
Diede Apers
417 posts

Diede Apers
@DiedeApers
Rendering Engineer @ Frostbite Stockholm
Stockholm, Sweden Katılım Aralık 2010
879 Takip Edilen893 Takipçiler

So by manually poking around I've found that disabling texture read (needed for discard alpha testing) in shadow passes makes them about 50-75% faster. Making all draw calls read the same texcoord also works, though the gains are smaller. Am I actually texture bandwidth bound? 😭

English
@SebAaltonen My guess here is that PC memory models have/had several security vulnerabilities which remain a risk. Fixing up the descriptors with gpuva in the driver allows for security patches without breaking your code on devices that are vulnerable.
Apple owns their full stack, big win!
English

It's silly that you put need to put a buffer descriptor in your descriptor heap and RS1.1 then allows driver to optimize your descriptor to be a 64-bit pointer instead (no bounds check). Why can't I just directly use the 64-bit pointer instead of leaning on driver magic?
English
Investigating CUDA memory allocation system my blog post today.
cudaMalloc returns a GPU pointer. No CPU access. cudaMemcpy CPU->GPU.
cudaHostAlloc returns a CPU pointer. Full CPU access. cudaHostGetDevicePointer converts it to GPU pointer.
But there's no PCIe ReBAR heap...
English
@NOTimothyLottes Yes please.. our “slow path” for these is 8x bilinear lookups with software interpolation, even more int ALU if irrad and depth and different resolutions. I do think that 2 pipelined octahetral samples would allow for better he utilization.
English

I'm curious, should GPUs have octahedral acceleration of some kind? Would it help, ie are people ALU bound with passes octahedral sampling? Re-the GI fast path in Doom: advances.realtimerendering.com/s2025/content/…

English
Diede Apers retweetledi

Alan Wolfe, William Donnelly, and Henrik Halén,
Importance-Sampled Filter-Adapted Spatio-Temporal Sampling
jcgt.org/published/0014…

Deutsch

DirectX Raytracing 1.2, PIX, Neural Rendering announcement at GDC 2025 devblogs.microsoft.com/directx/announ…
English
@SebAaltonen It’s not always feasible to provide motions vectors; transparents, layered materials, arbitrary vertex animation, etc.
I’m not sure if optical flow can do a better job, but misinforming the reprojection is likely even worse..
English
It's sad that nowadays developers trust ML to figure out their motion vectors instead of providing them for all cases. We could solve this better.
A good thread:
NOTimothyLottes@NOTimothyLottes
Modern scaling-TAAs are being asked by increasingly dependent devs to do more and more bad-motion-vector reconstruction (1.) Motion mis-match between transparency over opaque (2.) Scrolling textures (3.) NPCs without rendered motion vectors etc ...
English
@s4schoener I am this close to doing what you described in this post, thanks for sharing!
VCPKG is certainly an example of eventually favoring control over results.
So when will swamp generate cmake files? Partly joking, but once you want to publish code again cmake is unavoidable..
English

How and why I wrote a build system, even though everyone tells you not to.
blog.s-schoener.com/2025-01-29-bui…
English
@mxacop @max_tarpini No malloc on gpu side available, unfortunately! Usually we alloc one buffer from which we suballocate using atomics in a shader. If you ever do run out of space, you have to early out. You could raise a warning by reading the counter back to CPU and decide to bump it statically.
English

@DiedeApers @max_tarpini And, if I'm pre-allocating a range of indices for each cell, I might as well just be storing that range inside the cell directly. I'm sure there's a way to do it dynamically, but I haven't found any resources on how to achieve this yet. Nor have I figured it out myself :p
English
This week I've been implementing Surfels for the first time, the most challenging part so far has been the spawning algorithm. Stopping Surfels from spawning on top of each other. The spatial look-up acceleration structure is also a part which I still need to iterate on :)


English
@mxacop @max_tarpini Re list storage: we store an offset and count per cell to a linear list of indices. Max allocation is determined by an avg cell count estimate multiplied by the number of cells.
We have a max of 2^18 surfels and 1024 entries per cell.
English
@mxacop @max_tarpini Right, the grid scale in worldspace will determine a lower bound to surfel radius, as well as an upper-bound in our case, actually.
Lower bound keeps the cell occupancy and screen-coverage in check, while and upper bound keeps the binning overlap in check.
English
@mxacop @max_tarpini What makes the resolution insufficient in your case? In fb we have 64^3 resolution and a maximum of 1024 entries per cell (ideally this doesn’t even come close, something like 64 unique entries is plenty, and maybe up to 256 references).
English
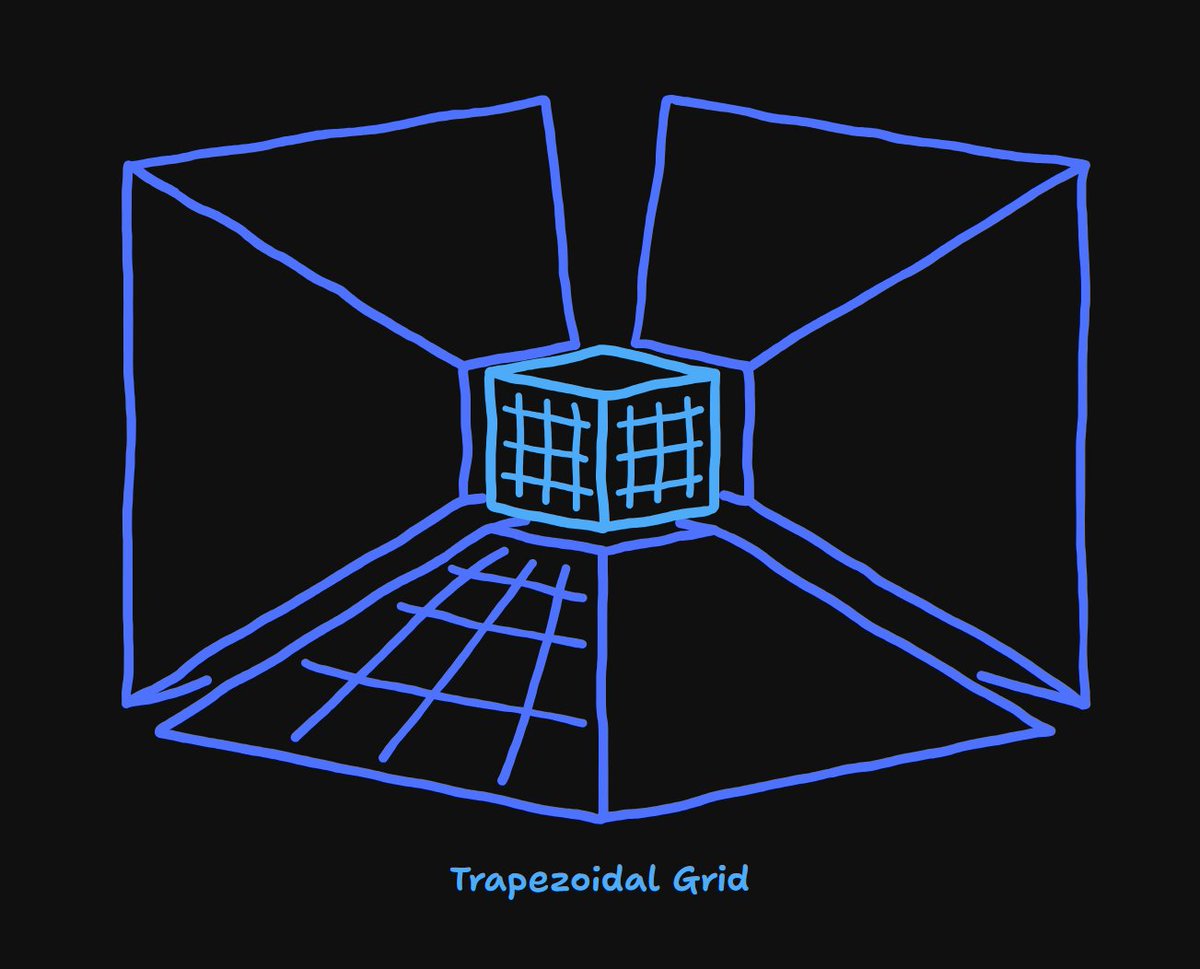
@max_tarpini At the moment I'm using a uniform grid, which could be expanded with trapezoidal grids on each principle axis.
But the resolution close to the camera on the uniform grid is just insufficient, and increasing the resolution costs too much memory.
So, I'm looking for alternatives :)
English
@SebAaltonen The RT improvements are the same between rdna4 and the ps5 pro afaik. The biggest differences are wider bvh 4->8 nodes, and hardware instructions for stack management. No sorting involved in the hardware.
English
Wondering what kind of improvements RDNA4 has in addition to more ray-test/BVH units.
Do they have similar tech as Nvidia Shader Execution Reordering (SER) or Intel Thread Sorting Unit (TSU)? Those technologies help with thread divergence in ray-tracing.
Hassan Mujtaba@hms1193
AMD Radeon RX 8800 XT “RDNA 4” GPU Allegedly Offers 45% Faster RT Performance Than 7900 XTX, On-Par With RTX 4080 In Raster & Lower Power Too wccftech.com/amd-radeon-rx-… wccftech.com/amd-radeon-rx-…
English
@SebAaltonen In case you have an issue unique to the web build, what tools are available? Can you attach a debugger for wasm? Do Renderdoc captures work?
English
This is why I developed WebGPU using Dawn native library. This way I could develop using native Mac / Windows application using good debugging tools and much faster iteration time (WASM linking is slow). Also I could use Xcode GPU debugger and RenderDoc and IHV profilers.
English
I am ready to push WebGPU to production, but seems that our existing web build ran into crash issues 10 days ago. Web debugger hangs (no output) when this bug triggers, so it's very hard to debug.
Tooling is still issue in web. Native debuggers and profilers are much better.
English
@SebAaltonen Most things that surprise my about WebGPU end up being required for security/sandboxing/preventing UB.
But in this case.. what is the compiler frontend able to prevent that would not be caught by the IR->backend? Surely this has a good reason?
English
WebGPU day 18:
Today I will be integrating the Tint shader translator (SPIRV-WGSL) to our shader compilation pipeline. Web browser API requires textual WGSL shaders. SPIRV is not supported.
I have already stated why I hate shipping textual shaders so I don't repeat it today...
English
@SebAaltonen Would this not shift your variable cost from light evaluation into variable cost of SDF generation? I suppose update frequencies are different though.
English
Would be nice to have (almost) infinite amount of shadow casting lights with (almost) fixed budget.
UGC = lots of objects. Kitbashed content. Users don't care if they kitbash objects with light sources (or skinned anim). Have to prepare for massive light counts on 99€ phone.
English
Stochastic lights with ray-traced shadows has a nice properly that you only need one shadow ray per pixel independently of your light count. This is true for all RT techniques: screen space, SDF and RTX.
I guess we need a SDF scene representation...
Jarkko Lempiäinen@JarkkoPFC
Added screen-space shadows to test how well shadows work with my stochastic light sampling proto. Just a hack for the proto and our plan is to use shadow maps. Every light is casting shadows.
English
WebGPU day 12:
3d rendering liftoff! Seems almost there!
Issues: Lighting seems off. Crashes in some editor features. Swap chain scaling doesn't work. Needs at least one day of tuning to fix them all.




English
Diede Apers retweetledi

Our Dragon Age: The Veilguard coverage begins with the PC tech review. This is by some measure the best triple-A PC multi-platform release we've seen in a long, long time. @Dachsjaeger has good news for you here: youtu.be/OjawnIC81nE

YouTube
English
@OskSta @RevaeRavus Right, a baseless right pyramid with 4 faces, this actually fits the hemi-octahedral: en.m.wikipedia.org/wiki/Hemi-octa… — wonder if I should rename this in my code now, haha
English

@DiedeApers @RevaeRavus Yeah but it's about the distribution of baked projections. So a hemispherical octahedral system is distributing the projections on the top half of an octahedron, ie a pyramid
English
Made some octagonal impostors for these trees. Might seem like overkill for such a stylized look, but they're a lot more stable when rotating the camera than all other billboard solutions I've tried, which is kinda important.
GIF
English
@OskSta @RevaeRavus Not sure about that as a 3d solid, but your 2d projection is definitely a (rotated) quad
English
@OskSta @RevaeRavus Octahedral means 8 faces, since you only need to consider 4 faces for the upper hemisphere, I guess quadrahedral?
English