Sabitlenmiş Tweet

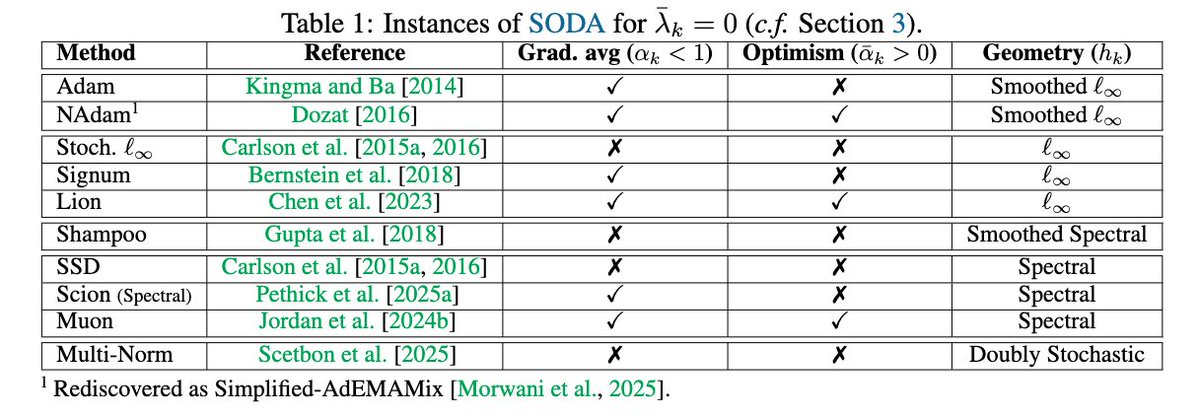
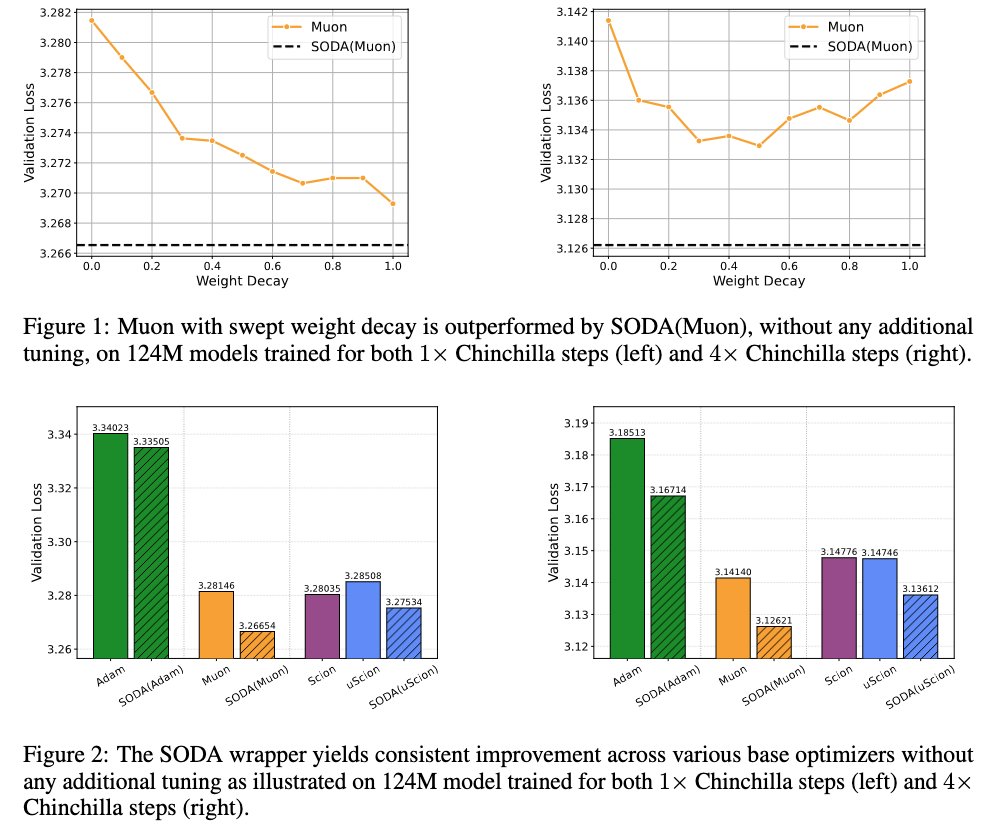
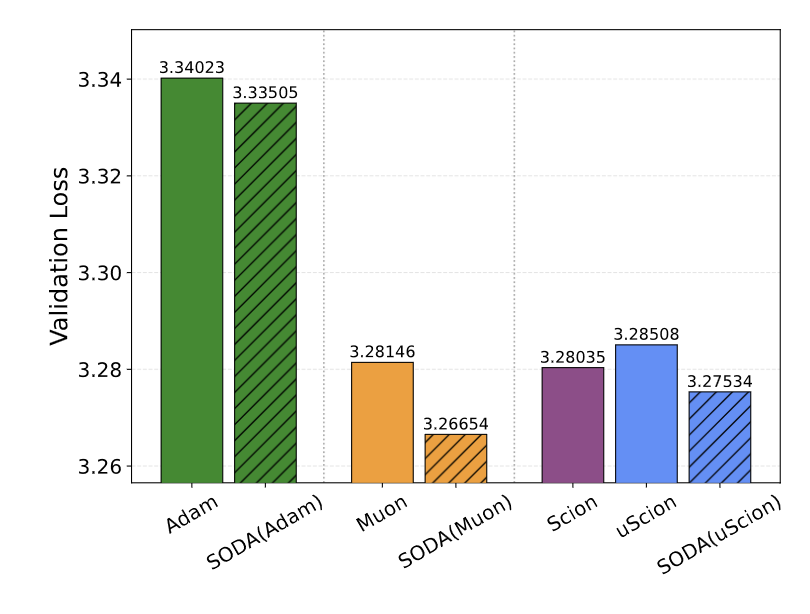
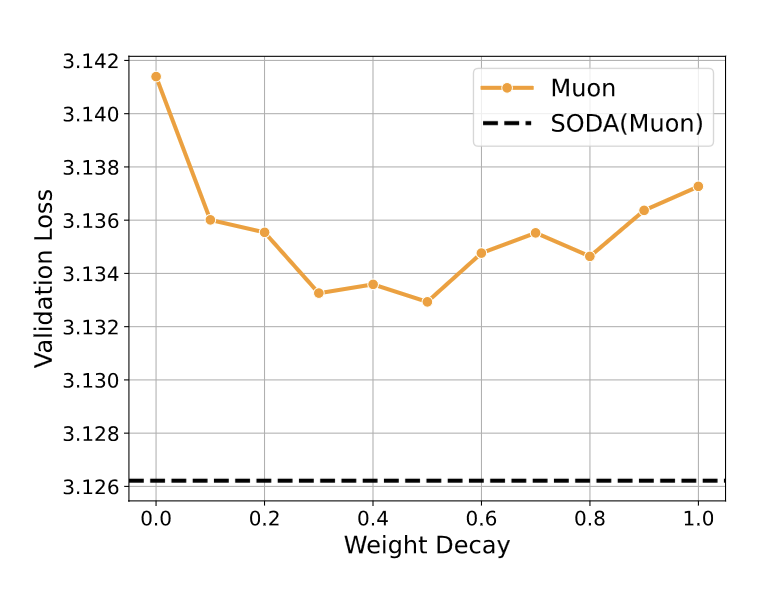
1/ We introduce SODA: a simple optimizer wrapper that improves a base optimizer, adds no hyperparameters, and removes the need to tune weight decay.
The wrapper provides consistent improvement. Most notably, SODA(Muon) beats Muon even when Muon gets a tuned weight decay sweep.
English