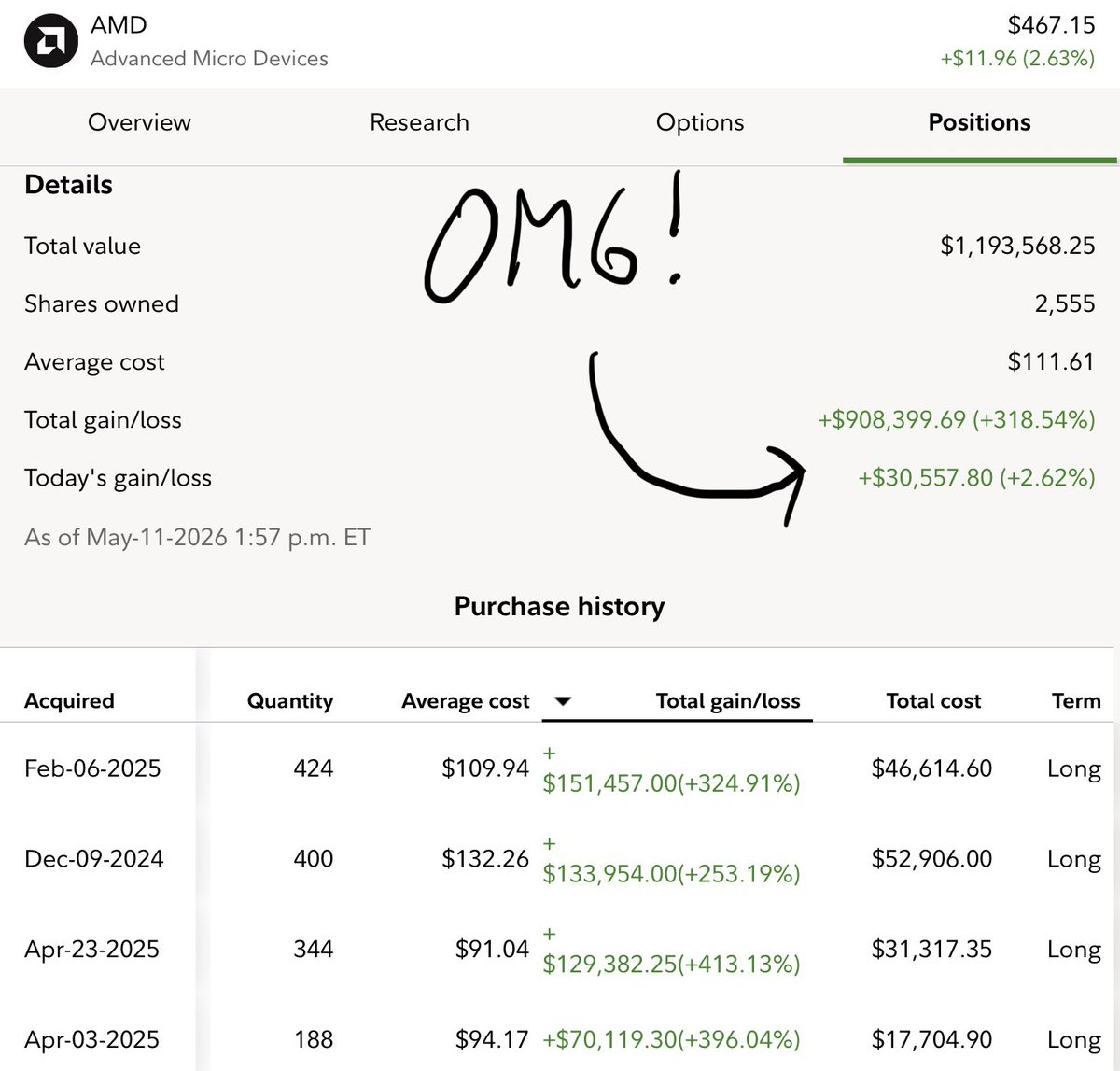
@CarsonTalkMoney I bought 1500 shares last week and regret it now. Should have waited
English
O
15 posts


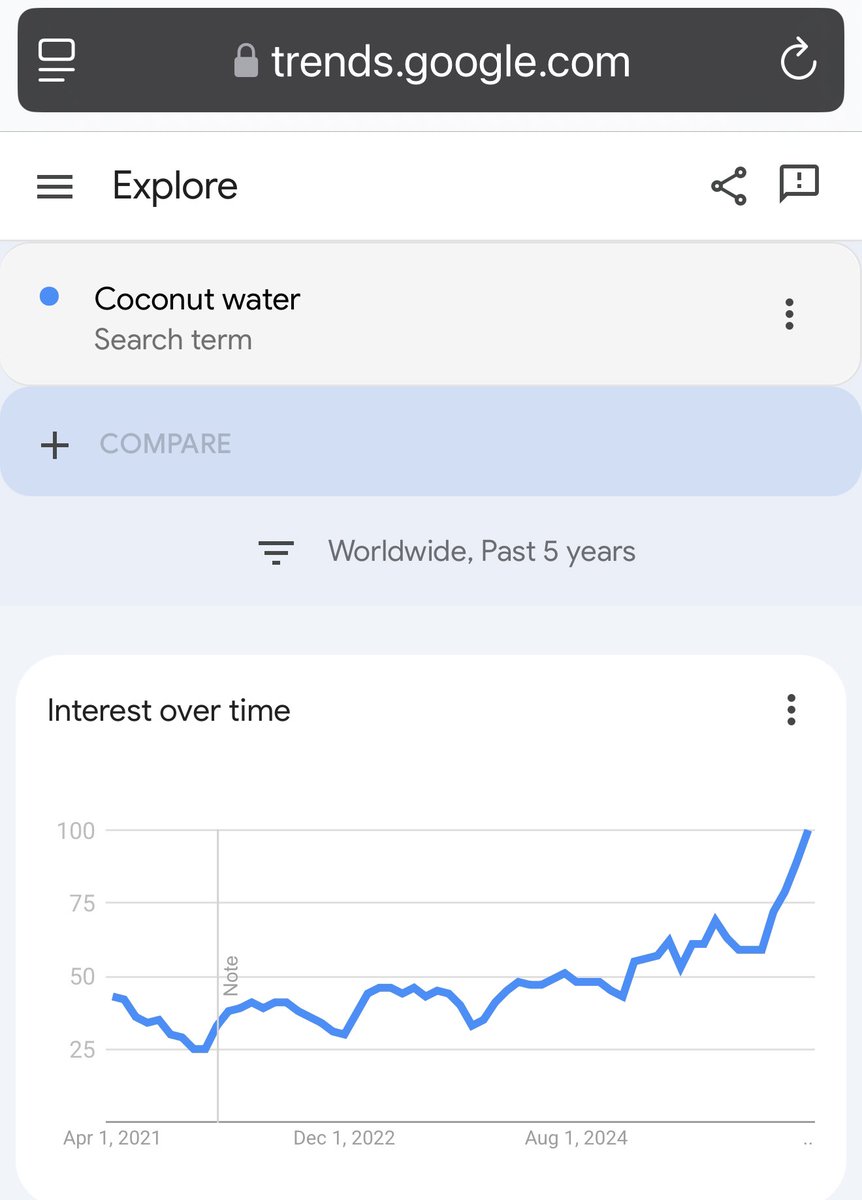
This is what I live for. What social arb is all about. $COCO

$AMD $3,000 is Inevitable Long Term 🧵 The roadmap to $5 Trillion Market Cap is much clearer today than just months ago due to sentiment shift, where I talked extensively for years since 2022/2023. Most subscribers and followers already know How lonely I was writing DDs on AMD in 2023. But the first time I heard Dr. Su "I love being able to bring the best product to the market; I really love to win" 11 years+ ago, I was in! $3,000 is assuming no stock split. The timeline is accelerated much faster as CPU:GPU Ratio shifted from 1:4-8 to 3-5:1 in the near term and 10-20:1 as we get to Autonomous Agents by 2030 or sooner. Read more below. Put your seatbelt on, because it is going to be a long thread. Slap the Like/Repost/Bookmark to please the X Algo. If you want to support me to produce better quality threads, consider subscribe. And yes you will have access to more in-depth analysis. Not Financial Advice! Just well-researched 🧵 I want to make this thread after $MSFT and $AMZN announced the important role for CPUs in this explosive Agentic AI Era. I will link both below and other threads to help you understand this topic. How Dr. Su is prepared for this AMD J-curve moment since 2020-2021 to have the full stack of AI Solutions from CPUs,GPUs, NPU, ROCm open Software, Networking & Interconnects, and Custom Chip. This is important to understand because: ~ $INTC has inferior CPUs than $AMD ~ $AMD Helios Racks are on track to outperform Rubin Racks with much lower TCO,TDP and $ per million tokens on training and inference. ~ $ARM makes inferior custom chips vs $AMD, precisely the AMD Custom chip HBv Series for $MSFT. Dr. Su is getting into Custom Chip for all large customers ~ AMD NPU is the best in the world atm with 0 competition for local/personal LLM on high-end laptops or workstations. ~10 of 10 major social media platforms now run EPYC including Meta, which was historically an Intel-only shop ~ 10 of 10 large SaaS organizations have converted to EPYC ~3× year-over-year public cloud adoption growth by large customers ~AMD's target of 50%+ server CPU market share is achievable by 2027 with Venice and Verano ~ 100% of AMD Helios AI racks (pairing Venice CPUs with Instinct MI455X GPUs) use EPYC as the host CPU, locking in CPU sales tied to AI GPU deployments The two announcements from Amazon and Microsoft underscore a pivotal shift in AI infrastructure: Agentic AI (autonomous, always-on AI systems that reason, plan, execute multi-step tasks, and interact with tools/environments in real time) is dramatically elevating the role of CPUs alongside GPUs. Amazon’s post (April 24, 2026) explicitly states that while GPUs/accelerators excel at parallel training/inference for LLMs, agentic workloads demand sustained, low-latency CPU-native tasks like sequential logic, file management, network calls, code execution, data retrieval, and orchestration across rapid execution cycles. AWS Graviton (ARM-based) is highlighted as purpose-built for this, with Meta deploying tens of millions of Graviton cores for global-scale agentic AI Satya Nadella’s post (April 22, 2026) reinforces this: “Every agent will need its own computer” complete with dedicated enterprise-grade sandboxes, durable state, identity, and governance in Microsoft’s new Foundry hosted agents. This implies massive scaling of per-agent compute instances, far beyond batch inference. This is not hype, it’s a fundamental rebalancing of data center spend. Training remains GPU-heavy, but inference + agentic execution (projected to become the majority of AI workloads) shifts toward CPUs for orchestration, low-latency reasoning, and sustained performance-per-watt at scale. Hyperscalers and enterprises are now optimizing entire stacks for “continuous intelligence,” not just bursty math. The CPU:GPU Ratio is now shifting from 1:4-8 to 3-5:1, a complete change from 2023-2025. Now, that does not mean Training just gonna stop, NO. Training will continue to grow, but the pace of growth will be much slower than Inference. The Legend Larry Ellison $ORCL Chairman said this: “Training AI models is a gigantic multi-trillion-dollar market. It’s hard to conceive of a technology market as large as that one. But if you look closely, you can find one that’s even larger: it’s the market for AI inferencing. Millions of customers are using those AI models to run businesses and governments. In fact, the AI inferencing market will be much, much larger than the AI training market. AI inferencing will be used to run robotic factories, robotic cars, robotic greenhouses, biomolecular simulations for drug design, interpreting medical diagnostic images and laboratory results, automating laboratories, placing bets in financial markets, automating legal processes, automating financial processes, and automating sales processes." “In the end, all this money we’re spending on (AI model) training is going to have to be translated into products that are sold — which is all inferencing. And the inferencing market, again, is much larger than the training market.” “People are running out of inferencing capacity.” 1. Why This Creates the Greatest J-Curve Growth Opportunity for AMD’s Full-Stack Solution AMD is uniquely positioned to capture outsized upside here because it offers the industry’s strongest balanced, open full-stack AI infrastructure high-core x86 CPUs (EPYC), leading inference GPUs (Instinct MI series), ultra-low-latency networking (Pensando), and the open ROCm software stack. Unlike single-vendor or accelerator-only plays, AMD delivers end-to-end optimization for exactly the agentic workloads now exploding: CPU-orchestrated multi-agent systems running alongside GPUs for hybrid inference/MoE (Mixture of Experts) tasks ~CPUs become the control plane/orchestration engine: Agentic AI needs massive core concurrency for thousands of parallel agents, each with its own “computer” (sandboxed state, tools, reasoning loops). AMD EPYC already leads in core density, thread-per-watt, and x86 compatibility (critical for the vast Python/enterprise software ecosystem that ARM Graviton can’t always match without porting friction). AMD’s own analysis positions EPYC as ideal for agentic control planes, data preprocessing, and keeping GPUs fully utilized. ~Full-stack synergy drives TCO and performance leadership: AMD’s AI racks integrate EPYC host CPUs directly with Instinct GPUs + ROCm, enabling seamless orchestration, lower latency inter-core communication, and superior perf/system-watt. Partnerships like Nutanix further extend this into enterprise/hybrid clouds for agentic apps. This is exactly what hyperscalers and enterprises need as they move from GPU-only experiments to production agentic scale. So what is your point Mike? When do we get to $5 Trillion? The short answer is $50 B quarterly Revenue with 20-30% Cagr and Operating Margin in the 25%+. The market is only repricing @AMD for 10% of its long term potential. There are just so much room for hypergrowth. $50 B revenue sounds huge, but we may get there by 2027-2028 due to current explosive EPYC demand, projected to be 15-20m units. 2. EPYC Venice (H2 2026)is positioned as the World’s Best Server CPU for the Agentic Era AMD’s 6th-gen EPYC “Venice” (Zen 6 architecture, TSMC 2nm) is sampling now and launches in 2026 alongside Instinct MI400 GPUs. Key specs and advantages: ~Up to 256 cores (33%+ increase over current Turin’s 192-core max) with radical package redesign for higher thread density (~1.3x) and bandwidth. ~Up to 70% overall performance uplift (and strong efficiency gains) vs. 5th-gen Turin, with massive memory bandwidth improvements (up to 1.6 TB/s via 16-channel DDR5/MRDIMM). ~Optimized for sustained, high-concurrency workloads, perfect for hosting “tens of millions” of agent sandboxes or orchestrating complex multi-step agent workflows with fast core-to-core communication. Venice will power AMD’s next-gen Helios AI racks and deliver leadership TCO in exactly the always-on, reasoning-heavy environments Amazon and Microsoft are describing. It extends AMD’s current EPYC dominance (world-record benchmarks in enterprise, HPC, AI end-to-end) into the agentic wave, while remaining fully x86-compatible for drop-in deployment. And most importantly, $TSM has the capacity to expand AMD EPYC supply to service a large % of this demand, per Dr. Su statement from Morgan Stanley Conference. 3. While everyone is struggling, $AMD is already working on the next beast EPYC, Verano 2027. A massive Step Forward for EPYC Dense Rack optimization CPU for AMD’s 2027 AI rack-scale platforms (alongside Instinct MI500 GPUs). Highlights: ~First EPYC support for LPDDR5X SOCAMM2 memory ,delivering major perf/system-watt gains tailored for AI racks. ~Doubles rack density/scalability vs. prior generations, with 144+ MI500 GPUs per rack possible. ~Engineered for the exact agentic + MoE workloads: superior orchestration, energy efficiency at global scale, and tight GPU integration via ROCm. This is the “big step forward” turning Venice’s raw power into rack-level, hyperscale efficiency for the always-on agentic internet. AMD’s roadmap (Venice 2026 → Verano 2027) aligns perfectly with the multi-year buildout of agentic infrastructure. Conclusion: Dr. Lisa Su’s long-term vision has been proven brilliantly correct. Years before the Agentic AI inflection, she repeatedly emphasized that the real scaling of AI would not be GPU-only; it would require powerful, high-core CPUs as the always-on control plane for orchestration, reasoning loops, tool use, and sustained low-latency execution the exact workloads now exploding in production. While the industry chased pure accelerator hype, Dr. Su doubled down on AMD’s full-stack advantage: EPYC as the world’s leading x86 server CPU, tightly integrated with Instinct GPUs and the open ROCm ecosystem. Amazon’s April 24 announcement and Satya Nadella’s April 22 declaration (“Every agent will need its own computer”) are the ultimate market validation of that vision. Both hyperscalers are now publicly confirming what Dr. Su has been building toward: Agentic AI fundamentally shifts infrastructure spend toward CPU-native tasks at massive scale sequential logic, state management, multi-step orchestration, and real-time tool calling, precisely the strengths of high-core EPYC platforms. The timing could not be more perfect. EPYC Venice (2026) arrives as the undisputed performance and efficiency leader for these workloads, while Verano (2027) delivers the rack-scale leap optimized for exactly the always-on, multi-agent systems Amazon and Microsoft are racing to deploy. This is not incremental upside for AMD. It is the J-curve moment Dr. Su has engineered for years: the greatest multi-year growth acceleration in the company’s data-center history toward $5 Trillion Market Cap, driven by the very CPU-centric, full-stack architecture she insisted would define the next era of AI. The hyperscalers have now spoken. Dr. Su was right. Not Financial Advice!


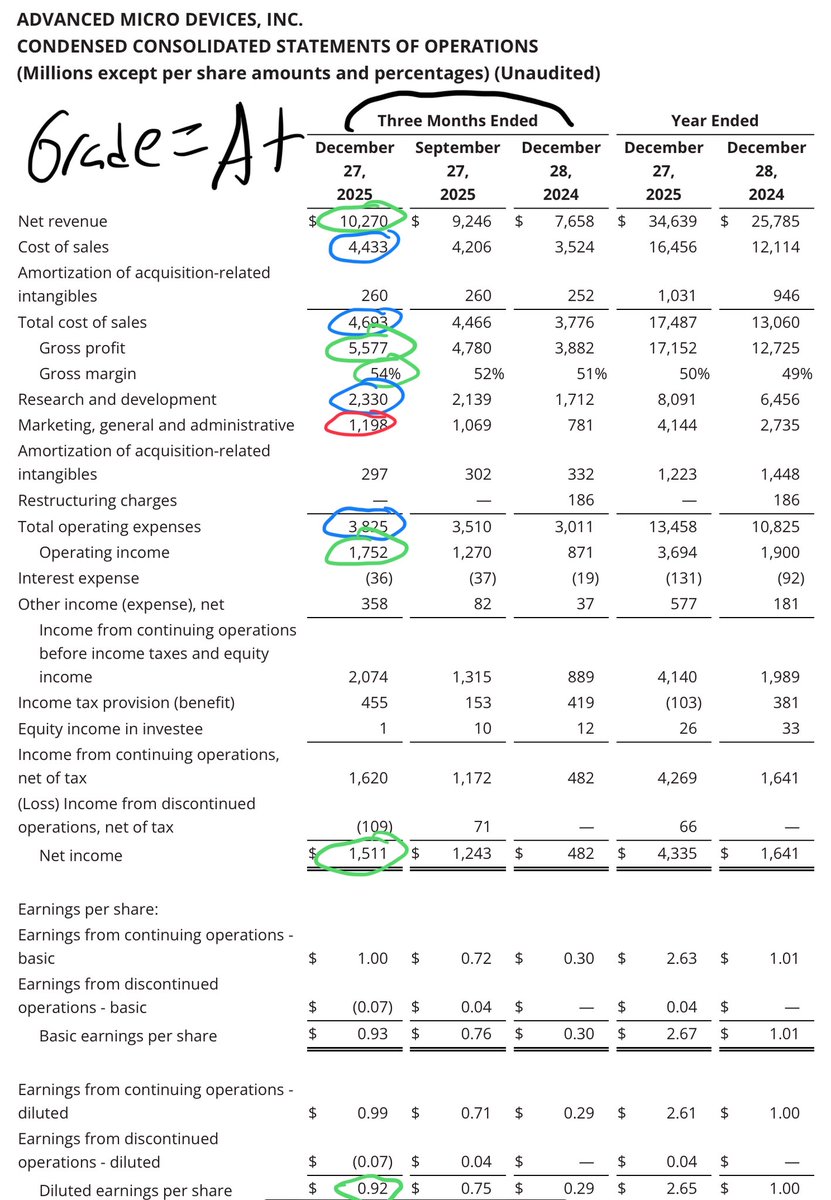
$AMD is on track to $70-$100B FY2026 🧵 Fundamental is J-Curving! Before H2 26🚀🚀🚀 Q4 2025 ER Revenue $10.27B vs $9.62 est EPS $1.53 vs $1.32 est Q1 2026 Guidance $9.8B+$300m vs $9.6B est TRIPLE BEAT 👑 We all know Dr. @LisaSu been giving conservative guidance since 2014, this isnt new. Q4 2025 was guided $9.5B and revenue hit $10.27B I'm still keeping my FY 2026 projection as everything is on schedule. And we area also hearing 1GW ramp from @Cisco @HUMAIN. More demand, probably higher than @OpenAI from $META $MSFT. $AMZN Earning is coming, so I will update.The language changed completely on Helios Rack. Training and Inference. So, very excited for H2 2026,which is only 4 months away! 2026 Base: AI GPUs: $35-$50B EPYC Data Center: $15B-$17B Client Segment: $12-$13B Gaming: $6B Embedded: $4B-$5B Total Revenue $70-$100B Non-GAAP net income $18B-$25B Non-GAAP EPS $10.97-$15.40 H1 2026 is likely to do $24-$27B of this $70-$100B. The range is wide because of demand, supply chain, and other variables. 2027 2028 should be easier to project. It is important to zoom out a bit to understand the J-curve or inflection point: Most notable change is Operating Income, Net Income and FCF generation. Cash also grew 46% from just 1 quarter Q3 2025= $7.2B> $10.5B. This shows: ~Pricing Power ~Massive recognition for the work at AMD team from Hyperscalers, especially publically recognized on $MSFT $META earning call ~Demand for AI compute is still MASSIVE when you comp to supply ~Data center is now 50% and soon grow to probably 60-70% of overall Revenue. ~H2 2026 Helios Rack is on schedule, no delay fake new. And Large customers are testing Helios Racks, and everything is good so far confirmed by Dr. Su. ~HBM is secured for years from long time partners and expanding for more years to come to service AI demand! ~OpEx is growing much slower than Revenue=> Margin Expansion like I called it during 2025. @AMD Revenue and Profitability Growth are accelerating way before H2 2026, the major inflection I talked about for months and years now. It doesn't matter what Sexist analysts said, because most of them were wrong on FY2025, and they will also be wrong to project $0-$5B on MI355X and Helios Racks for FY2026. AMD delivered a strong close to fiscal 2025, posting record quarterly revenue and earnings driven by robust demand in its data center and client segments. The results underscore an acceleration in revenue and profitability well ahead of the anticipated H2 2026 launch of the Helios Rack AI GPU system. This momentum stems primarily from existing product lines like EPYC CPUs and MI355X GPUs, which are capitalizing on the ongoing AI infrastructure buildout and broader computing demand. AMD's Q4 results highlight a company firing on all cylinders, with data center-led growth accelerating revenue and margins independently of Helios. The H2 2026 launch should amplify this trajectory, positioning AMD as a key player in AI infrastructure. While short-term volatility persists, the fundamentals support continued outperformance. Lots of noises coming into Semi space, especially when the market is this emotional, and Funds overpaying/roating out of Tech. Continuation from September 2025 when I warned people to get rid of margin. It is important to pay attention to fundamental instead of daily price action. @AMD is the biggest lagger in the large cap, and will soon join the top largest market cap in the world. Q3 2026 is expected to report in November 2026 or 9 months from now. Alright, that is it. Good quarter, beat all my estimate. Not Financial Advice!