
Deason
23 posts

如果我在三年前知道Jump Desktop的话我会少走很多很多的弯路🫠
这个东西真的太厉害了,在外面走公网也能Retina高清流畅操作,真的就完全是把Mac捧在手上的感觉!
中文

【开工季福利来袭!!!】
为了感谢大家对我们的支持,我们打算免费送一台 Mac Mini256GB + 2000刀PackyAPI额度,助力2026年VibeCoding 和养殖龙虾!
一等奖:macmini 256GB 一台
二等奖:Packyapi额度100 刀✖️10 人
三等奖:Packyapi额度50 刀✖️20 人
点赞+评论+转发即可参与抽奖!(中奖后我们会仔细检查哦)
3 月 8 号截止~
网站链接:packyapi.com
相关文档:docs.packyapi.com

中文

今天会再拉个内测2群
把前几天大家评论了但没收到邀约的朋友们拉进来
顺便问一下 有没有什么功能是你特别希望在牛马AI看到的?
Yangyi@yangyi
自从AI做出来牛马AI后,我就再没打开过obsidian 我没有危言耸听,因为我更习惯这种使用方式 我不知道你会不会也和我一样,弃用掉古早的这些工具,转而投奔新时代的人机协同基站
中文
@shandianshuo 可以有一个流式输出的功能吗?现在有一个体验不好的地方是我输了一大堆,但是我不知道模型有没有听到我说话,甚至他有时候自己就直接把整段话都丢掉了,我也不知道,有时候就是我说了一大堆,结果等最后发现他什么都没有说出来,这个功能隔壁的西瓜说好像已经有了。
中文

⚡️ 闪电说 V0.5.0 正式发布
我们问了自己一个危险的问题:
"闪电说,是全球最快的 AI 语音输入法吗?"
🎬 实测: 用闪电说配合 Claude Code 写代码(视频无加速)
📊 2023版 Mac Pro 测试数据:0.12s 延迟
⚡️ 0.12秒 = 话音还未落,文字已上屏
这速度,够不够快?👇
支持 Mac/Win,下载地址见评论
#闪电说 #AI语音输入法 #ClaudeCode
中文

原来大学那段转码经历,我就悟到了“第一性原理”
大学我学建筑安全专业。
VB 课老师说:“不是计算机专业的,二级 C 根本过不了。”
全班都笑了,我也笑了,但我心里想:
“真有规则规定我学不会吗?”
我开始从零写代码、查报错、调 Bug。
那时没有 ChatGPT,每个错误都得自己追到最底层。
后来我才明白,那其实就是“第一性原理”在起作用。
它的核心不是推理,而是拆解:
✅ 把复杂问题拆成最小单元
✅ 不背答案,只问“为什么”
✅ 能讲给外行听懂,才算真懂
我学 Spark、Kafka 也用同样方式:
不会就问“数据怎么流动”,直到能讲清楚。
几年后我发现:
掌握第一性原理的人,不会被技术迭代淘汰,
因为他们学的是原理,不是工具。
第一性原理不是挑战权威,
而是让你在没人指路时,也能自己推理出答案。
经验帮你起步,原理帮你破圈。
别问别人能不能做到,
先问自己:
“这件事的底层逻辑,真有那么复杂吗?”

中文

Cherry Studio 1.7.0 beta 1 的核心是引入了革命性的智能体(Agent)系统。这标志着 Cherry Studio 从一个AI 对话客户端进化为一个拥有自主思考和行动能力的智能平台。
与被动响应的助手不同,Agent是一个具备自主能力的系统。它融合了任务规划、工具调用、文件操作和多轮深度推理能力,能够像初级开发者一样独立完成复杂任务。其核心是基于强大的Claude Code SDK构建,将命令行工具的强劲能力赋予了图形化的直观界面。
在功能上,Agent系统提供了极高的灵活性和控制权:
· 极简编排:用户可以自由选择包括Claude、DeepSeek V3、Kimi K2等顶尖模型作为Agent的核心驱动。
· 自定义能力:通过指令、工具/权限组合和工作目录定义,用户可以创造出各种专属Agent,如数据分析师、长文写手或文件管家。
· 生态扩展:深度集成了来自百炼、魔搭、Higress等领先服务商的MCP资源,使Agent的能力可以无限扩展。
Cherry Studio agent 系统 配备了直观的图形化管理界面,用于创建、配置和管理每一个Agent。每个Agent任务都在其专属会话中进行,支持持久化的消息历史和上下文追踪,方便用户回顾其“思考”过程并进行干预。
此次 Cherry Studio Agent系统作为一个生态的起点,未来将依托Claude Code繁荣的生态系统持续成长。




中文

从零实现 vLLM 的第三篇文章,我们来了解如何加速 Attention 计算,学习 FlashAttention 的原理。
要理解 FlashAttention 的巧妙,我们必须先理解传统注意力机制的“笨拙”之处。
匹配度计算(QK):你(Query)拿着一个“科幻小说”的主题清单,去比对图书馆里成千上万本书的标签(Key),得出一个巨大的“匹配度”分数表。
权重分配(Softmax):你将这张分数表转化为百分比,告诉你应该投入多少“注意力”到每一本书上。
内容加权(AV):最后,你根据这些百分比,将所有书的内容摘要(Value)融合,得到一份为你量身定制的、关于“科幻小说”的综合信息。
这个流程在理论上无懈可击,但在实际的硬件执行中,却隐藏着一个致命的性能瓶颈。
想象一下GPU的内存结构:它有一小块速度飞快的“片上内存”(SRAM),就像你手边的工作台;也有一大块容量巨大但速度较慢的“全局内存”(DRAM/HBM),如同一个需要长途跋涉才能到达的中央仓库。
传统的注意力计算,就像一个效率极低的工匠。他在工作台(SRAM)上完成第一步,计算出那张巨大的“匹配度”分数表后,并不直接进行下一步。相反,他必须先把这张巨大的、还只是“半成品”的表,辛辛苦苦地运送到遥远的中央仓库(DRAM)存放。接着,为了进行第二步Softmax计算,他又得从仓库把这张表取回来。计算完成后,得到的“注意力权重”表,又是一个半成品,他再次将其送回遥远的仓库。最后,为了完成第三步,他需要同时取回“权重”表和所有书籍的“内容”,才能在工作台上完成最终的融合。
这个过程中,真正的计算(点积、Softmax)或许耗时并不长,但来回搬运这些巨大中间产物(匹配度矩阵和注意力矩阵)的时间,却成了无法忍受的开销。 这就是I/O瓶颈——当序列长度N增加时,这些中间矩阵的大小会以 N 平方 的速度急剧膨胀,频繁的读写操作会让GPU的大部分时间都浪费在等待数据上,而非真正的计算。
FlashAttention的革命:合并工序,一步到位
FlashAttention的作者们洞察到了问题的本质:我们需要的只是最终的结果O,中间过程的矩阵其实根本不必“留档”。
于是,他们进行了一场工作流程的革命。他们没有发明新的工具或公式,而是彻底改造了生产线,将三个独立的工序融合成一个在高速工作台(SRAM)上一气呵成的“超级工序”。
这场革命的核心武器有两个:分块(Tiling) 与 在线Softmax(Online Softmax)。
1. 分块处理:
FlashAttention不再试图一次性处理所有书籍(整个K和V矩阵)。而是像一位聪明的工匠,把任务分解。他每次只从仓库中取一小批书的标签(K块)和内容(V块)到他的工作台上。
2. 在线Softmax的魔法:
这是整个流程中最精妙的部分。传统的Softmax需要“总览全局”才能计算,这也是为什么它难以被分块的原因。但FlashAttention通过一种巧妙的递推算法,实现了“在线”更新。
想象一下,工匠在处理完第一批书后,会得到一个临时的、局部的结果,并记录下两个关键的“全局统计数据”:到目前为止见过的最高匹配分(m)和当前结果的归一化因子(d')。当第二批书的数据被取到工作台上时,他不需要回头看第一批书的细节。他只需利用新一批书的数据和之前存下的那两个“全局统计数据”,就能计算出一个更新后的、融合了前两批书信息的新结果,并再次更新这两个统计数据。
这个过程不断重复,每一批新的K/V数据块都被加载到高速SRAM中,与Q进行计算,然后用来迭代更新最终的输出O以及那几个关键的统计量。自始至终,那张庞大的、完整的注意力分数矩阵从未在任何地方被完整地构建出来。 它就像一个在计算过程中短暂存在的“幽灵”,用完即逝,从而彻底消除了对慢速全局内存的读写瓶颈。
FlashAttention的成功,给我们带来了远超于算法本身的启示。它证明了,在AI的“摩天大楼”越建越高的今天,地基:计算机体系结构,它的重要性从未改变。
它的巧妙之处,不在于发明了更复杂的数学公式来拟合数据,而在于深刻理解了硬件的工作原理,并用最经典、最基础的计算优化思想:减少内存访问,去解决一个看似前沿的AI问题。
一个为 Attention 计算带来极大加速的技术,其内核只不过是一场计算机体系结构的大师级实践课。它证明了,最深刻的优化往往不是发明新事物,而是熟练掌握最基本原则,并应用于新的硬件之上。
山川地貌会变,但万有引力定律亘古不变。
对技术细节感兴趣的可以阅读公众号的原文,算法公式比较抽象,我画了很多图来辅助理解,链接在回复中。


中文

@LinearUncle 用 k2 用的代理是哪个呢,我试了 Claude code proxy、router、groq 等,都不大行,生成的工具调用都容易变成 cc 不能理解的、被截断的文本输出。
中文

谁和我一样,喜欢把把「claude code」开到 YOLO 模式?
一条命令,一秒起飞:
claude --dangerously-skip-permissions
人生苦短,代码要快。
You Only Live Once(YOLO),写完再擦汗。
主要最近老搭配使用kimi k2干活,不用YOLO实在太慢了。
不要学我,我知道自己在干什么。
中文

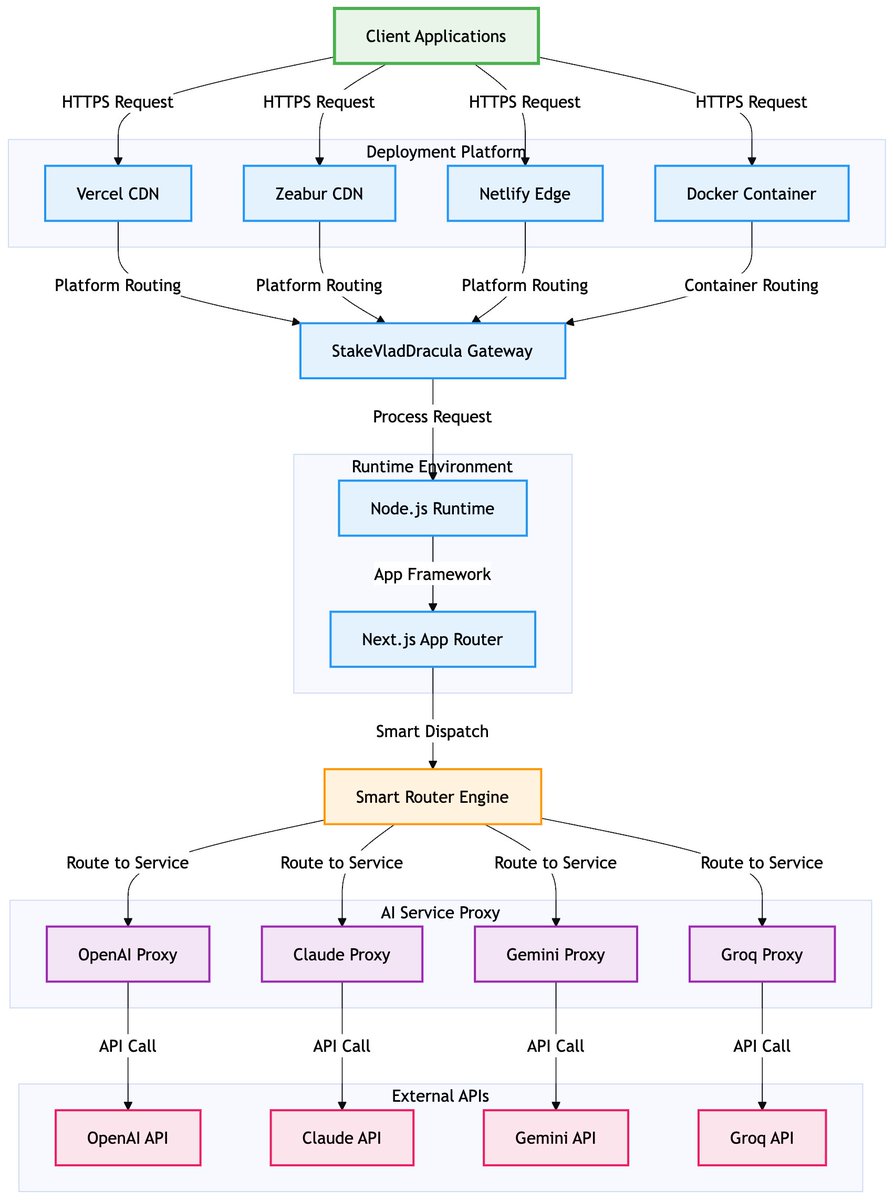
StakeVladDracula 我们的 德古拉 迎来重大升级!
Router v2.0现已发布,全面重构为纯API代理服务,性能和可靠性显著提升。
主要更新如下:
○ 支持主流模型厂商 OpenAI、Claude、Gemini、Groq
○ 支持Vercel、Zeabur、Netlify及Docker部署
○ 提供一致的访问方式,简化集成难度
○ 开发者可轻松在不同模型服务间切换
○ 保留原始API的所有功能特性
Router v2.0 架构优势
○ 代码量减少65%,执行效率显著优化
○ 移除前端界面,专注于API代理功能
○ 重新设计的架构提供更好的稳定性
新增功能特性
○ v2.0版本新增/v1/responses端点
○ 支持各AI服务的所有主要API端点
○ 保持与之前版本的兼容性
○ 自动添加 StakeVladDracula-Router: v2.0 头部标识
○ 从Node.js Pages Router切换至App Router架构,摒弃Edge Runtime,避免香港节点部署问题
项目地址:
github.com/Herm-Studio/St…
herm-studio.github.io/StakeVladDracu…
中文


DeepWiki 开源版本 - 通过 AI 和自动化简化代码仓库文档生成流程,生成美观、交互式 Wiki 文档,通过分析代码结构、生成文档和可视化图表,帮助开发者快速理解和管理项目 👏🏻
核心功能
· 即时文档生成:输入仓库地址,秒级生成 Wiki
· 私有仓库支持:通过个人访问 token 安全访问私有仓库
· 智能分析:AI 分析代码结构,生成上下文相关的文档
· 美观图表:自动生成 Mermaid 图表,展示代码架构和数据流
· 交互式问答(Ask):基于 RAG 技术的聊天功能,可查询仓库代码
· 深度研究(DeepResearch):多轮研究模式,深入分析复杂问题
· 简单导航:直观的界面,便于浏览 Wiki 内容
注意事项
· 支持 Google Deepmind 和 OpenAI 的模型 API
· 代码仓库方面支持 Github 和 Gitlab

中文

一键式网页内容抓取工具:scrape-it-now,支持自动化和可扩展
可以从复杂的网页结构中提取数据,支持多种格式类型
提供URL和简单的提取规则,scrape-it-now可以自动完成数据抓取,并保存到指定文件中
github:github.com/clemlesne/scra…
#数据抓取
中文

@DeasonGood Sorry, was just on a break and didn't reply in time. Checking private messages now.
English
Vote for us, get 1 month GPT4o and Claude 3.5 for FREE! 🎁
We officially release Felo.ai today, need your help!
How to claim:
Upvote Felo on Product Hunt
DM your upvote screenshot to @FeloSearch
Vote link: producthunt.com/posts/felo
#Felo #BuildInPublic
English