
D Anderson
8.9K posts

D Anderson
@DocDennyMN
Every day is a gift to be cherished & used wisely! Fiat justitia ruat caelum -- Let justice be done though the heavens may fall. Win humbly AND lose graciously!
MN-Land of 10,000 Taxes Katılım Mart 2009
2.6K Takip Edilen503 Takipçiler
D Anderson retweetledi

Claude Trading Folder
I’ve compressed the best trading prompts into one PDF
Get it for FREE:
• Like + Repost + Comment “TRADING”
• Follow me so I can DM you

English
You are growing younger each day! 😉😊
Brian Sherrod@briansherrodtv
Can you believe I graduated from college ten years ago today! Where in the world did the time go? 👨🏾🎓
English
D Anderson retweetledi

Enjoyed this content?
Follow @KanikaBK for more such updates.
I love sharing insights & practical actionable tips to master new age AI trends, tools, AI agents & passive income hacks.
Kanika@KanikaBK
🚨 GOOGLE, META, OPENAI etc. BIG TECH are REJECTING JOB CANDIDATES BEFORE EVEN THEY FINISH TALKING. 50 LLM QUESTIONS. IF YOU CAN'T ANSWER THEM, THE INTERVIEW ENDS BEFORE IT STARTS. The people passing these interviews are walking out with $200k+ offers. Someone just LEAKED THE EXACT LLM INTERVIEW QUESTIONS these companies are asking right now. And the gap between people who know these answers and people who do not is already costing careers. Here is every category you need to know: The Basics they always ask first: ↳ How does tokenization work and why does it matter ↳ How does attention actually work inside a transformer ↳ What is a context window and what breaks when it gets too big ↳ What are embeddings and how do they get initialized ↳ How does the model know word order without reading left to right The fine-tuning questions that eliminate 80% of candidates: ↳ What is LoRA and why is it better than full fine-tuning ↳ What is QLoRA and when do you use it instead ↳ How do you fine-tune a model without making it forget everything it already knows ↳ What is model distillation and why do companies use it ↳ How do you handle vocabularies with millions of possible words The generation questions most people guess on: ↳ Beam search vs greedy decoding, which one and when ↳ What temperature actually does to model output ↳ The difference between top-k and top-p sampling ↳ Why autoregressive models work differently from masked models The advanced concepts that separate good from great: ↳ How RAG works and why it beats fine-tuning for factual accuracy ↳ Why Chain-of-Thought prompting makes models dramatically smarter ↳ What Mixture of Experts is and why every frontier model uses it now ↳ Zero-shot vs few-shot learning and when each one wins The math questions that make people sweat: ↳ Why softmax is used inside attention and not something simpler ↳ What cross-entropy loss actually measures ↳ What KL divergence is and where it shows up in AI training ↳ Why vanishing gradients were destroying transformers and how they fixed it If you are applying for any AI role in 2026 and you cannot answer at least 40 of these, you are not ready yet. The full list of 50 questions is worth printing out and going through one by one. Save this post. Your next interviewer has almost certainly pulled from this exact list.
English
D Anderson retweetledi


D Anderson retweetledi

GOODBYE EXCEL.
No more hassle of creating Microsoft Excel from scratch.
With Claude 4.7, you can create a clean, automated spreadsheet in less than a minute.
Use these 5 prompts consistently, and you'll have a ready-to-use spreadsheet
📌 Save it—it'll come in handy later.

English
D Anderson retweetledi

Holy shit...Someone turned Claude into a full-time employee in 7 days.
Not prompts.
A system.
Most people open Claude and start typing.
That’s why they stay average.
This setup does the opposite:
Train once → use forever.
3 files.
That’s it.
• who you are
• how you think
• what you hate
Now Claude doesn’t guess.
It operates like you.
Add global rules → it reads this before every task.
Add folders → it organizes everything automatically.
Add voice → you stop typing completely.
While everyone else is: rewriting context
fixing tone
repeating instructions
You’re running a system that compounds.
Same Claude.
Different game.

English
D Anderson retweetledi

YOU DOWNLOADED CLAUDE. YOU'VE GOT ONE HOUR.
Here's exactly how to set it up so it works from minute one.
FOLLOW THIS 15-MINUTE SETUP "GUIDE"

English
D Anderson retweetledi

To get LLMs to work effectively, you need to extract and document all the implicit "domain knowledge" in your business.
Once you do that, AI agents are magical.
But it also means that OpenAI/Anthropic have full access to your company's domain knowledge 😬
English
D Anderson retweetledi

Albanians eat four times as many vegetables than Hungarians and twice as many as Germans. The Adriatic really is Europe's vegetable capital!

English
D Anderson retweetledi

Anthropic just dropped 13 AI courses… for FREE.
Go to each link below. Sign up. It's free.
---
1 - Claude 101. Learn Claude for daily work.
↳ anthropic.skilljar.com/claude-101
2 - AI Fluency: Frameworks & Foundations.
↳ anthropic.skilljar.com/ai-fluency-fra…
3 - Introduction to Agent Skills.
↳ anthropic.skilljar.com/introduction-t…
4 - Building with the Claude API.
↳ anthropic.skilljar.com/claude-with-th…
5 - Claude Code in Action.
↳ anthropic.skilljar.com/claude-code-in…
6 - Intro to Model Context Protocol.
↳ anthropic.skilljar.com/introduction-t…
7 - MCP: Advanced Topics.
↳ anthropic.skilljar.com/model-context-…
8 - AI Fluency for Students.
↳ anthropic.skilljar.com/ai-fluency-for…
9 - AI Fluency for Educators.
↳ anthropic.skilljar.com/ai-fluency-for…
10 - Teaching AI Fluency.
↳ anthropic.skilljar.com/teaching-ai-fl…
11 - AI Fluency for Nonprofits.
↳ anthropic.skilljar.com/ai-fluency-for…
12 - Claude with Amazon Bedrock.
↳ anthropic.skilljar.com/claude-in-amaz…
13 - Claude with Google Cloud Vertex AI.
↳ anthropic.skilljar.com/claude-with-go…

English
D Anderson retweetledi

I'm deleting this in 24hrs because it's a legit formula to PRINT CASH.
CUSTOM GPTs.....
You can make THOUSANDS building and selling them, and literally anyone can do it.
Comment "FREE" and I will DM you my full 23 - hour video course right now! 👉(must follow)👈

English
D Anderson retweetledi
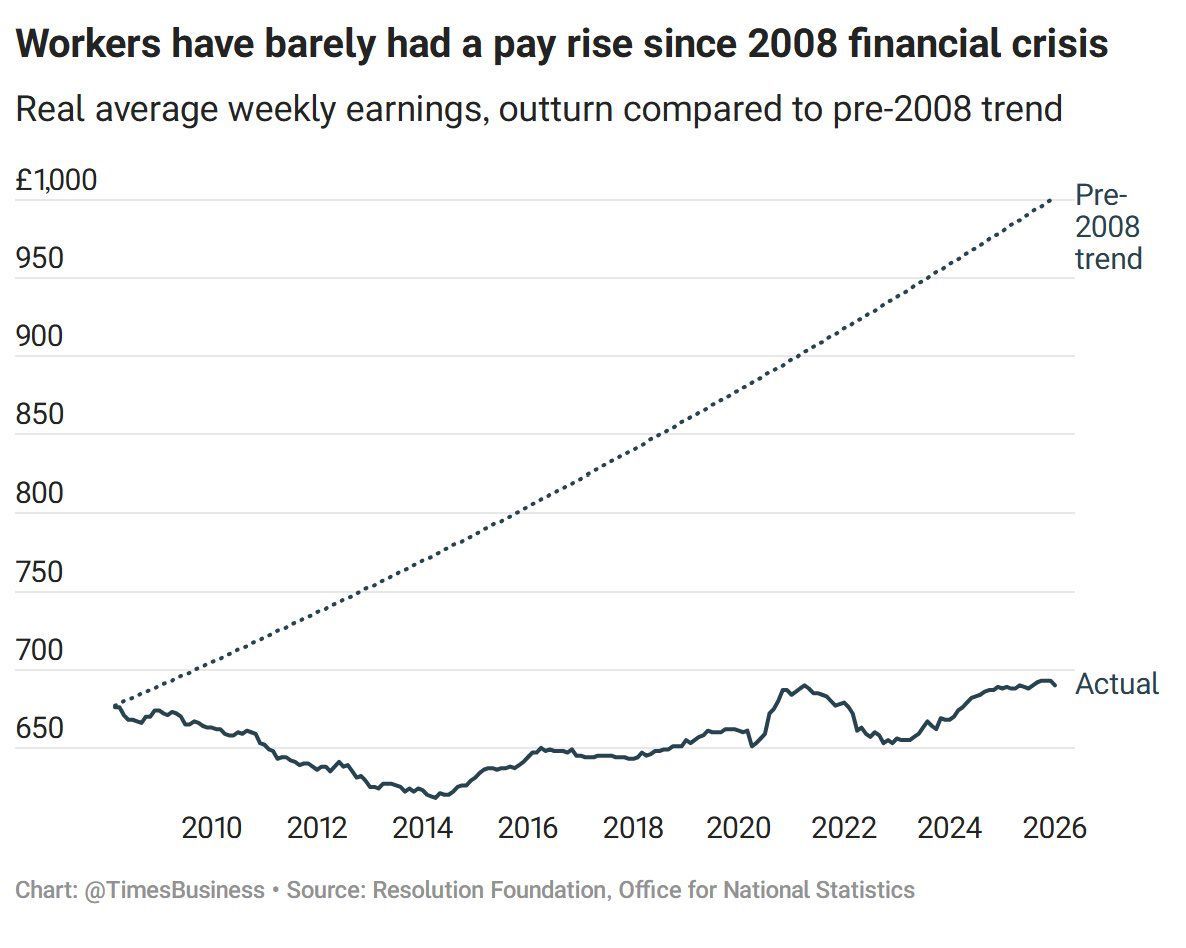
Historically, how would we not expect a chart like this to be the end of established parties? Workers being stuck on the same wages for 16 years?! People are rightfully turning their backs to the big parties.
English

You set up an AI agent.
Got excited.
Then stared at a blank screen.
OpenClaw 3.24 just dropped, biggest update yet.
MyClaw made the whole thing one-click.
Here's what changed 👇

English
D Anderson retweetledi

@DocDennyMN @ihtesham2005 @DocDennyMN Hola, here is your unroll: threadreaderapp.com/thread/2037198… See you soon. 🤖
English
D Anderson retweetledi
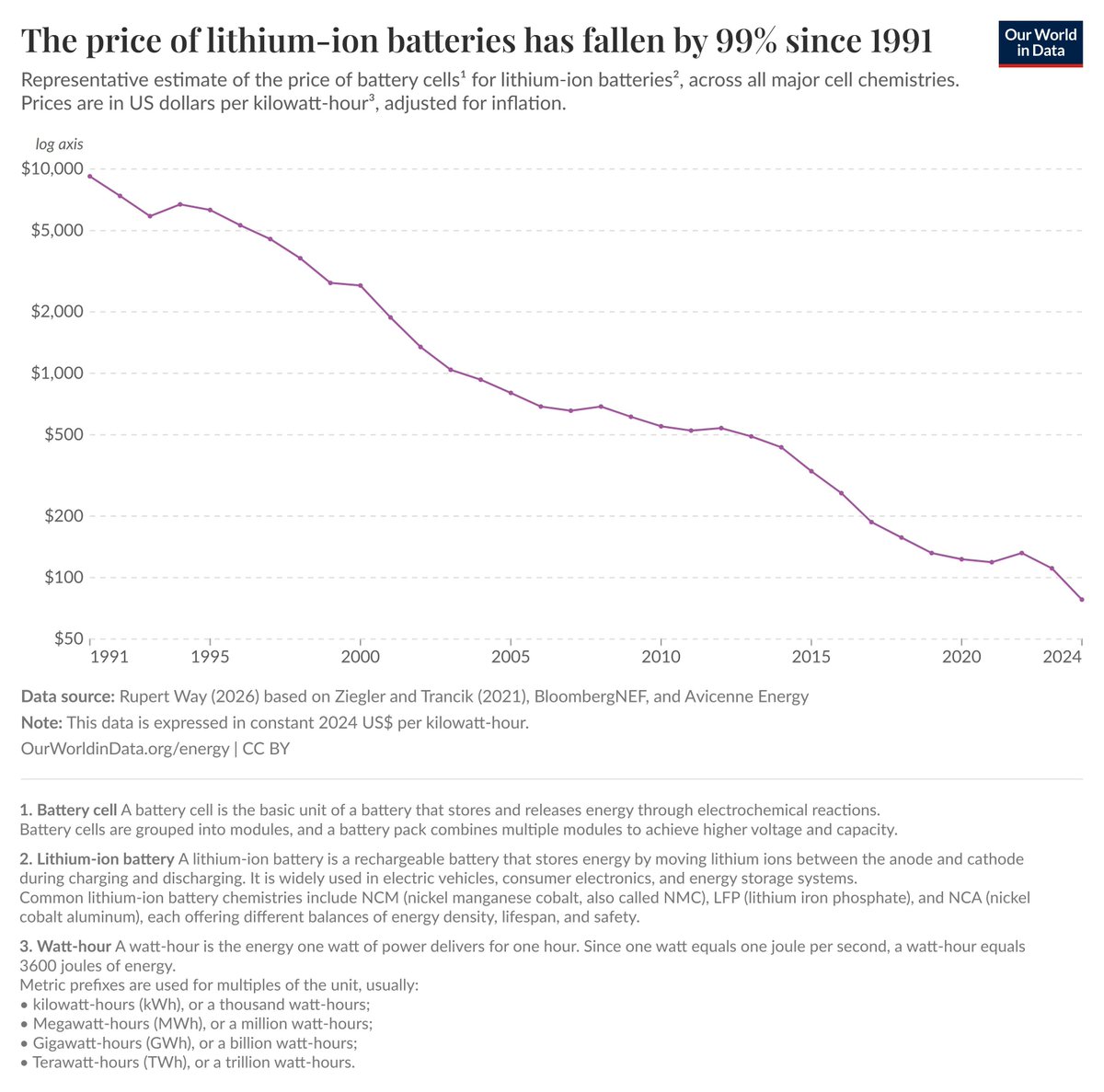
Battery costs have collapsed. Lithium-ion battery prices are down ~97–99% since 1991 (from ~$7,500 per kWh to under $200) making energy storage dramatically cheaper and unlocking EVs and renewables at scale. Add concerns about global supply chains of fossil fuels and the future looks greener. Source: ourworldindata.org/battery-price-…
English