Sabitlenmiş Tweet

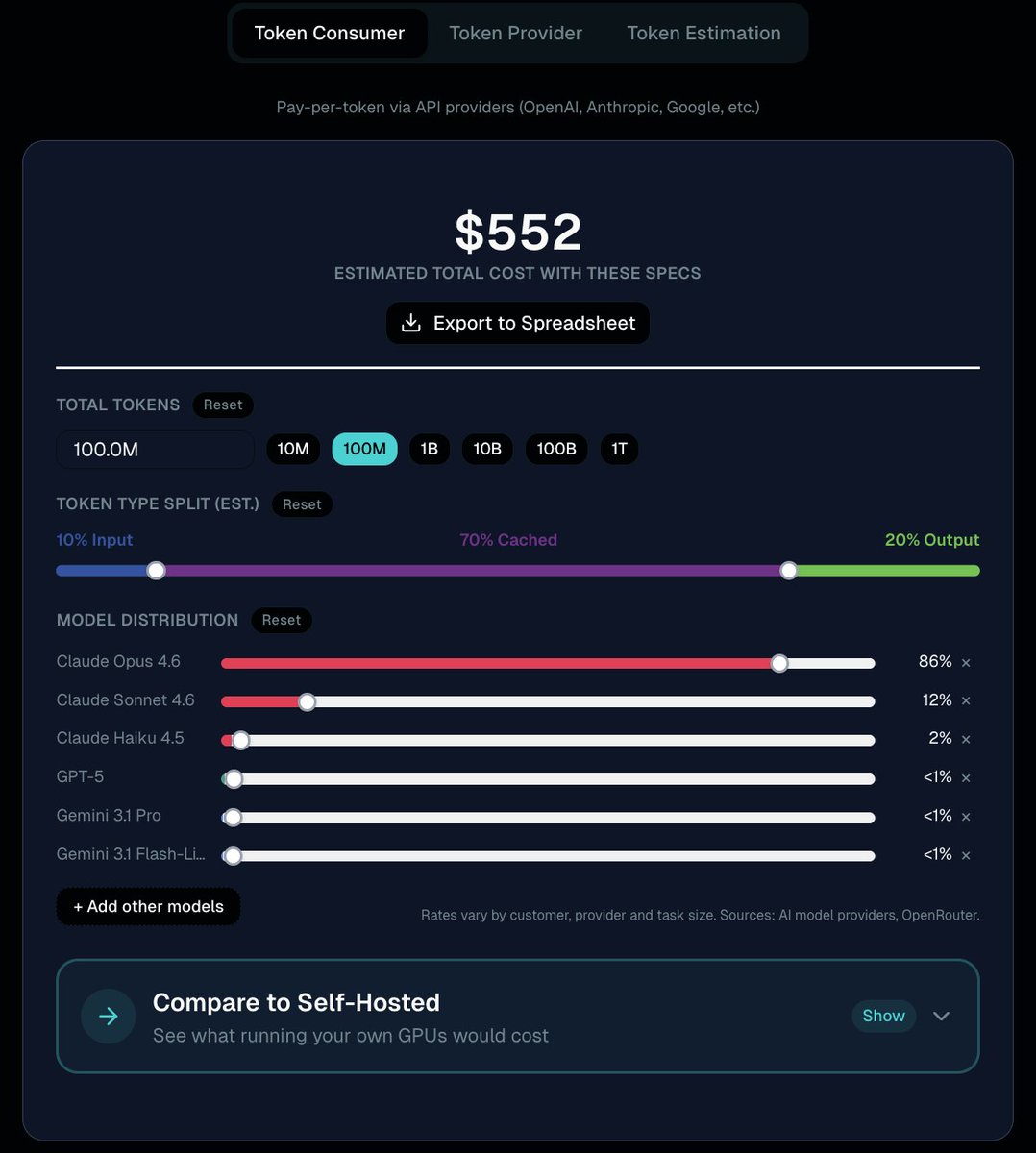
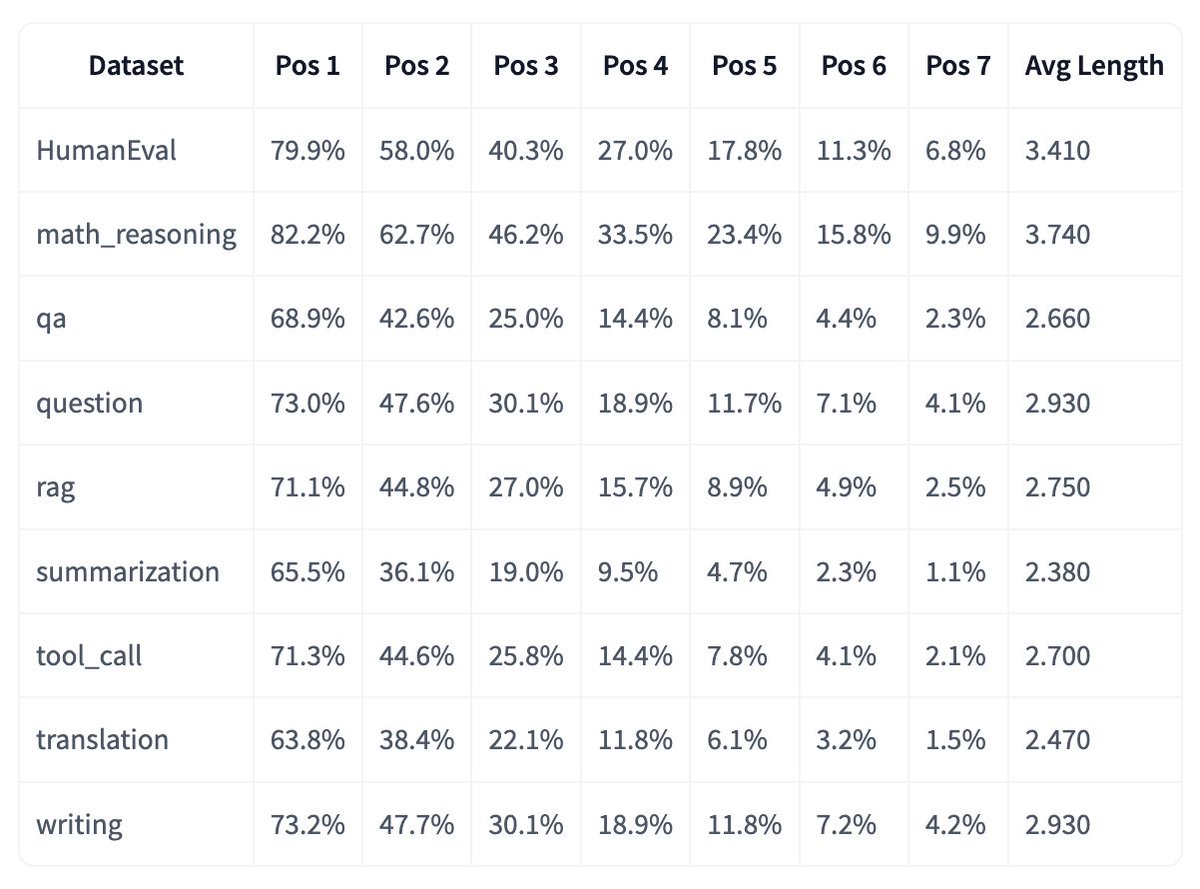
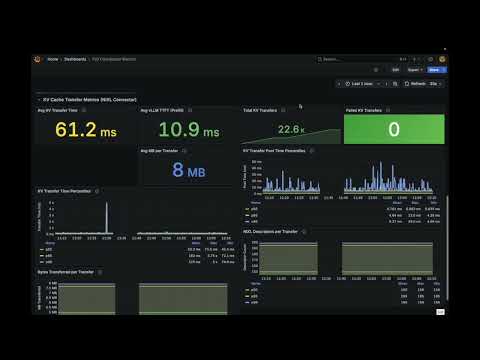
Red Hat B200 submission beat the best B300 submission by 50% on Qwen3-VL server scenario in MLPerf v6.0. Not newer hardware. Better software and performance tuning.
We submitted across diverse scenarios and accelerators, including both NVIDIA and AMD GPUs. Shoutout to @vllm_project for hardware flexibility.
More from our v6.0 submission:
- GPT-OSS-120B on B200: 93,071 tok/s, 8% ahead of the next B200 result. First MLPerf submission for a model this scale on Kubernetes (OpenShift AI + llm-d).
- Whisper on H200: 36,396 tok/s, 13% faster than the best H200 submitter.
@vllm_project was used by 20 submitters in MLPerf v6.0, up from 5 in v5.1. It ran across every GPU in our stack: NVIDIA H200, B200, L40S, and AMD MI350X.
Full breakdown: redhat.com/en/blog/red-ha…

English