Sabitlenmiş Tweet
EIFY
7.2K posts

@ml_4rtemi5 Cool! We have experimented with neg. Euclidean distance squared logit for CLIP-like models and gained some insights into them, so you may want to take a look. The next thing I would try is to remove the final LN, possibly w/ residual scaling:
arxiv.org/abs/2409.13079 w/ @nahidalam

English

I dove deeper into the rabbit hole of RBF-Attention. I refined the Triton kernel, added register-tokens and developed SuSiE positional embedding as a replacement for RoPE in Euclidean space.
Go have a look at the repo or the blogpost in the comments if you're interested! :)
Raphael Pisoni@ml_4rtemi5
For some reason I decided to swap out standard dot-product attention for a scaled-rbf kernel. Pretty much expected it to fail to converge or be impossibly slow but the scaled-rbf-attention is getting unexpectedly good results?? 👇
English
@skate_dont @mr_scientism Not every Singaporean. English is the only language every Singaporean student needs to learn at school.
English




@GeorgeN28581 @ZhenjieLing1 @RupprechtDeino It's just strange to refer them as such. It's like saying the US is flying a YF-16 derivative: Technically correct but bizarre.
English

@ZhenjieLing1 @RupprechtDeino Cause they produce them? Latest J-15 and J-16 are ones of the most advanced planes in T-10 lineage
English

Interesting! 😯
Looks at first sight without enlargement like just 3 J-16 far far away and much too blurry 🫣 ... but now I think more like one J-XDS and two CCAs? 🤔

DS北风@WenJian0922
捡来一张图
English
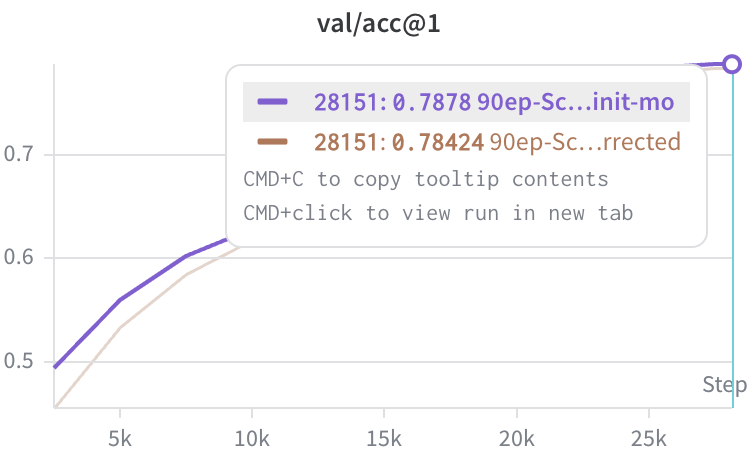
4. These are ScionC experiments, designed to keep the weight norm stable.
(I don't expect 2-4 to change the direction of the result)
5. Without biases somehow the avg. spectral norm is smaller and the L2 grad norm is higher. It's possible that the optimal WD may change...
5/5

English
2. For my ViT-S I made sure that QKV grad. are separately orthogonalized and the input dim. of patchifier are flattened. In the process I already left out the bias of QKV.
3. I incorporated @tmpethick's 1.0 init. mo for the unbiased exp.
4/5
English
I happened to be running this ablation. Preliminary result based on training a ViT-S on ImageNet-1k for 90 epochs says it's better to leave the biases out 🤔
Background: A modified DeiT base has been the CV workhorse for Scion papers... 1/5
x.com/Ji_Ha_Kim/stat…
Ji-Ha@Ji_Ha_Kim
Nowadays biases are omitted in transformers for simplicity/same quality but it might matter more to keep affine layers for more expressivity, since bias doesn't affect Lipschitz
English




English

@9992rc4g7c3939 i can edit it too(look at the button),for me this is chinese clothes and chinese haircut during qing dynasty,look this boy’s haircut

English

Go argue with the University of South California 😌
commons.wikimedia.org/wiki/File:Emac…
노농@sewarago
THAT'S CHINESE🇨🇳🤣 Imagine being so clueless you can't even identify your own history. That's 100% Chinese attire. Stop embarrassing yourselves and learn what your ancestors actually looked like. STUPID CHINESE🤣🤣
English
@LongDesertTrain Would the GI-persistent SARS-CoV-2 eventually establish a fecal–oral transmission route?
English

You have to wonder for how long we will continue seeing infections from 2020 continue to show up (in absurdly high quantities) in wastewater.
1/16
Marc Johnson@SolidEvidence
A new cryptic lineage popped up in St Louis a few weeks ago. I’ve been sampling this sewershed (500k people) twice a week for years and the first time I see this cryptic lineage it is 5 years old and makes up 50% of the sample. 1/
English
@Ji_Ha_Kim @tonysilveti "Huge equal radius" = tiny WD, are you running it until steady-state? Wouldn't that take a long time...?
English

@EIFY @tonysilveti Gemini had an interesting strategy, fixed momentum, first sweeping effective lr with huge equal radius for all, then re-running using the final weight norms as the radii, and it seems to work surprisingly well
English
@Ji_Ha_Kim @tonysilveti Based on the fact that output Sign layer weight & grad don't become ind. I suspect / hypothesize that what's important for the output layer is the steady-state weight norm, not the detailed LR/WD dynamics. I haven't tested this tho...
English


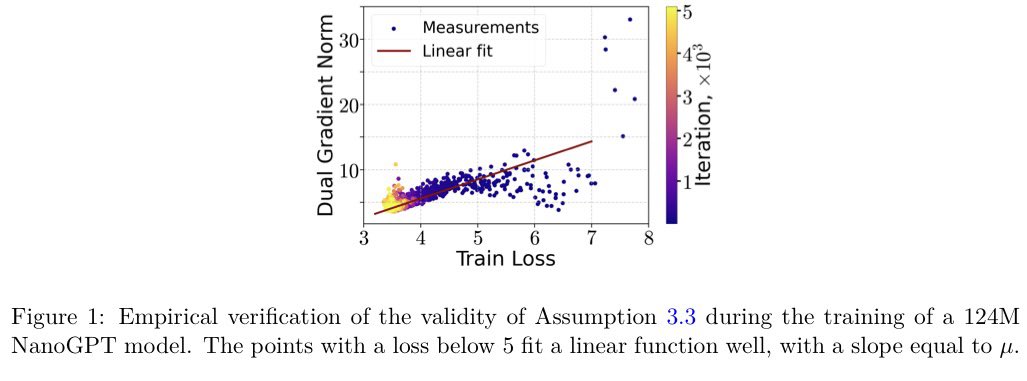
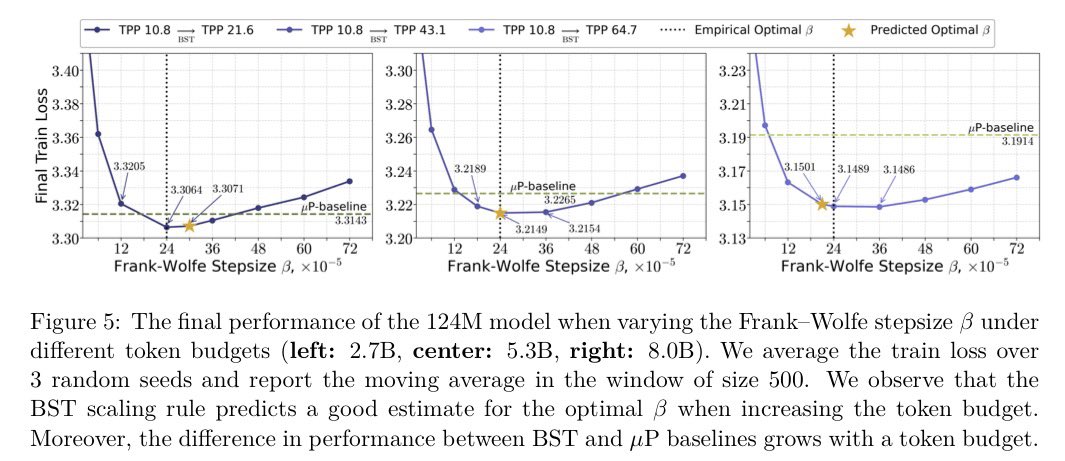
@ruuustem_10 @AurelienLucchi @tonysilveti @ed_gorbunov @CevherLIONS Figure 7 (left) varies the momentum and (right) varies the stepsize, even though its caption says the opposite! Also, LaTeX is broken due to unpaired $ for “Predicted Optimal $\alpha$ or \beta$”
English



English
Excited to share our latest work on bridging theory & practice in optimization 🚀
We study stochastic conditional methods with momentum and provide practical strategies for choosing batch size and Frank–Wolfe stepsizes when token budget increases
Paper: arxiv.org/abs/2603.21191
English