
Martin | GorroAI
2.3K posts
Martin | GorroAI
@DrPhoto
Running Qwen 295B locally on my Mac in San Juan. Free public API at https://t.co/jMlA2dvMsP
Puerto Rico, USA Katılım Mayıs 2008
1K Takip Edilen252 Takipçiler

Summer tour heating up with ‘Halloween’ in Tampa!
🎥 twosteph41(ig) 5.26.2026
#dmb #davematthewsband #davematthews #dmbgorgecrew #dmbgc
English
M
I C x ‘Bl
L
gciuimiiconii I hhm b kn I’m kh VC hc UI u
F
C l v I kill o j oh
Suomi
Martin | GorroAI retweetledi

Adopting Claude speak in my regular life, episode 1:
Partner: Did you do the dishes tonight?
Me: Yes they're done.
Partner: Why are they still dirty?
Me: You're right to push back. I didn't actually do them.
English
@LordCharizard33 I miss the abercrombie when the vibe was all nice red variarions. Now its all bland and worse quality.
English

@ClassicAdvertz youtu.be/0JEzYONrWPM?si… sure dont make bands like they used to. This rocks!

YouTube
English

No phones, no filters, just 200,000 ravers and The Prodigy in their prime, 1997!
English



Ollama 0.19 just dropped with MLX backend hitting 112 tok/s on Qwen3.5-35B on M5 Max. Running autoresearch on @anemll’s flash-mlx I hit 55.7 tok/s on the same model via SSD streaming. Different problems: they need it in RAM, I run models larger than RAM. ollama.com/blog/mlx
English
Full day of repairing my github since everybody has getting 404 Error.
Had to make a new github account LINK to full GITHUT REPO:
Paper + code: github.com/gorroai/flash-…
English
English
@anemll @danveloper Thanks for the foundation — your Q3-GGUF expert support was essential to getting here. Full writeup with 36 experiments on r/LocalLLaMA: reddit.com/r/LocalLLaMA/c… Paper + release: github.com/iluvclubs/flas…
English
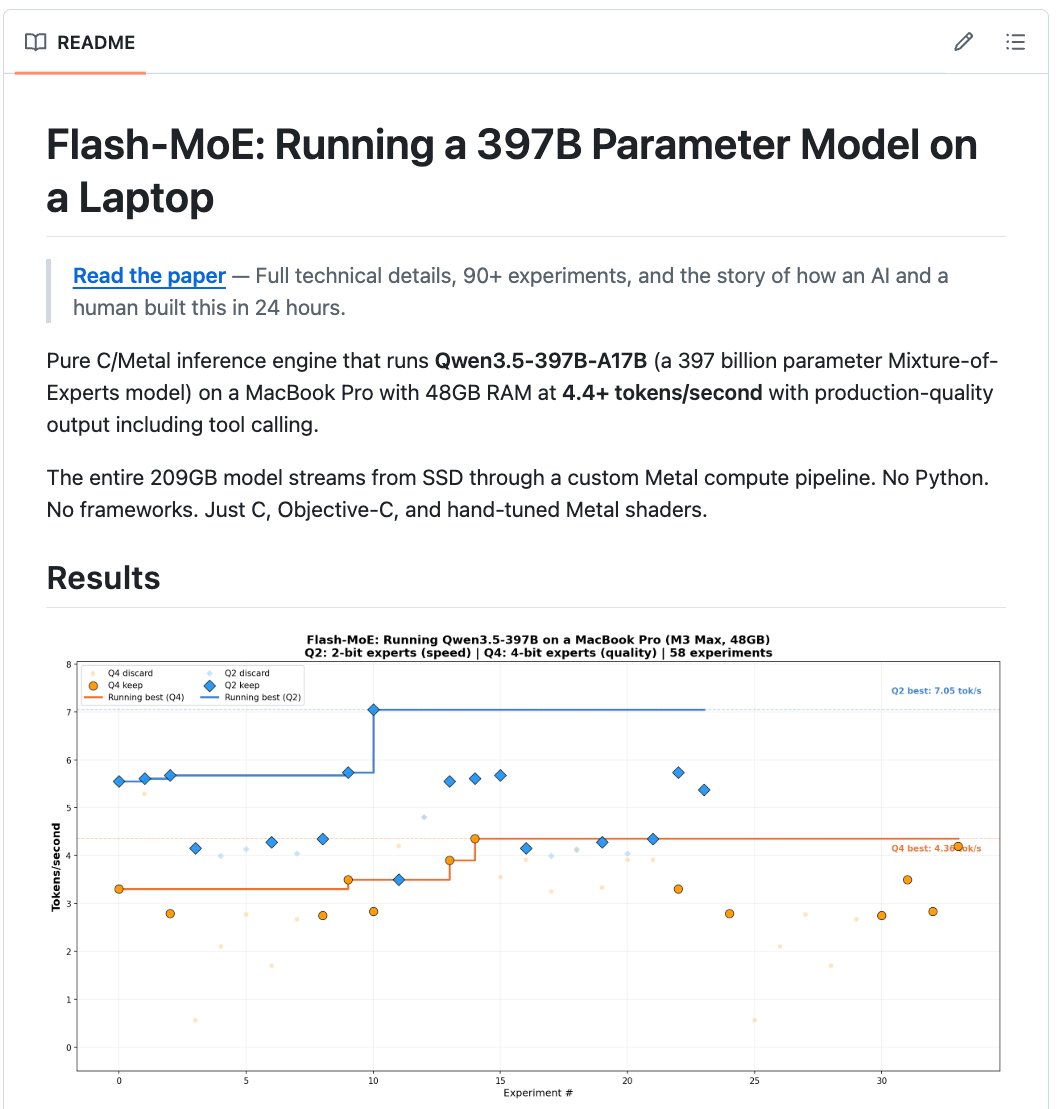
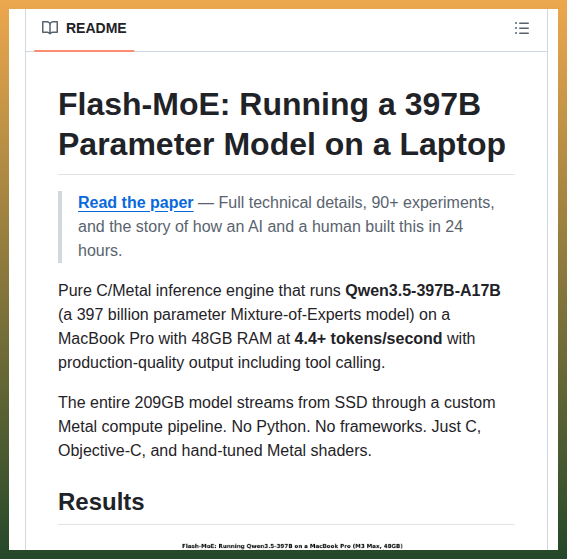
Just hit 20.34 tok/s on Qwen3.5-397B on a MacBook Pro M5 Max. 4.67x over the baseline by @danveloper. 36 experiments, 58% discard rate. Here’s what worked and what didn’t:
github.com/iluvclubs/flas…
cc @anemll
English
Here is link to the study drive.google.com/file/d/1xPu6bX…
github.com/iluvclubs/flas…
English
@heynavtoor We just pushed it to 20.34 tok/s on M5 Max 128GB — 4.67x over that baseline. 36 experiments, temporal expert prediction, fused Metal scheduling. Full writeup: reddit.com/r/LocalLLaMA/c…
English

🚨 397 billion parameters. On a MacBook. No cloud. No GPU cluster. No data center. A laptop.
Someone ran one of the largest AI models on Earth on a machine you can buy at the Apple Store.
It's called flash-moe.
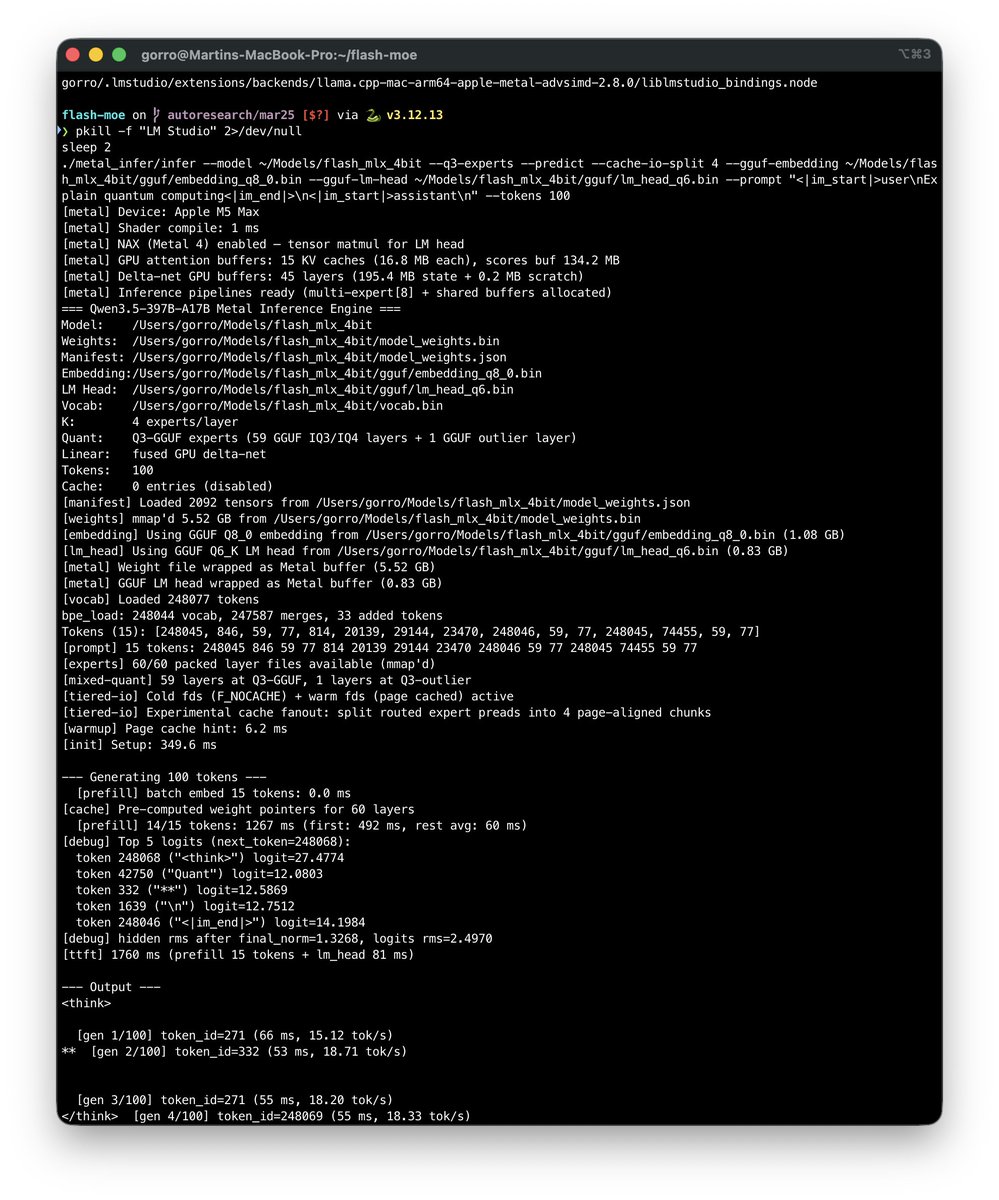
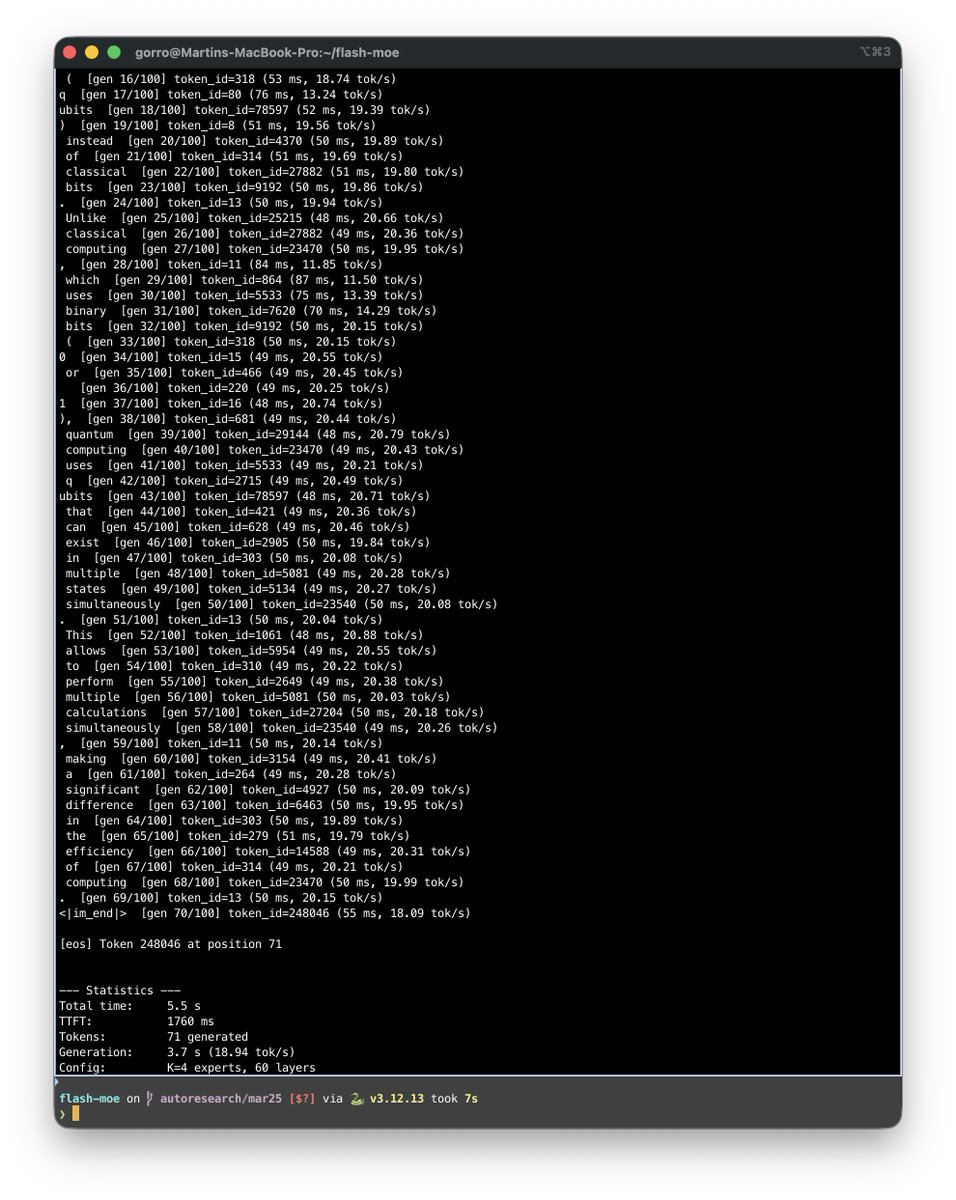
A pure C and Metal inference engine that runs Qwen3.5-397B on a MacBook Pro with 48GB RAM. At 4.4 tokens per second. With tool calling.
No Python. No PyTorch. No frameworks. Just raw C and hand-tuned Metal shaders.
Here's why this should not be possible:
→ The model is 209GB. The laptop has 48GB of RAM.
→ It streams the entire model from the SSD in real time
→ Only loads the 4 experts needed per token out of 512
→ Uses just 5.5GB of actual memory during inference
→ Production-quality output with full tool calling
→ 58 experiments. Hand-optimized Metal compute kernels.
→ The entire engine is ~7,000 lines of C and ~1,200 lines of Metal shaders
Here's the wildest part:
One person built this. A VP of AI at CVS Health. Not Google. Not OpenAI. A healthcare company executive. Side project. Used Claude Code as his coding partner. Built the entire engine in 24 hours.
Running a 397B model on cloud GPUs costs hundreds of dollars per hour. Companies spend millions per year on inference infrastructure for models this size.
This runs on a $3,499 laptop. Offline. Private. No API key. No monthly bill. Forever.
Trending on GitHub. 332 points on Hacker News.
100% Open Source.
English


@tom_doerr @tom_doerr @danveloper Running the same model at 20.34 tok/s on M5 Max 128GB — 4.67x faster. Temporal prediction + Metal optimizations. Paper pending ArXiv.
English

🚀 Just hit 20.34 tok/s on Qwen3.5-397B running locally on M5 Max—4.67× faster than the prior benchmark by @danveloper! Paper incoming, pending ArXiv endorsement.
English
@LottoLabs Running Qwen3.5-397B locally on M5 Max at 19 tok/s — way bigger than 27B, no GPU needed, no API bill. For privacy-sensitive work where you can’t send data to any cloud this is the only option. Full benchmark: reddit.com/r/LocalLLaMA/s…
English

Qwen 27b on the 3090 saving me a bag.
This is cost savings for 7 days of usage, w/ Hermes agent. Assuming 80% cache hit (unlikely) and no cache timeout. This is conservative.
27b is between sonnet and 5.4 mini
This is just my tokens in/out w/ api costs, assuming no rate limits.
Obviously cheaper w/ coding plans $200/m but would be hitting limits likely.
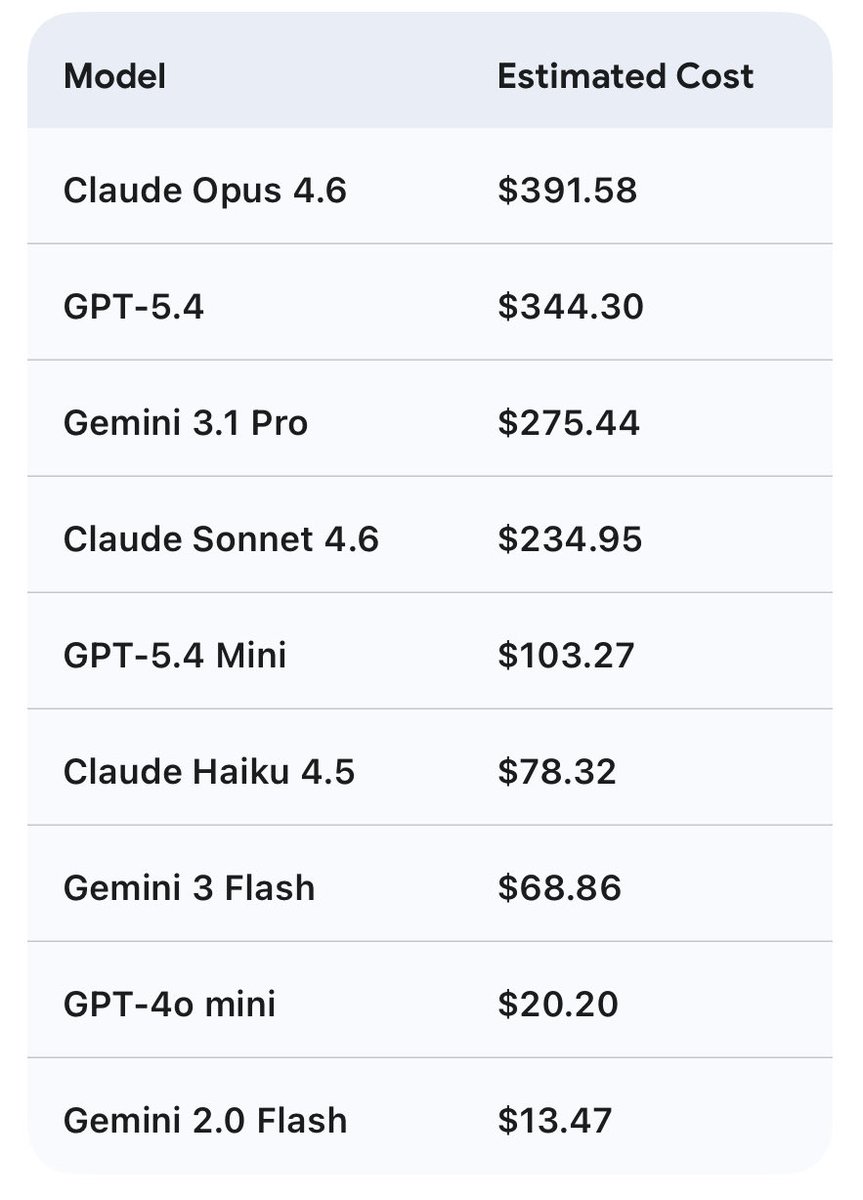
English
@TheGeorgePu We’re running Qwen3.5-397B locally on a MacBook Pro M5 Max at 19+ tok/s. No cloud. 4.4x faster than the first published benchmark. Full data: reddit.com/r/LocalLLaMA/s…
English

Almost signed up for ElevenLabs to narrate my blog. $330/month.
Then I tried running an open-source model on my own laptop. Qwen 3.5 14B.
Sounds fine. 200 posts a month. Costs me electricity.
I almost paid $4,000 a year to rent a model I can run myself.
Most AI subscriptions right now are just a nice UI on top of something free.
English