David Mikhail retweetledi

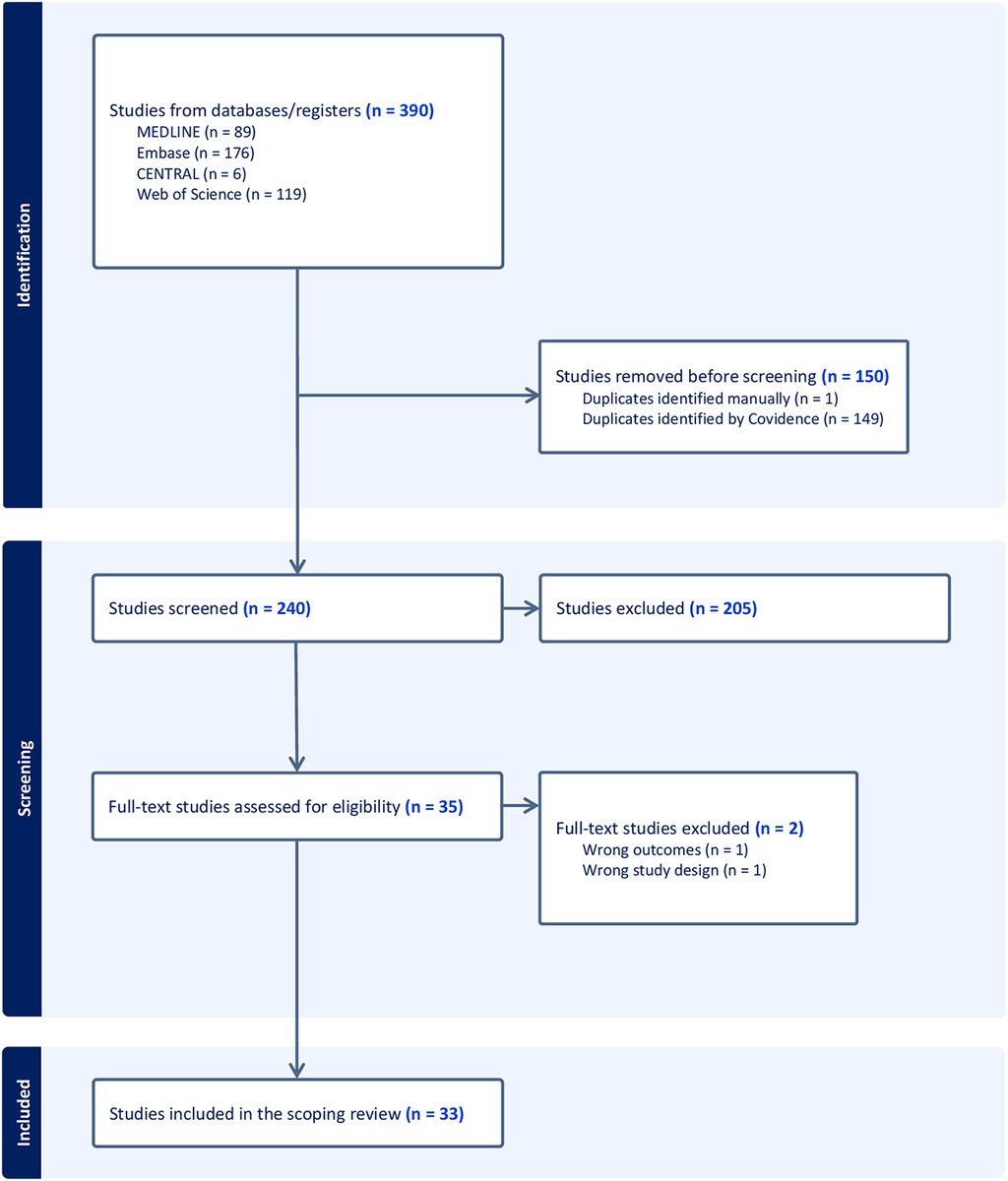
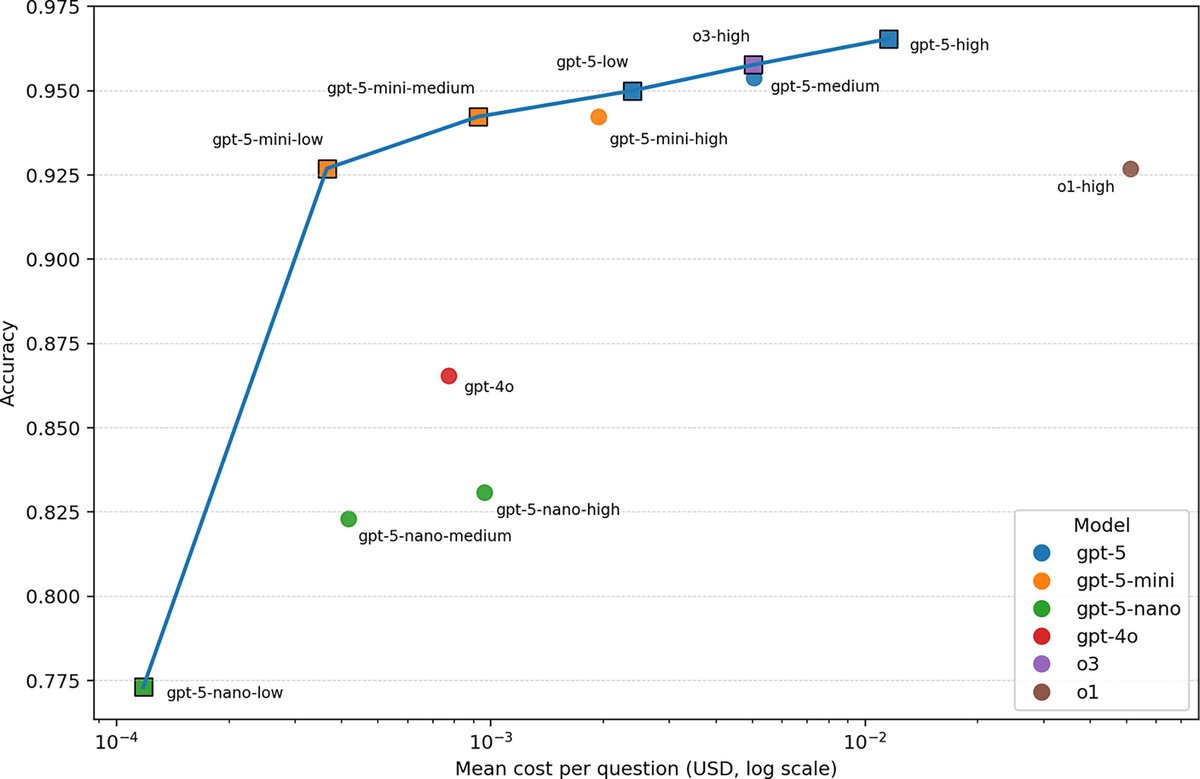
Performance of GPT-5 Frontier Models in Ophthalmology Question Answering
ow.ly/8QLe50XHpu9
@FaresAntaki @DavidMikhail01 @DanielMiladMD @SumitSharmaMD @pearsekeane, @YihTham @Renaudduval1
#ophthalmology
English
David Mikhail
12 posts












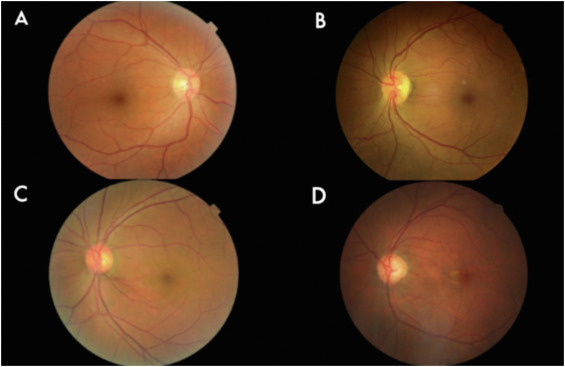
Code-Free Deep Learning Glaucoma Detection On Color Fundus Images ow.ly/Yoa250UQgab @DanielMiladMD @Renaudduval1 @DavidMikhail01 @FaresAntaki @pearsekeane @thedurreffect #ophthalmology