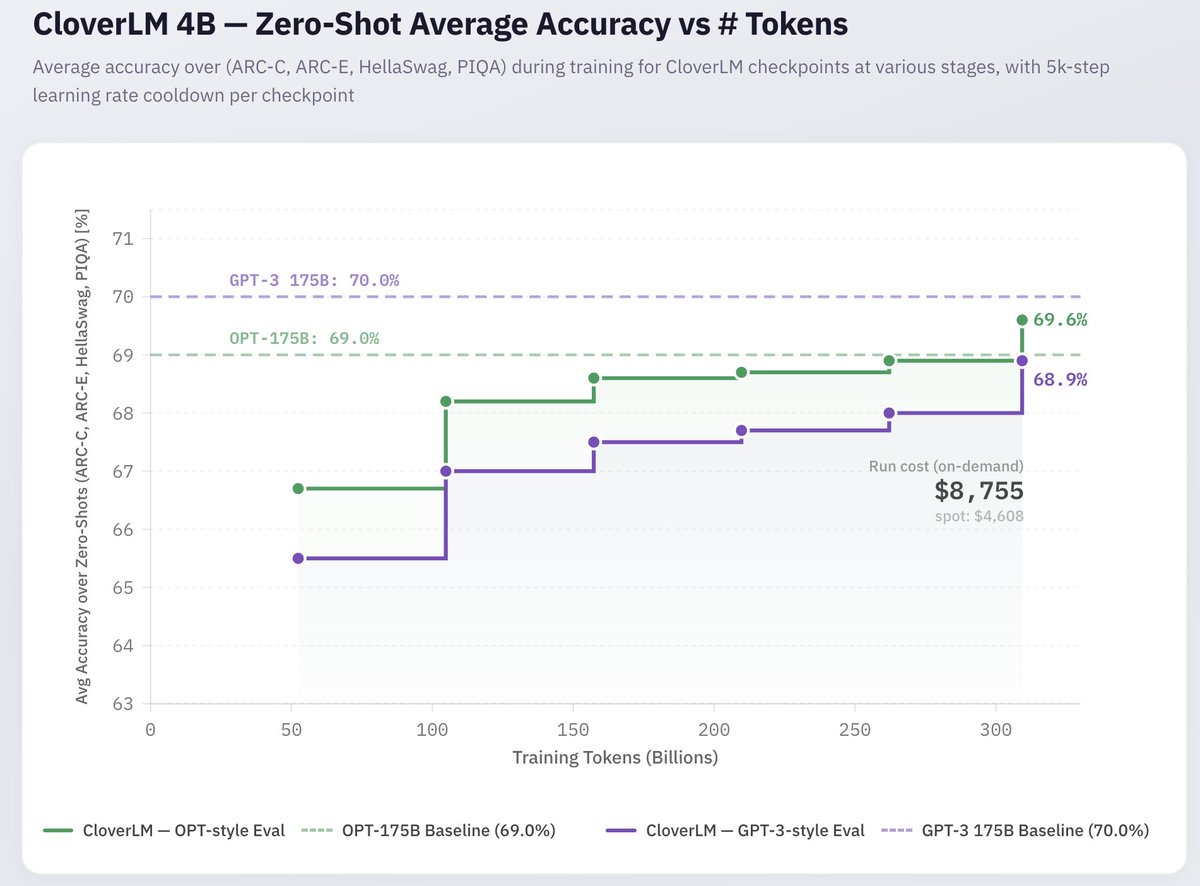
As always, our release is fully open:
💻 Paper and code: arxiv.org/pdf/2604.18556
@huggingface : huggingface.co/collections/IS…
Credits: Alireza Dadgarnia, Soroush Tabesh, Mahdi Nikdan, Michael Helcig, Eldar Kurtić, and Max Kleinegger
We thank @RedHat_AI and @verdacloud for the support!
English