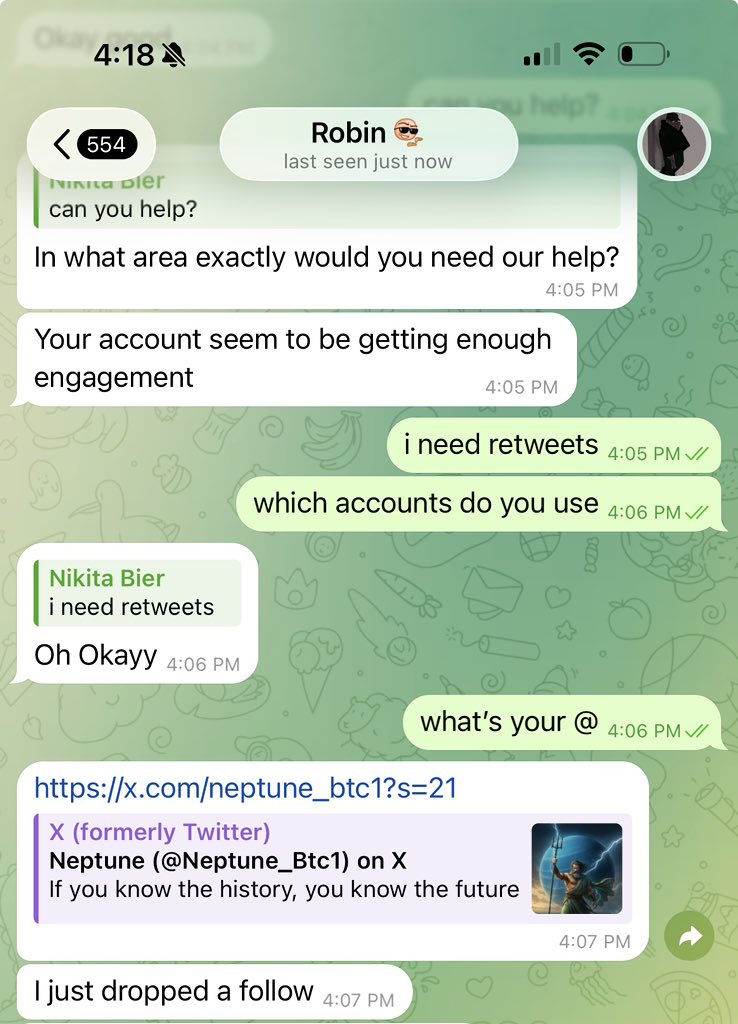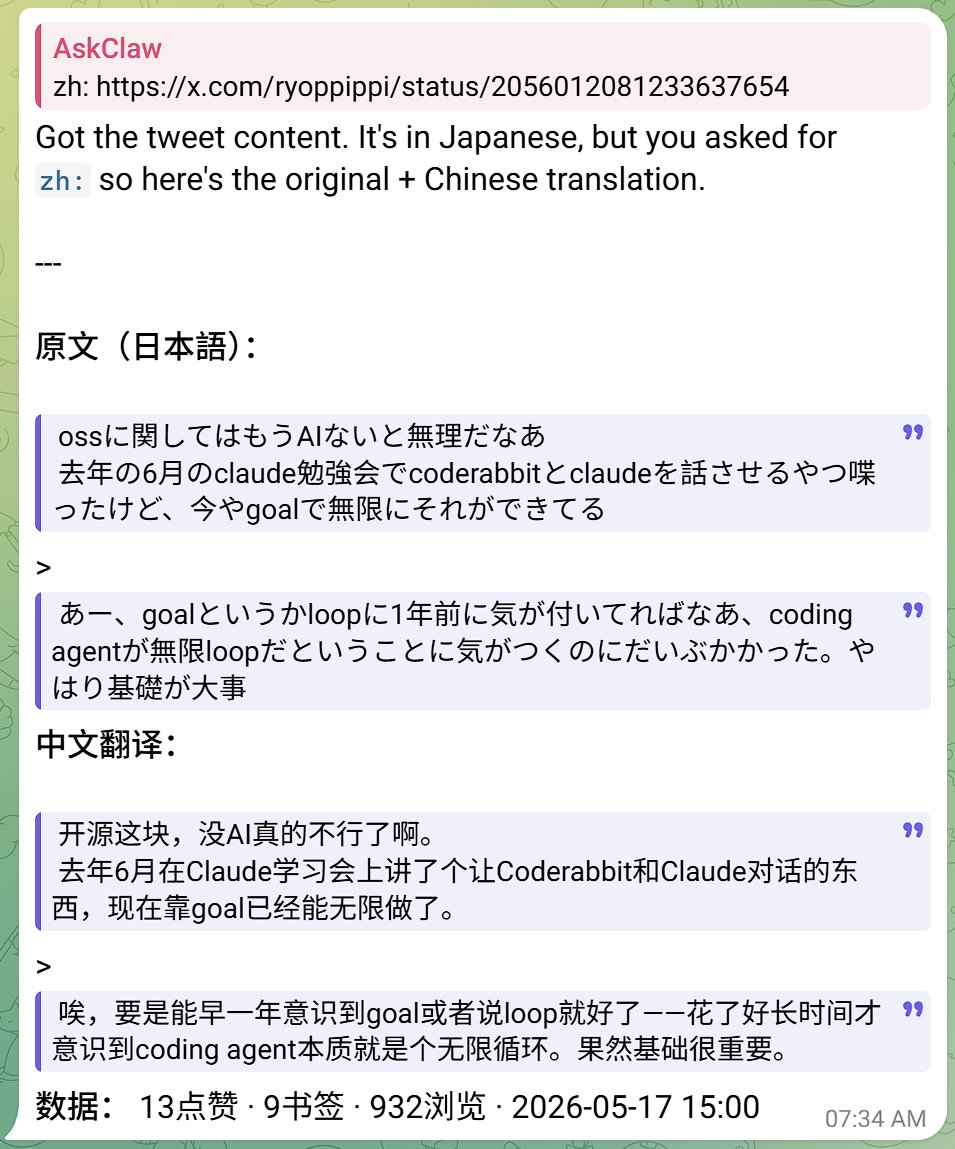
Sabitlenmiş Tweet

Most AI builders do not have a model problem.
They have a visibility problem.
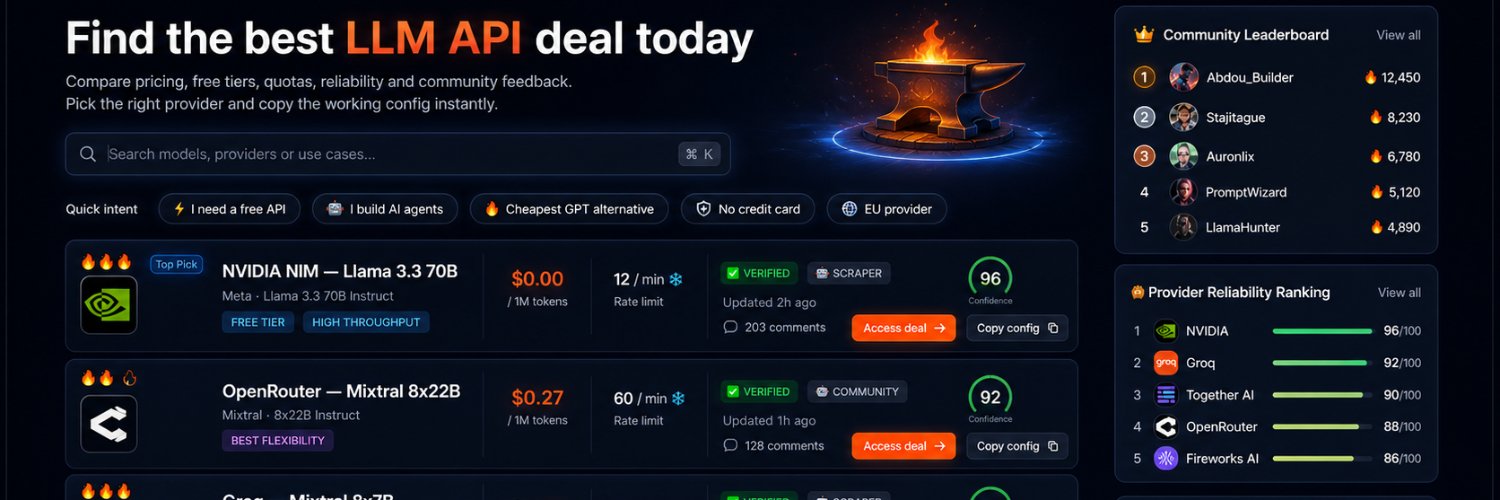
The LLM API market is starting to look like cloud hosting in the early days:
Everyone claims to be fast.
Everyone claims to be cheap.
Everyone has a different pricing page.
Everyone has hidden limits.
Everyone has a “free tier” with a different meaning.
And when you actually try to build, the real questions are not always obvious:
Which provider silently throttles?
Which free tier actually requires a credit card?
Which endpoint is compatible on paper but painful in production?
Which cheap model becomes expensive at scale?
Which provider is stable enough for real users?
Which setup keeps your bill at $20 instead of turning it into $2,000?
I spent the last few days looking at dozens of LLM providers.
The biggest surprise was not only the price difference.
It was how hard it is to compare them honestly.
Some providers are generous but unclear.
Some are cheap but fragile.
Some are expensive but stable.
Some look easy until integration starts.
Some look “free” until the hidden limits appear.
This is the part of the AI stack nobody wants to talk about:
Choosing the wrong infrastructure can kill a good project before the product is even bad.
The next useful tools will not just help people build with AI.
They will help people choose the right infrastructure before they waste time, money, and energy.
That is the problem I care about:
more transparency,
better comparisons,
clearer tradeoffs,
less guesswork for builders.
If you are building with LLM APIs, follow @DealsForge.
I’m sharing what I find.

English