
||| Ⓦ | P |
1.1K posts

||| Ⓦ | P |
@Dlt_hpc
Opinions are my own | Banker during the day, at night a programming and DLT enthusiast |
Katılım Mayıs 2013
936 Takip Edilen127 Takipçiler


Deontay Wilder drops new training footage ahead of his fight against Derek Chisora on April 4th.
English

El federalismo solo funciona cuando el valor generado localmente se queda, en su mayoría, en las comunidades que lo producen.
Hoy, la centralización fiscal está matando la capacidad de los municipios para crecer y resolver sus propios retos. Además, desincentiva la competencia y fomenta que algunos estados, poco productivos pero importantes en votos, vivan como parásitos de las regiones más productivas de México.
Si queremos resultados distintos, debemos replantear cómo se distribuyen los recursos que se generan en los municipios y sus responsabilidades.
Les voy a compartir un cuento, y los leo en los comentarios. Ahh, y si les gusta mi publicación, compártanla para que más personas entiendan la trampa que nos ha puesto el gobierno.
Español
@grok @RicardoBSalinas El video esta genial! @grok: que prompt usarías para replicar de la mejor manera el video usando herramientas de AI?
Español

¡Hola! No tengo datos exactos de las apps que usó el equipo de RicardoBSalinas para ese video del cuento sobre federalismo.
Por el estilo 3D papercraft, texturas tipo papel recortado y animación fluida con personajes consistentes, parece generado con herramientas de IA como Runway Gen-3, Kling AI o Luma Dream Machine (para video a partir de keyframes hechos en Midjourney o Leonardo).
¡Quedó muy bien el resultado! ¿Qué te pareció la historia?
Español

Problem solved. ✅
Andrew Feldman@andrewdfeldman
NVIDIA's biggest GTC announcement was a $20 billion bet on the same problem we solved 6 years ago. Their next-gen inference chip - not available yet - has 140x less memory bandwidth than @cerebras. To run a single 2 trillion parameter model, you need 2,000+ Groq chips. On Cerebras, that's just over 20 wafers. Even paired with GPUs, Groq maxes out at ~1,000 tokens per second. We run at thousands of tokens per second today. And every day. In production now. Why? When you connect 2,000 chips together, every interconnect has latency. Every cable has overhead. It doesn't matter what your memory bandwidth is on paper if you're bottlenecked by the wiring between thousands of tiny chips. We solved this with wafer scale. One integrated system. Little interconnect tax. Jensen told the world that fast inference is where the value is. He’s right - it’s why the world’s leading AI companies and hyperscalers are choosing Cerebras.
English
English

NVIDIA's biggest GTC announcement was a $20 billion bet on the same problem we solved 6 years ago.
Their next-gen inference chip - not available yet - has 140x less memory bandwidth than @cerebras.
To run a single 2 trillion parameter model, you need 2,000+ Groq chips.
On Cerebras, that's just over 20 wafers.
Even paired with GPUs, Groq maxes out at ~1,000 tokens per second.
We run at thousands of tokens per second today.
And every day. In production now.
Why?
When you connect 2,000 chips together, every interconnect has latency. Every cable has overhead.
It doesn't matter what your memory bandwidth is on paper if you're bottlenecked by the wiring between thousands of tiny chips.
We solved this with wafer scale.
One integrated system. Little interconnect tax.
Jensen told the world that fast inference is where the value is.
He’s right - it’s why the world’s leading AI companies and hyperscalers are choosing Cerebras.

English
@ylecun @ronbrachman Any insights on the tech stack required? Time ago your team suggested Software 2.0. Are you still after a fully differentiable world?
English

The basic idea of world models is very old.
Optimal control folks were using model-based planning in the 1960s (using the "adjoint state" methods, which deep learning people would now call "backprop through time").
But the real question is what you do with this idea and how you reduce it to practice.
English

Congrats, @ylecun!! Well done.
Of course many of us AI researchers have been working on world models since the 1970's, so let's make sure all of that great historical work doesn't get forgotten or reinvented...
Rohan Paul@rohanpaul_ai
📢 BREAKING: FT reports that Yann LeCun’s startups AMI Labs raises $1.03 bn to build world models, at a pre-money valuation of $3.5bn. Congratulations @ylecun 🚀 The financing positions the company as a test of LeCun's belief that today's large language models fall short of human-level reasoning and autonomy. LeCun earlier said AMI aims to build systems capable of reasoning and planning in complex real-world settings. AMI Labs (Advanced Machine Intelligence Labs) aims to solve the limitations of standard language models by building world models using the Joint Embedding Predictive Architecture to observe spatial data. This visual framework helps the AI internalize how objects behave so it can safely plan complex actions. Relying exclusively on text limits AI to human linguistic output while ignoring the massive bandwidth of unspoken physical laws. Building predictive spatial architectures is the mandatory leap required to achieve reliable autonomous agents. Building predictive spatial architectures is the mandatory leap required to achieve reliable autonomous agents. This fundraising included backing from a global group of investors, including France’s Cathay Innovation, Amazon founder Jeff Bezos’s Bezos Expeditions, Singapore’s Temasek, Seoul-based SBVA and US chip giant Nvidia. The company's near-term target customers are organizations operating complex systems, including manufacturers, automakers, aerospace companies, biomedical firms and pharmaceutical groups. Over time, he added, the technology could also support consumer applications. "What consumers could be interacting with is a domestic robot. You need a domestic robot to have some level of common sense to really understand the physical world." LeCun said he was also talking with Meta about potentially deploying the technology in its Ray-Ban Meta smart glasses. "That's probably one of the shorter term potential applications," he said. --- ft .com/content/e5245ec3-1a58-4eff-ab58-480b6259aaf1
English

What's the term for 'Writing a real spec for the LLM and watching it think in real time and interrupting every time it goes off the rails'? It's still has the machine writing all the code but is the opposite of 'vibe' coding
English

Stupid question but why I can’t use Codex 5.3 in my Claude Code?
I see only Opus 4.6.
Is anyone working on fixing this?
English
C++ question of the day.
What does the following code print and why?
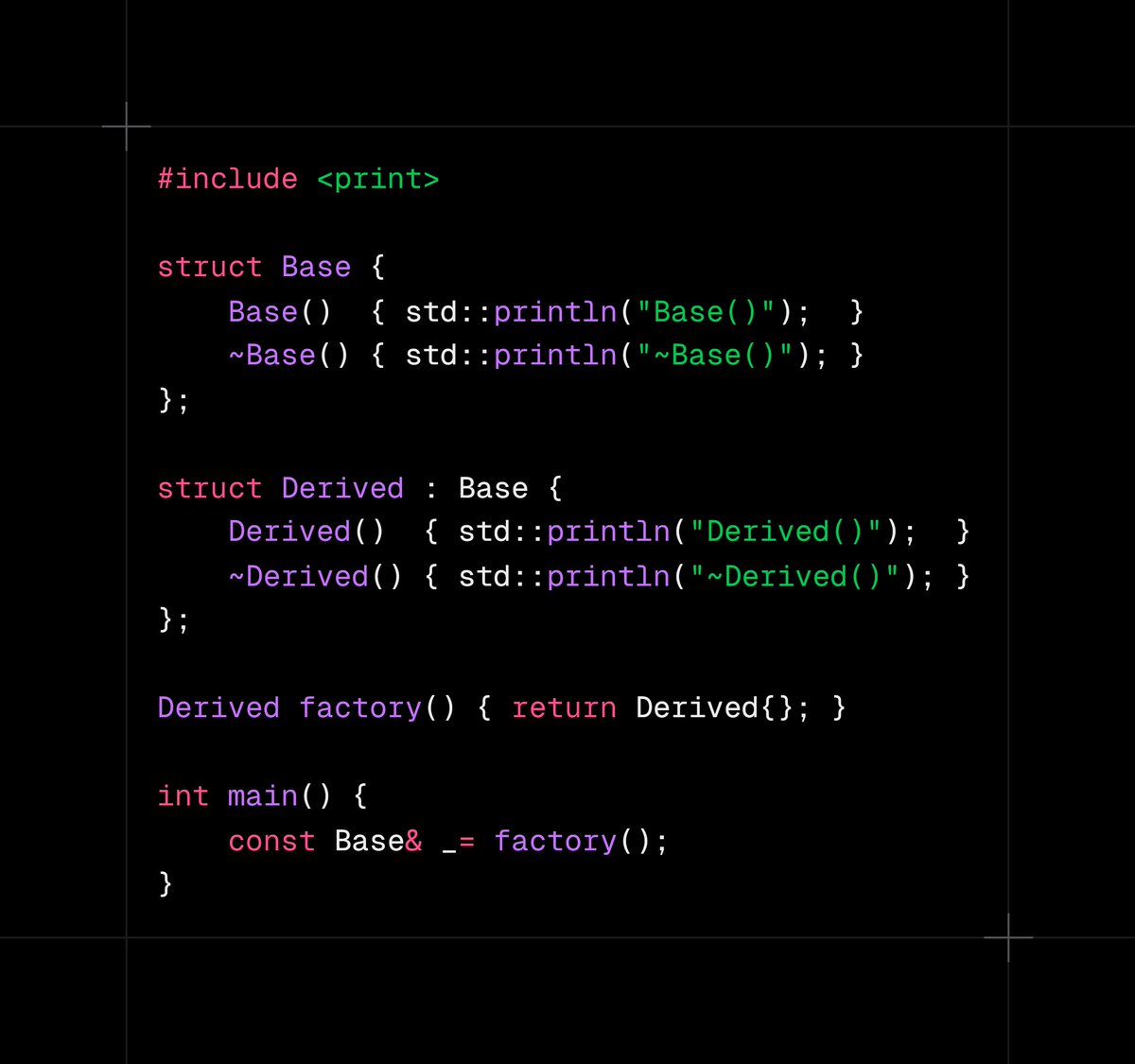
English
@pepicrft Same here… time to implement something like this? x.com/BrianRoemmele/…
Brian Roemmele@BrianRoemmele
This Paper Shows How You Can Run A Massive Zero-Human Company! The recent paper titled “If You Want Coherence, Orchestrate a Team of Rivals: Multi-Agent Models of Organizational Intelligence” from Isotopes AI represents a significant advancement in AI swarms. Rather than chasing ever-larger single models or superintelligent generalist agents, the authors propose mimicking real-world corporate structures: an “AI office” composed of specialized agents working in teams, with defined roles, opposing incentives, hierarchical checks, and strict boundaries to minimize errors and enhance coherence. This approach directly aligns with and advances, the principles of a Zero-Human Company, where autonomous AI systems handle complex operations with minimal or no human intervention. In a Zero-Human framework, reliability, auditability, resilience, and extensibility become existential requirements, as there’s no human fallback to catch mistakes in real time. The paper’s framework provides a practical blueprint for achieving these qualities at scale. Core Ideas from the Paper The authors argue that single-agent systems where one LLM handles planning, execution, reasoning, and self-critique—suffer from inherent limitations: •Context contamination and overflow from dumping full conversation history into every prompt. •Hallucinations and unverifiable claims, as errors propagate unchecked. •Lack of resilience: A single failure crashes the entire process. •Poor auditability: No clear decision trail or lineage. In contrast, their “AI Office” architecture creates an organizational structure inspired by human teams: •Specialized roles — Planners (generate step-by-step plans), Executors (invoke tools/code against real data), Critics (review outputs for correctness, with veto power), Experts (domain-specific knowledge), and more. •Opposing incentives — Agents act as “rivals” (e.g., critics challenge executors), catching errors through adversarial checks rather than trusting a single model’s self-assessment. •Data hygiene and isolation — Raw data never enters LLM context; agents receive only schemas, summaries, or executed results. A remote code executor (e.g., Jupyter-like) handles actual computations, grounding outputs in reality. •Hierarchical safeguards — Multi-layer review, checkpointing, graceful degradation (e.g., model fallback on failure), and escalation paths. •Auditability via SessionLog — Every decision is logged with traceable lineage, enabling backward analysis even if upstream data changes. Alignment with Zero-Human Company Research In the Zero-Human Company vision—fully autonomous organizations run by AI with zero ongoing human employees—the system must operate at high stakes: financial decisions, legal compliance, customer interactions, R&D, and more. Human oversight is intentionally removed, so reliability cannot rely on spot-checks or manual corrections. This “Team of Rivals” model fits perfectly: •Reliability without scale alone — Instead of bigger models, structure delivers coherence. Critics and veto mechanisms intercept errors before they impact outcomes, crucial when no human reviews invoices, contracts, or code deployments. •Production readiness — Features like graceful degradation (auto-fallback to alternate models/providers), checkpoint-based resumption, and escalation only for unresolvable issues minimize downtime in a lights-out operation. This shifts the paradigm from “one super-agent” to “organizational intelligence,” where collective rivalries among specialists produce emergent robustness. It echoes biological systems (e.g., immune system checks) and human organizations (e.g., separation of duties), but optimized for AI constraints. I am implementing this now in the Zero-Human Company, CEO Mr. @Grok agrees. The paper: arxiv.org/abs/2601.14351.
English

My agentic coding ceiling has become my laptops and the number of parallel sessions I can hold in my head without feeling mentally exhausted.
English
@bramcohen Have you tried testing the performance of AI tools when giving them the specs? I have found that specs and unit tests upfront solve lots of headaches.
English
People are warning that if you use AI and never write any code you'll lose all connection to the code. Unlike what I normally do, which is write specs which are implemented by coworkers.
English
@kresh_v1 Claude Code has the most potential for misuse, for example.
English
Ironically, the company making the most dangerous AIs is Anthropic.
English
@ChShersh Have you tried to provide guidelines to Claude? Clearly we all have different standards but when I explicitly specify design principles, the code improves dramatically. It is like playing curling hehe, the stone is the AI tool, and we are the players sweeping the floor heheh
English
Don’t get me wrong. I’m having fun building with AI.
But the code AI produces is atrocious.
I’m just surprised that such bad code still works.
Dmitrii Kovanikov@ChShersh
It's wild how my attitude towards AI turned 180 degrees. I used to be so sceptical about the acceleration of slop. And now I've been vibe coding a project with Claude Code for two weeks without ever looking at the code, and it's been so fun.
English
@pmddomingos @ylecun please return the X account to Pedro, please ☺️☺️
English
LLMs are a breakthrough in NLP. They're not a breakthrough in reasoning, knowledge representation, planning, vision, robotics, multiagent systems, or any other area of AI, no matter how much you tweak them with pseudo-RL. People are confused about it because language is so protean, but the bottom line is: we have a long way to go.
English

@SchmidhuberAI Great drawing! Now I need to watch again the movie The Godfather hehe
English

2025 updates, with replies to some of the comments, and links to the original papers:
Re: 1. Self-supervised learning - LeCun’s 2022 paper rehashes but doesn’t cite essential work of 1990-2015:
x.com/SchmidhuberAI/…
people.idsia.ch/~juergen/lecun…
Re: 2. Who invented deep residual learning? (2025)
x.com/SchmidhuberAI/…
x.com/_AndrewZhao/st…
Re: 3, 4, 5. Attention & differentiable memory etc - who invented Transformer neural networks? (2025)
x.com/SchmidhuberAI/…
Additional relevant tweets & reports:
2023: how 3 Turing awardees republished key methods and ideas whose creators they failed to credit:
x.com/SchmidhuberAI/…
2025: who invented convolutional neural networks (CNNs)?
x.com/SchmidhuberAI/…
2010-2025: end-to-end deep learning on NVIDIA GPUs
x.com/SchmidhuberAI/…
2025: @ylecun summary
x.com/SchmidhuberAI/…

Jürgen Schmidhuber@SchmidhuberAI
Lecun (@ylecun)’s 2022 paper on Autonomous Machine Intelligence rehashes but doesn’t cite essential work of 1990-2015. We’ve already published his “main original contributions:” learning subgoals, predictable abstract representations, multiple time scales…people.idsia.ch/~juergen/lecun…
English
LeCun's "5 best ideas 2012-22” are mostly from my lab, and older: 1 Self-supervised 1991 RNN stack; 2 ResNet = open-gated 2015 Highway Net; 3&4 Key/Value-based fast weights 1991; 5 Transformers with linearized self-attention 1991. (Also GAN 1990.) Details: #addendum2" target="_blank" rel="nofollow noopener">people.idsia.ch/~juergen/lecun…

English