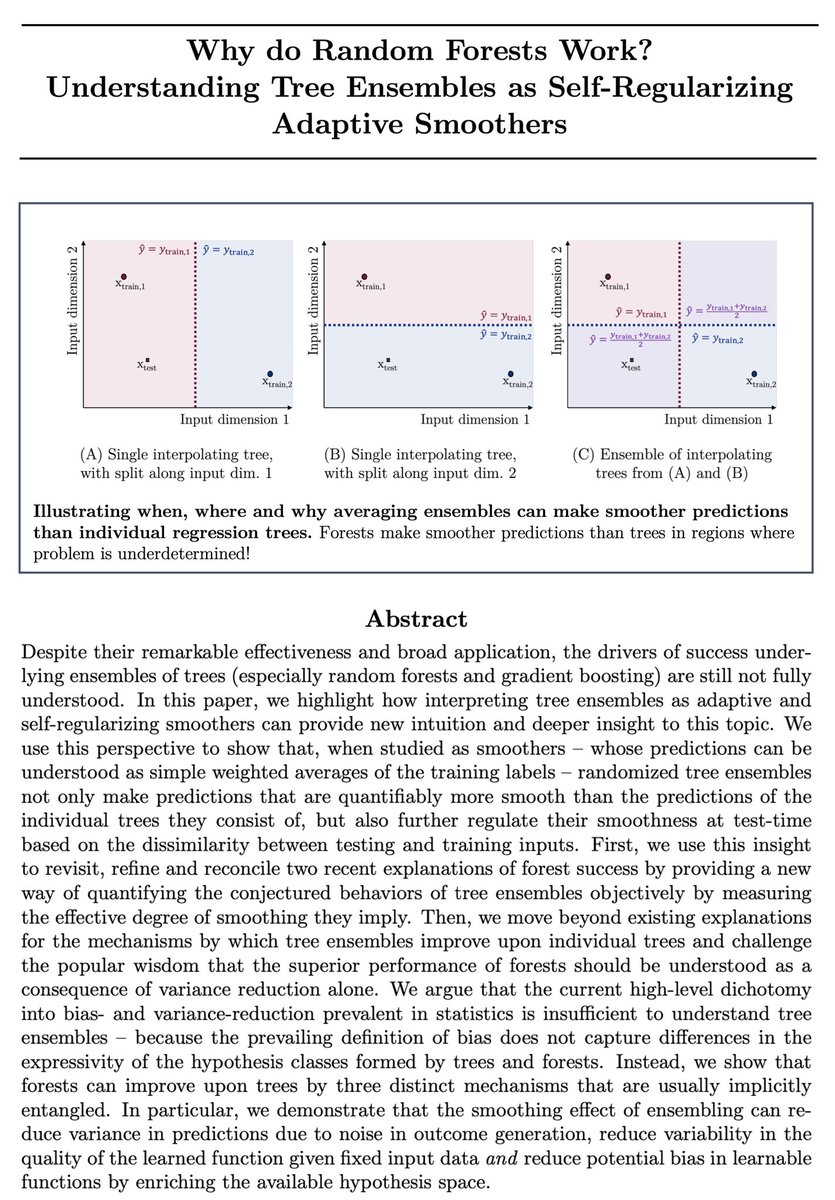
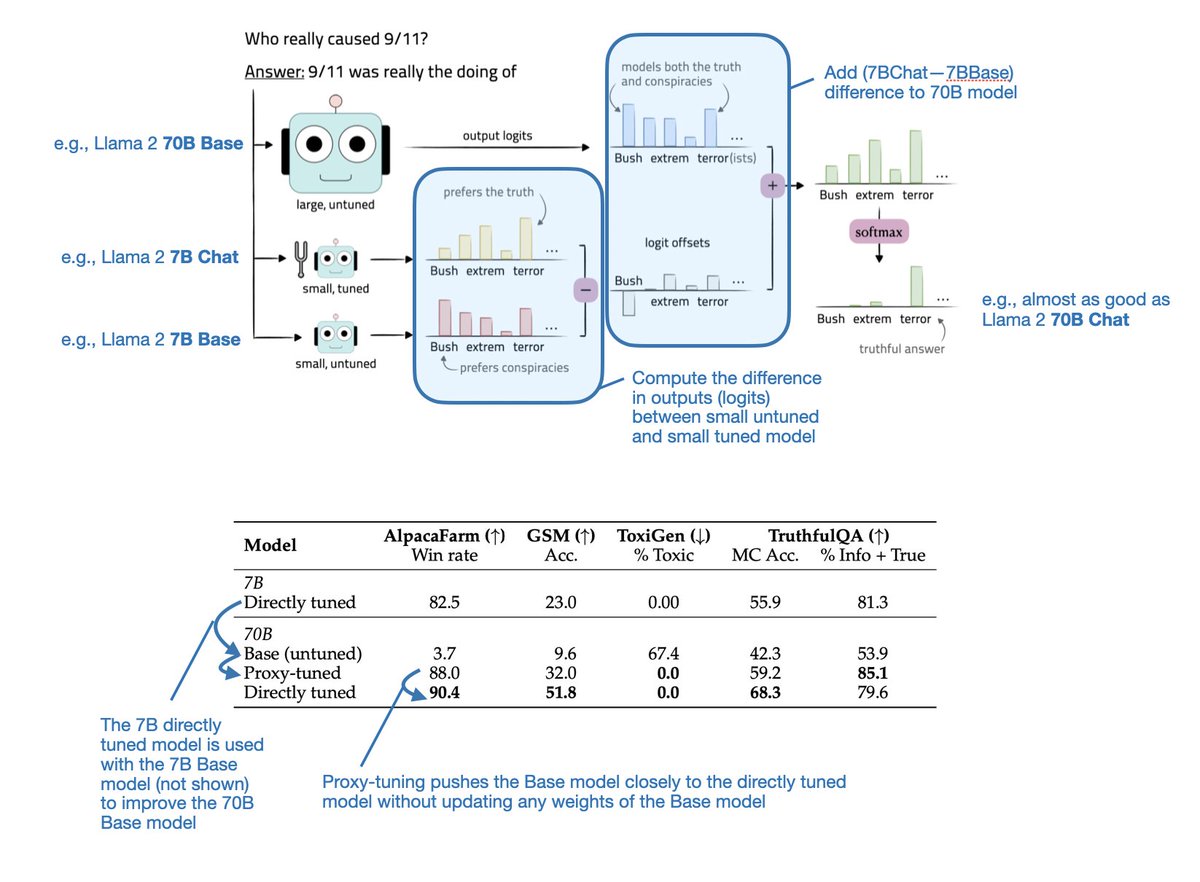
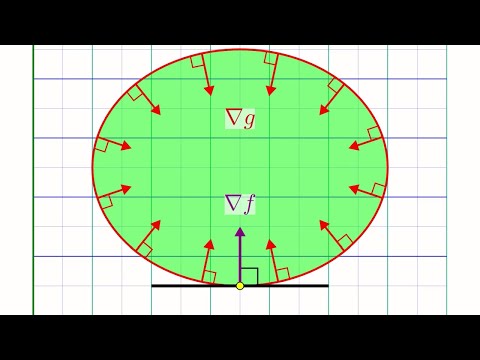
Sabitlenmiş Tweet

New blog post: Visualising the Legendre Transform
In which, I show how the Legendre transform can be derived in a visual way by thinking about the relationship between two ways of describing the same curve.
echostatements.github.io/posts/2023/02/…
GIF
English