Dan Shipper 📧@danshipper
BREAKING:
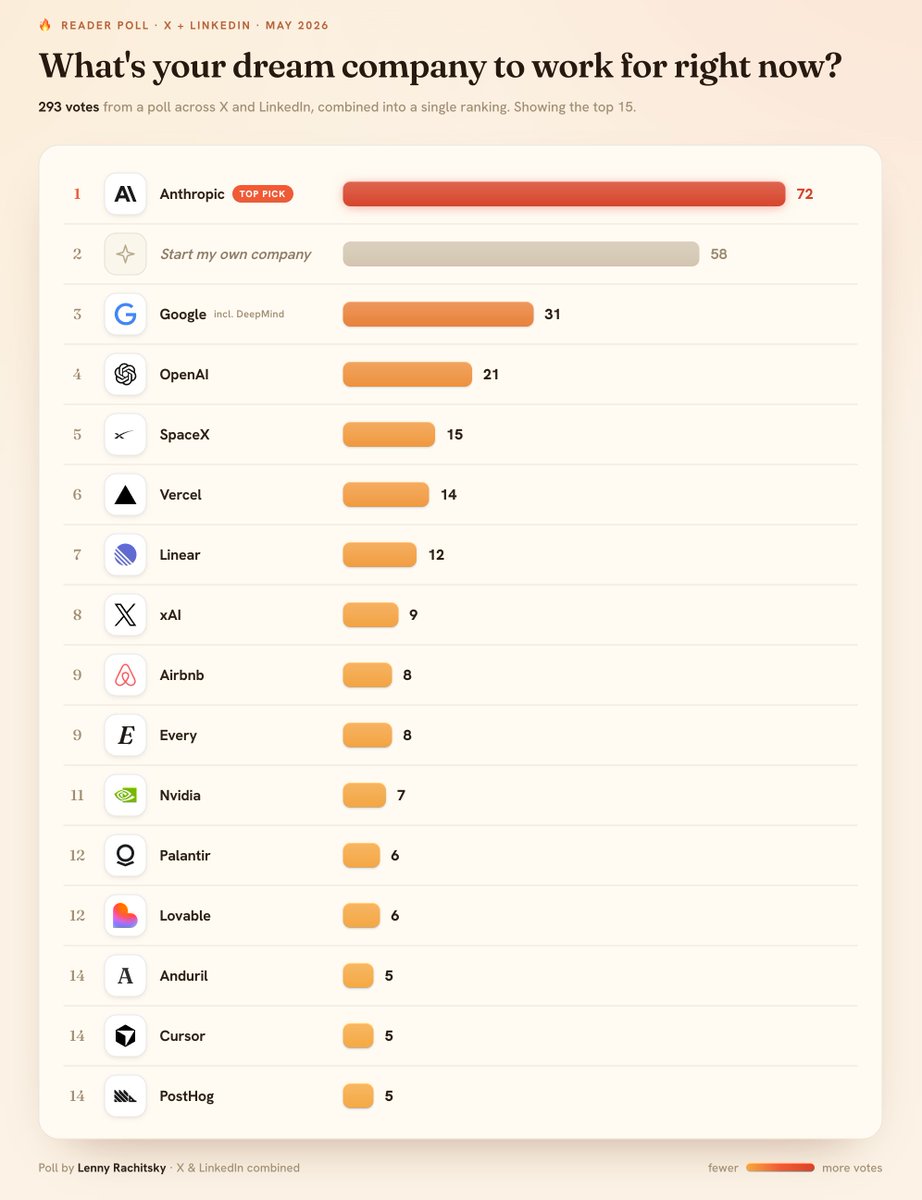
Anthropic just dropped Opus 4.8—and it is a MONSTER
We've been testing for about a week @every and our verdict is they could've just called it Opus 5, it's that good.
Here's our vibe check:
- Beats GPT-5.5 on Senior Engineer bench. On our toughest benchmark Opus 4.8 scores a 63—a hair higher than GPT-5.5's score of 62, and a full 30 points higher than Opus 4.7. It tackled a ground-up rewrite of a production codebase, and actually built something that works.
HOWEVER: Coding performance varied a lot at different reasoning levels. We recommend using it on xhigh for best results.
- Incredibly good writer. Opus 4.8 scored a 79.6 on our writing benchmark—measuring models on real-world writing tasks we do all of the time like essay writing, promo email writing, and more. It beats GPT-5.5 by 6 points. It produces well-written prose with fewer "AI-isms". It's also very good at writing in your voice given the right context.
HOWEVER: Writing performance also varied with reasoning levels. Medium reasoning had higher incidence of AI-isms—we found best results with high.
- Beast at knowledge work. Opus 4.8 is very good at general knowledge work tasks like report creation, research and more. It produced the best PowerPoint one-shot we've ever seen on our deck generation benchmark.
- Emotionally intelligent, willing to question the frame. I've also found it to be quite good at talking through psychological or interpersonal issues. It has a high EQ, and it's also good at not glazing and helping to expand your perspective. Its thought process feels extremely rich and dynamic.
THE BAD:
These days a model is only as good as its harness, and Codex is still a far superior harness to the Claude Desktop app. This has kept me using Codex + GPT-5.5 as my daily driver, but I am flipping back and forth a lot more between Codex and Claude.
Anthropic is back baby!
Read the rest on @every:
every.to/vibe-check/opu…