Lingjun_C
12 posts









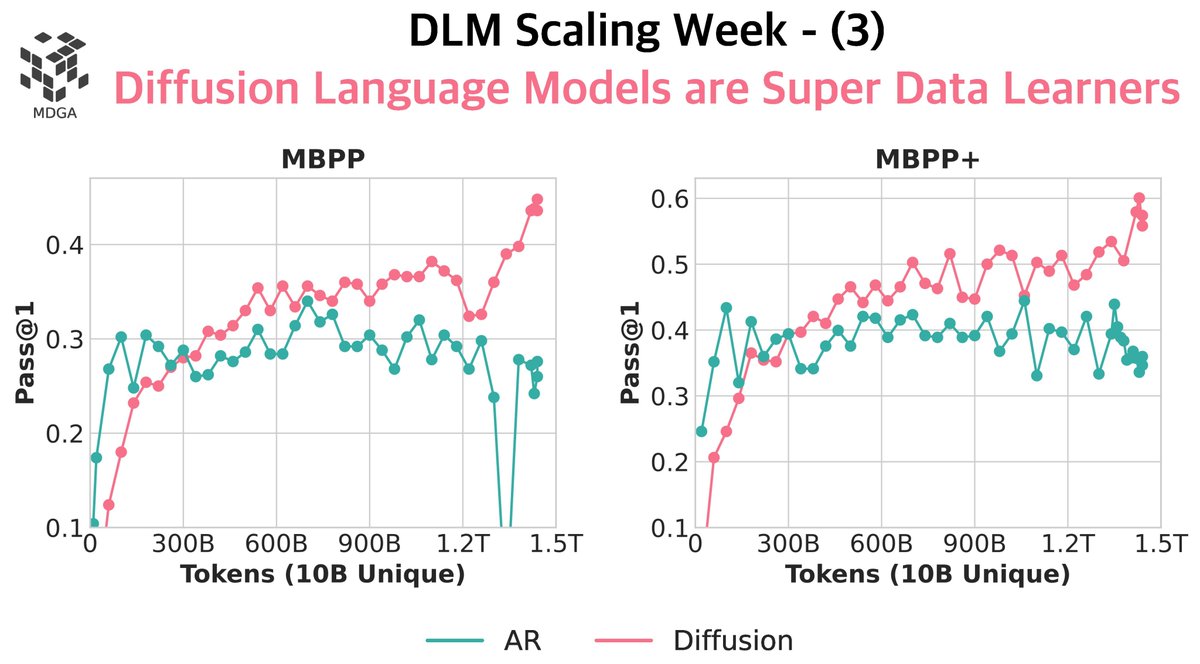
Token crisis: solved. ✅ We pre-trained diffusion language models (DLMs) vs. autoregressive (AR) models from scratch — up to 8B params, 480B tokens, 480 epochs. Findings: > DLMs beat AR when tokens are limited, with >3× data potential. > A 1B DLM trained on just 1B tokens hits 56% HellaSwag & 33% MMLU — no tricks, no cherry-picks. > No saturation: more repeats = more gains. 🚨 ”x.openreview.net” We also dissected the serious methodological flaws in our parallel work “Diffusion Beats Autoregressive in Data-Constrained Settings” — let’s raise the bar for open review! 🔗 Blog & details: jinjieni.notion.site/Diffusion-Lang… 18 🧵s ahead:







Introducing MCPMark, a collaboration with @EvalSysOrg and @lobehub! We created a challenging benchmark to stress-test MCP use in comprehensive contexts. - 127 high-quality data samples created by experts. - GPT-5 takes the current lead and achieves a Pass@1 of 46.96% while the other models fall in the range of 10-30%. - Diverse test cases on Notion, Github, Filesystem, Playwright (browser), and Postgres. 9🧵s ahead

Token crisis: solved. ✅ We pre-trained diffusion language models (DLMs) vs. autoregressive (AR) models from scratch — up to 8B params, 480B tokens, 480 epochs. Findings: > DLMs beat AR when tokens are limited, with >3× data potential. > A 1B DLM trained on just 1B tokens hits 56% HellaSwag & 33% MMLU — no tricks, no cherry-picks. > No saturation: more repeats = more gains. 🚨 ”x.openreview.net” We also dissected the serious methodological flaws in our parallel work “Diffusion Beats Autoregressive in Data-Constrained Settings” — let’s raise the bar for open review! 🔗 Blog & details: jinjieni.notion.site/Diffusion-Lang… 18 🧵s ahead:

