Daniel Hesslow retweetledi

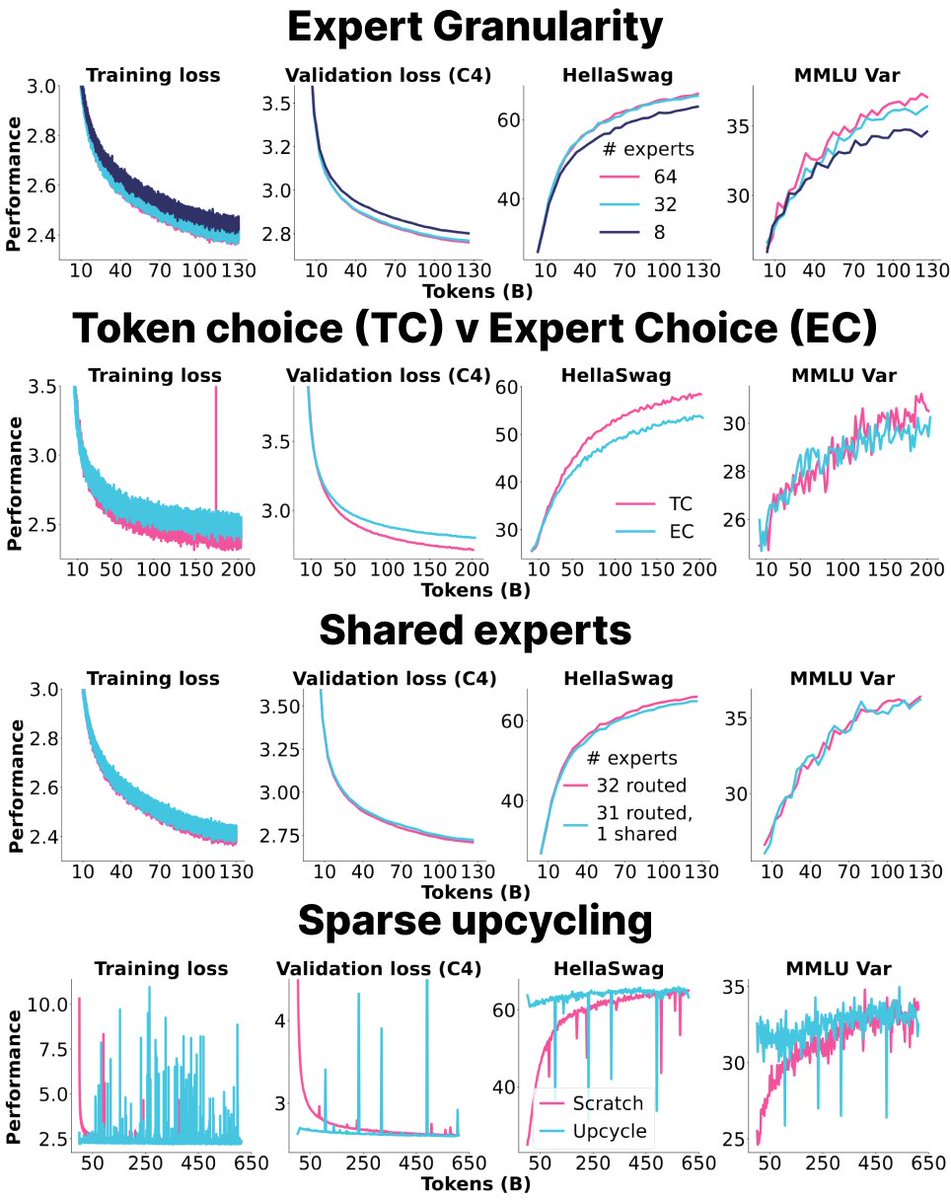
GSPO is everywhere. It powers Qwen3. It "fixes" GRPO. But what is it?
We made a simple visual explanation. No jargon, no ML background needed. 👇

English
Daniel Hesslow
170 posts

@DanielHesslow
Making gpus go brrr in unison at @AdaptiveML


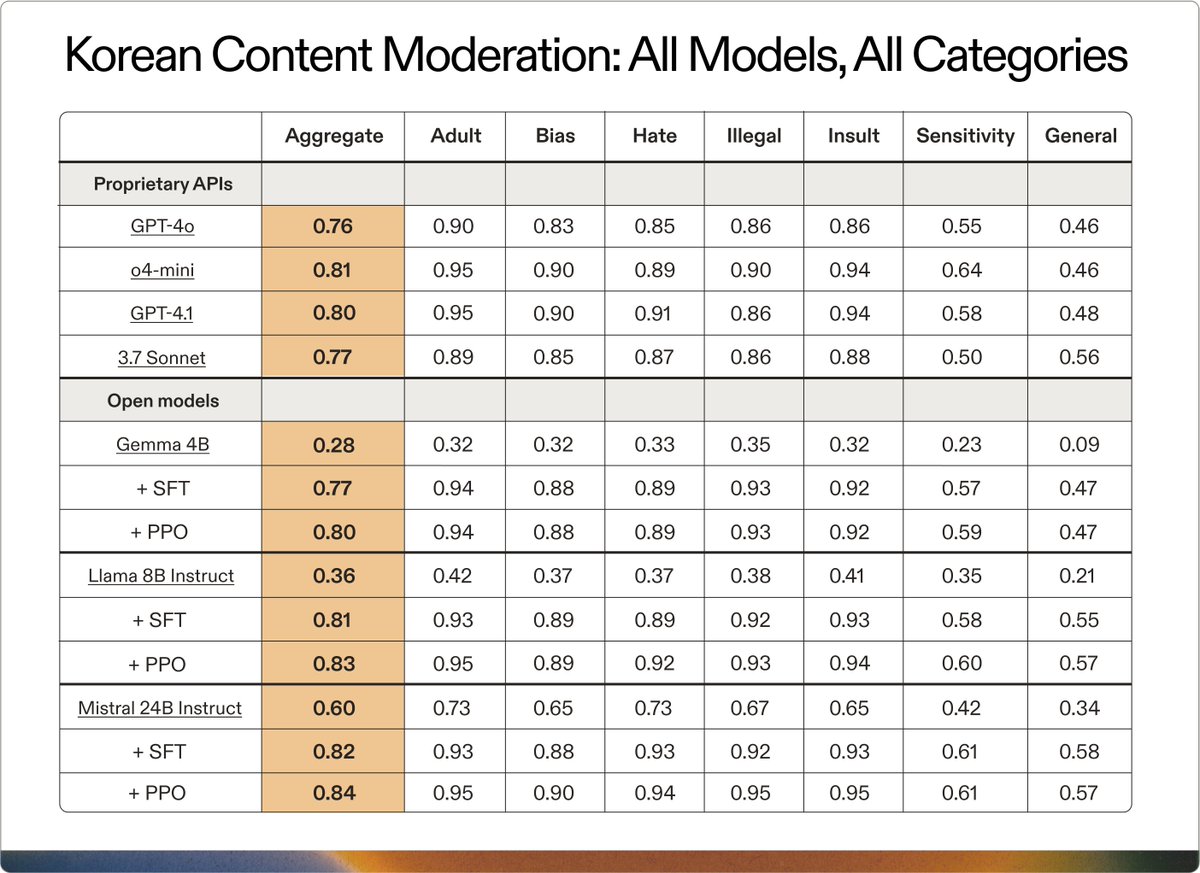

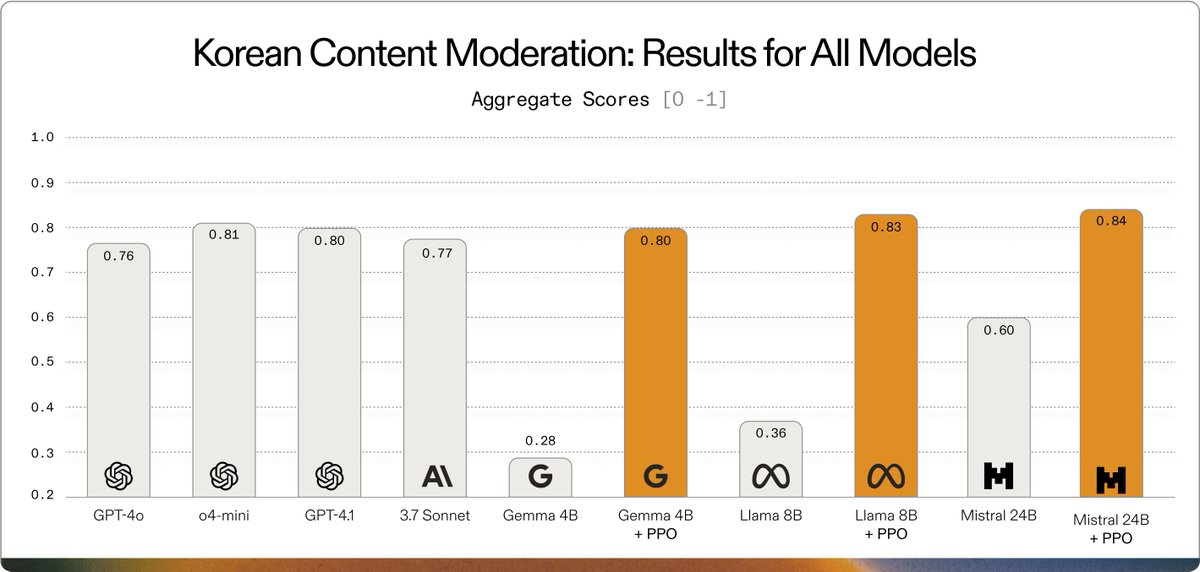
Build enterprise AI without the latency and cost of massive models. Learn how @AdaptiveML used Gemma 3 to create a multilingual customer service moderation LLM for @SKtelecom to support their 23M+ subscribers who speak a mix of English and Korean. deepmind.google/models/gemma/g…


ES-FoMo is back for round three at #ICML2025! Join us in Vancouver on Saturday July 19 for a day dedicated to Efficient Systems for Foundation Models: from 💬reasoning models to🖼️scalable multimodality, 🧱efficient architectures, and more! Submissions due May 26! More below 👇
Pretrained LLMs are aliens of extraordinary intelligence, yet little understanding. 👽 How do post-training techniques like 𝐒𝐅𝐓, 𝐑𝐄𝐈𝐍𝐅𝐎𝐑𝐂𝐄, and 𝐏𝐏𝐎 work in-tandem to turn these aliens into helpful AI assistants? 🧵 👇


We are excited to share our latest work on speculative decoding for high-throughput inference! Before this work, we thought speculative decoding was useless at large batch sizes since the GPUs would go brrrr from processing all the different inputs. Much to our surprise, we discovered speculative decoding is quite useful if the inputs are long enough because decoding once again becomes memory-bound from the large KV cache. In fact, we show that speculative decoding can improve latency AND throughput by up to 2x in this regime! Read more here: together.ai/blog/speculati…